 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting systems as solving POMDPs: a step towards a formal understanding of agency
Sep 04, 2022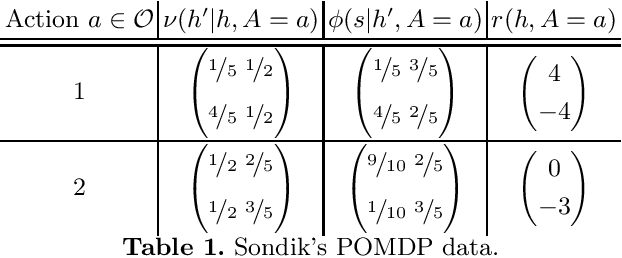
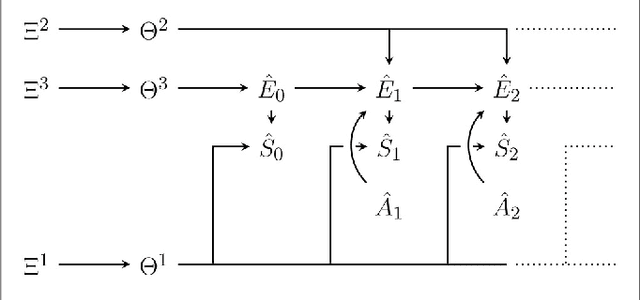
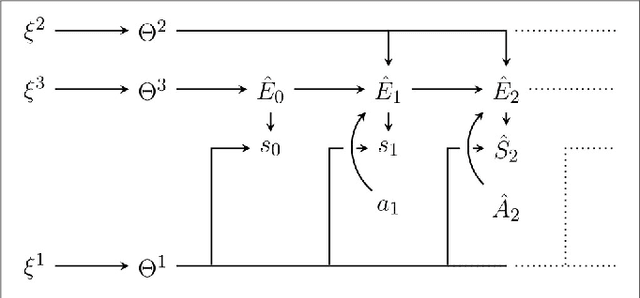
Under what circumstances can a system be said to have beliefs and goals, and how do such agency-related features relate to its physical state? Recent work has proposed a notion of interpretation map, a function that maps the state of a system to a probability distribution representing its beliefs about an external world. Such a map is not completely arbitrary, as the beliefs it attributes to the system must evolve over time in a manner that is consistent with Bayes' theorem, and consequently the dynamics of a system constrain its possible interpretations. Here we build on this approach, proposing a notion of interpretation not just in terms of beliefs but in terms of goals and actions. To do this we make use of the existing theory of partially observable Markov processes (POMDPs): we say that a system can be interpreted as a solution to a POMDP if it not only admits an interpretation map describing its beliefs about the hidden state of a POMDP but also takes actions that are optimal according to its belief state. An agent is then a system together with an interpretation of this system as a POMDP solution. Although POMDPs are not the only possible formulation of what it means to have a goal, this nevertheless represents a step towards a more general formal definition of what it means for a system to be an agent.
Interpreting Dynamical Systems as Bayesian Reasoners
Dec 27, 2021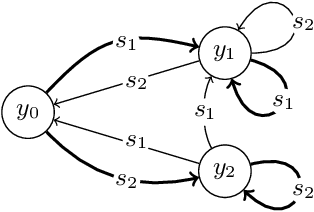
A central concept in active inference is that the internal states of a physical system parametrise probability measures over states of the external world. These can be seen as an agent's beliefs, expressed as a Bayesian prior or posterior. Here we begin the development of a general theory that would tell us when it is appropriate to interpret states as representing beliefs in this way. We focus on the case in which a system can be interpreted as performing either Bayesian filtering or Bayesian inference. We provide formal definitions of what it means for such an interpretation to exist, using techniques from category theory.
Experimental Evidence that Empowerment May Drive Exploration in Sparse-Reward Environments
Jul 14, 2021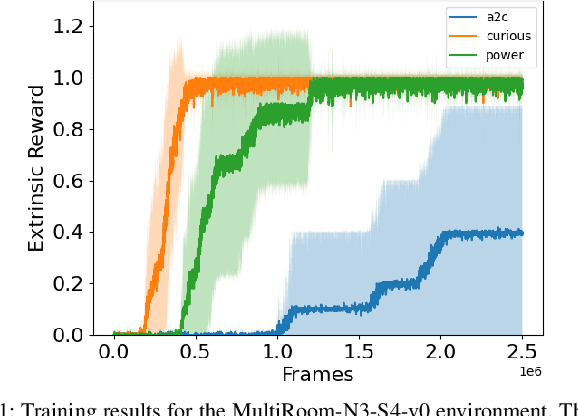
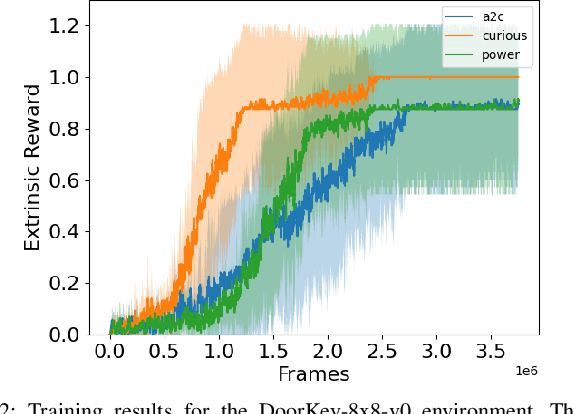
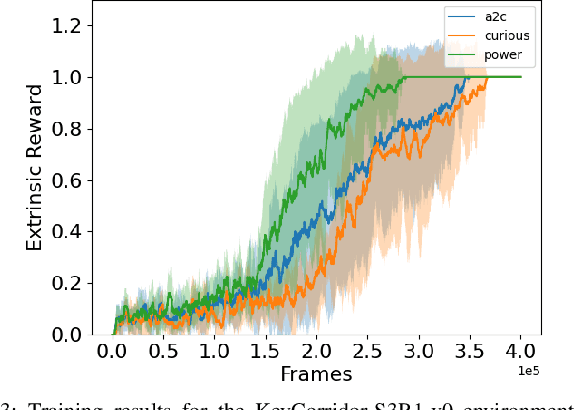

Reinforcement Learning (RL) is known to be often unsuccessful in environments with sparse extrinsic rewards. A possible countermeasure is to endow RL agents with an intrinsic reward function, or 'intrinsic motivation', which rewards the agent based on certain features of the current sensor state. An intrinsic reward function based on the principle of empowerment assigns rewards proportional to the amount of control the agent has over its own sensors. We implemented a variation on a recently proposed intrinsically motivated agent, which we refer to as the 'curious' agent, and an empowerment-inspired agent. The former leverages sensor state encoding with a variational autoencoder, while the latter predicts the next sensor state via a variational information bottleneck. We compared the performance of both agents to that of an advantage actor-critic baseline in four sparse reward grid worlds. Both the empowerment agent and its curious competitor seem to benefit to similar extents from their intrinsic rewards. This provides some experimental support to the conjecture that empowerment can be used to drive exploration.
Non-trivial informational closure of a Bayesian hyperparameter
Oct 05, 2020
We investigate the non-trivial informational closure (NTIC) of a Bayesian hyperparameter inferring the underlying distribution of an identically and independently distributed finite random variable. For this we embed both the Bayesian hyper-parameter updating process and the random data process into a Markov chain. The original publication by Bertschinger et al. (2006) mentioned that NTIC may be able to capture an abstract notion of modeling that is agnostic to the specific internal structure of and existence of explicit representations within the modeling process. The Bayesian hyperparameter is of interest since it has a well defined interpretation as a model of the data process and at the same time its dynamics can be specified without reference to this interpretation. On the one hand we show explicitly that the NTIC of the hyperparameter increases indefinitely over time. On the other hand we attempt to establish a connection between a quantity that is a feature of the interpretation of the hyperparameter as a model, namely the information gain, and the one-step pointwise NTIC which is a quantity that does not depend on this interpretation. We find that in general we cannot use the one-step pointwise NTIC as an indicator for information gain. We hope this exploratory work can lead to further rigorous studies of the relation between NTIC and modeling.
Causal blankets: Theory and algorithmic framework
Sep 29, 2020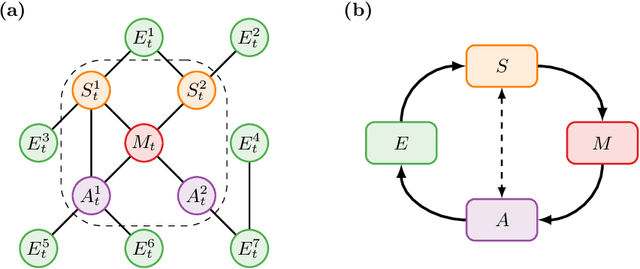
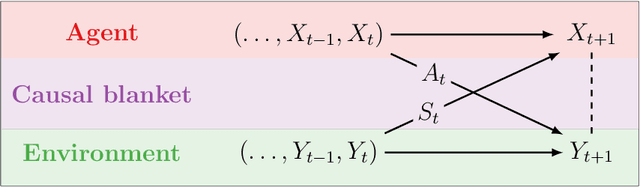
We introduce a novel framework to identify perception-action loops (PALOs) directly from data based on the principles of computational mechanics. Our approach is based on the notion of causal blanket, which captures sensory and active variables as dynamical sufficient statistics -- i.e. as the "differences that make a difference." Moreover, our theory provides a broadly applicable procedure to construct PALOs that requires neither a steady-state nor Markovian dynamics. Using our theory, we show that every bipartite stochastic process has a causal blanket, but the extent to which this leads to an effective PALO formulation varies depending on the integrated information of the bipartition.
Geometry of Friston's active inference
Nov 20, 2018
We reconstruct Karl Friston's active inference and give a geometrical interpretation of it.
Expanding the Active Inference Landscape: More Intrinsic Motivations in the Perception-Action Loop
Jun 21, 2018
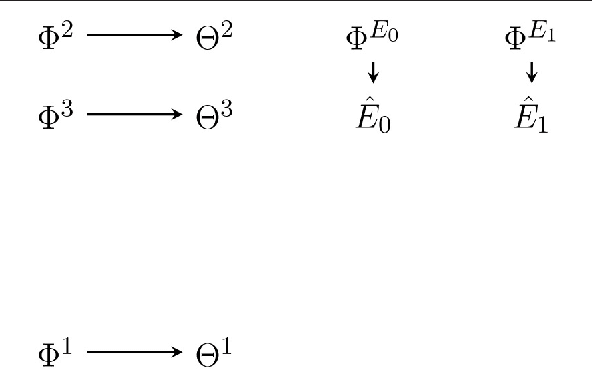
Active inference is an ambitious theory that treats perception, inference and action selection of autonomous agents under the heading of a single principle. It suggests biologically plausible explanations for many cognitive phenomena, including consciousness. In active inference, action selection is driven by an objective function that evaluates possible future actions with respect to current, inferred beliefs about the world. Active inference at its core is independent from extrinsic rewards, resulting in a high level of robustness across e.g.\ different environments or agent morphologies. In the literature, paradigms that share this independence have been summarised under the notion of intrinsic motivations. In general and in contrast to active inference, these models of motivation come without a commitment to particular inference and action selection mechanisms. In this article, we study if the inference and action selection machinery of active inference can also be used by alternatives to the originally included intrinsic motivation. The perception-action loop explicitly relates inference and action selection to the environment and agent memory, and is consequently used as foundation for our analysis. We reconstruct the active inference approach, locate the original formulation within, and show how alternative intrinsic motivations can be used while keeping many of the original features intact. Furthermore, we illustrate the connection to universal reinforcement learning by means of our formalism. Active inference research may profit from comparisons of the dynamics induced by alternative intrinsic motivations. Research on intrinsic motivations may profit from an additional way to implement intrinsically motivated agents that also share the biological plausibility of active inference.
Being curious about the answers to questions: novelty search with learned attention
Jun 01, 2018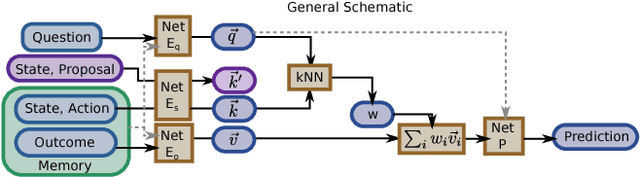
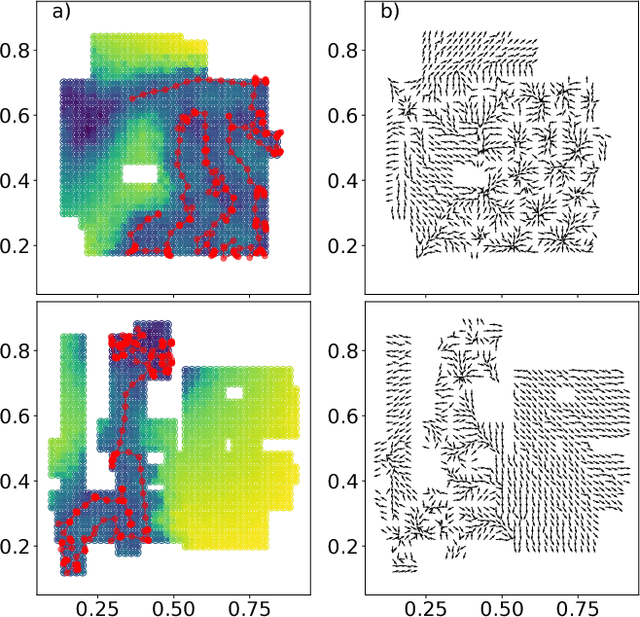
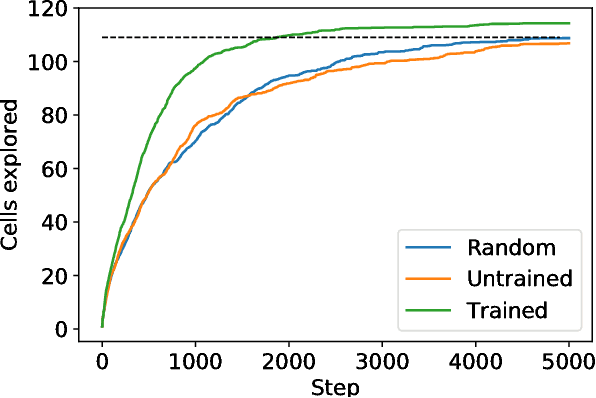
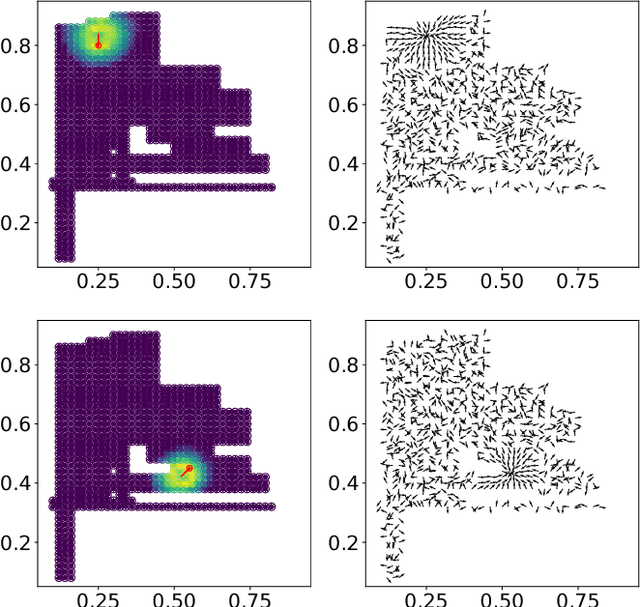
We investigate the use of attentional neural network layers in order to learn a `behavior characterization' which can be used to drive novelty search and curiosity-based policies. The space is structured towards answering a particular distribution of questions, which are used in a supervised way to train the attentional neural network. We find that in a 2d exploration task, the structure of the space successfully encodes local sensory-motor contingencies such that even a greedy local `do the most novel action' policy with no reinforcement learning or evolution can explore the space quickly. We also apply this to a high/low number guessing game task, and find that guessing according to the learned attention profile performs active inference and can discover the correct number more quickly than an exact but passive approach.
Learning body-affordances to simplify action spaces
Aug 15, 2017
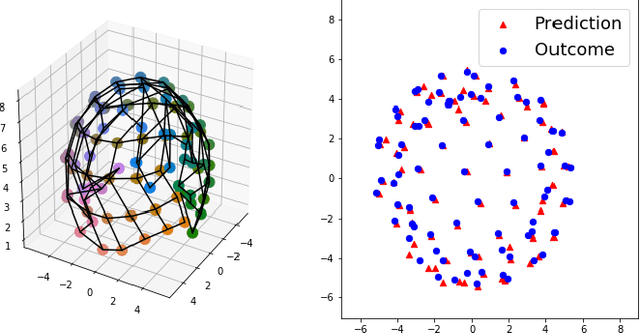
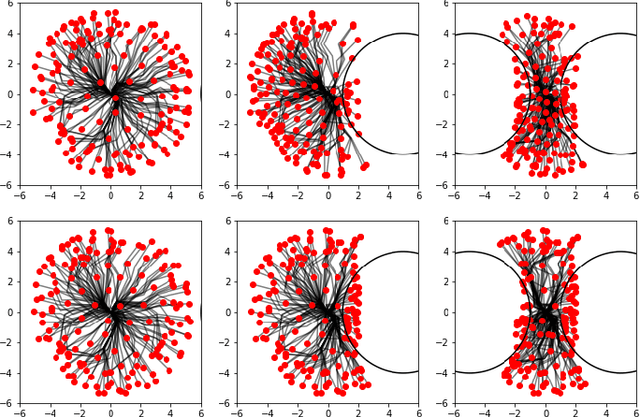
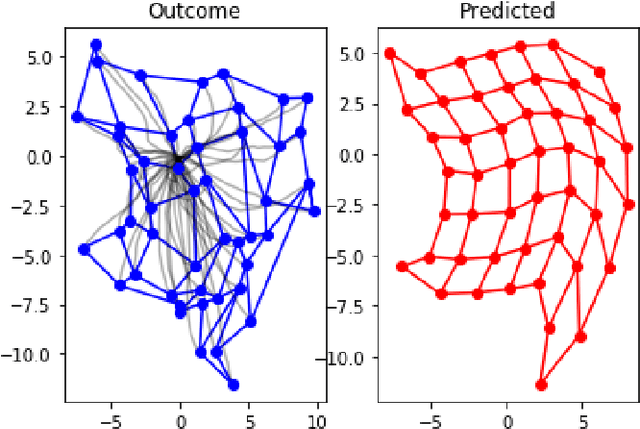
Controlling embodied agents with many actuated degrees of freedom is a challenging task. We propose a method that can discover and interpolate between context dependent high-level actions or body-affordances. These provide an abstract, low-dimensional interface indexing high-dimensional and time- extended action policies. Our method is related to recent ap- proaches in the machine learning literature but is conceptually simpler and easier to implement. More specifically our method requires the choice of a n-dimensional target sensor space that is endowed with a distance metric. The method then learns an also n-dimensional embedding of possibly reactive body-affordances that spread as far as possible throughout the target sensor space.
Action and perception for spatiotemporal patterns
Jun 12, 2017
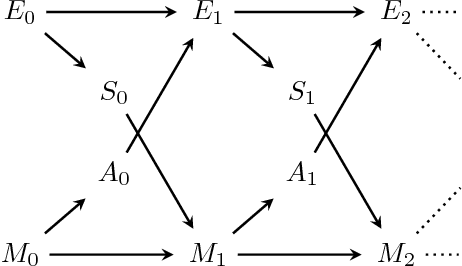
This is a contribution to the formalization of the concept of agents in multivariate Markov chains. Agents are commonly defined as entities that act, perceive, and are goal-directed. In a multivariate Markov chain (e.g. a cellular automaton) the transition matrix completely determines the dynamics. This seems to contradict the possibility of acting entities within such a system. Here we present definitions of actions and perceptions within multivariate Markov chains based on entity-sets. Entity-sets represent a largely independent choice of a set of spatiotemporal patterns that are considered as all the entities within the Markov chain. For example, the entity-set can be chosen according to operational closure conditions or complete specific integration. Importantly, the perception-action loop also induces an entity-set and is a multivariate Markov chain. We then show that our definition of actions leads to non-heteronomy and that of perceptions specialize to the usual concept of perception in the perception-action loop.
* 8 pages, 2 figures, accepted at the European Conference on Artificial Life 2017, Lyon, France