 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Vision Transformers: the Diffusion Steering Lens
Apr 18, 2025



Logit Lens is a widely adopted method for mechanistic interpretability of transformer-based language models, enabling the analysis of how internal representations evolve across layers by projecting them into the output vocabulary space. Although applying Logit Lens to Vision Transformers (ViTs) is technically straightforward, its direct use faces limitations in capturing the richness of visual representations. Building on the work of Toker et al. (2024)~\cite{Toker2024-ve}, who introduced Diffusion Lens to visualize intermediate representations in the text encoders of text-to-image diffusion models, we demonstrate that while Diffusion Lens can effectively visualize residual stream representations in image encoders, it fails to capture the direct contributions of individual submodules. To overcome this limitation, we propose \textbf{Diffusion Steering Lens} (DSL), a novel, training-free approach that steers submodule outputs and patches subsequent indirect contributions. We validate our method through interventional studies, showing that DSL provides an intuitive and reliable interpretation of the internal processing in ViTs.
ProcBench: Benchmark for Multi-Step Reasoning and Following Procedure
Oct 04, 2024


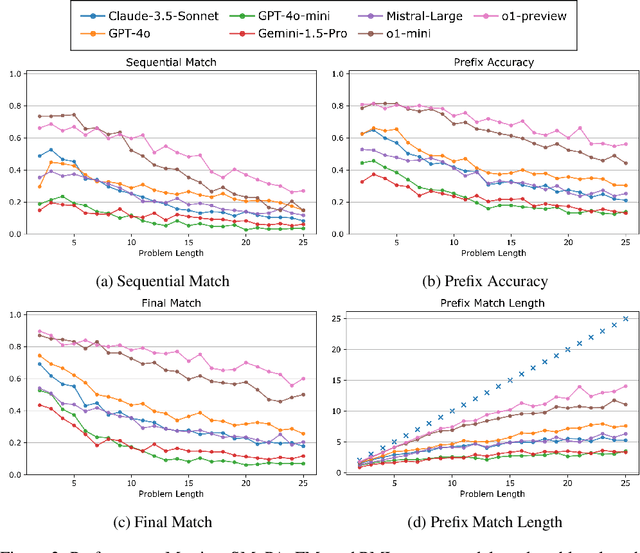
Reasoning is central to a wide range of intellectual activities, and while the capabilities of large language models (LLMs) continue to advance, their performance in reasoning tasks remains limited. The processes and mechanisms underlying reasoning are not yet fully understood, but key elements include path exploration, selection of relevant knowledge, and multi-step inference. Problems are solved through the synthesis of these components. In this paper, we propose a benchmark that focuses on a specific aspect of reasoning ability: the direct evaluation of multi-step inference. To this end, we design a special reasoning task where multi-step inference is specifically focused by largely eliminating path exploration and implicit knowledge utilization. Our dataset comprises pairs of explicit instructions and corresponding questions, where the procedures necessary for solving the questions are entirely detailed within the instructions. This setup allows models to solve problems solely by following the provided directives. By constructing problems that require varying numbers of steps to solve and evaluating responses at each step, we enable a thorough assessment of state-of-the-art LLMs' ability to follow instructions. To ensure the robustness of our evaluation, we include multiple distinct tasks. Furthermore, by comparing accuracy across tasks, utilizing step-aware metrics, and applying separately defined measures of complexity, we conduct experiments that offer insights into the capabilities and limitations of LLMs in reasoning tasks. Our findings have significant implications for the development of LLMs and highlight areas for future research in advancing their reasoning abilities. Our dataset is available at \url{https://huggingface.co/datasets/ifujisawa/procbench} and code at \url{https://github.com/ifujisawa/proc-bench}.
Logical Tasks for Measuring Extrapolation and Rule Comprehension
Nov 14, 2022



Logical reasoning is essential in a variety of human activities. A representative example of a logical task is mathematics. Recent large-scale models trained on large datasets have been successful in various fields, but their reasoning ability in arithmetic tasks is limited, which we reproduce experimentally. Here, we recast this limitation as not unique to mathematics but common to tasks that require logical operations. We then propose a new set of tasks, termed logical tasks, which will be the next challenge to address. This higher point of view helps the development of inductive biases that have broad impact beyond the solution of individual tasks. We define and characterize logical tasks and discuss system requirements for their solution. Furthermore, we discuss the relevance of logical tasks to concepts such as extrapolation, explainability, and inductive bias. Finally, we provide directions for solving logical tasks.