 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary rates of information gain and decay in fluctuating environments
Apr 07, 2021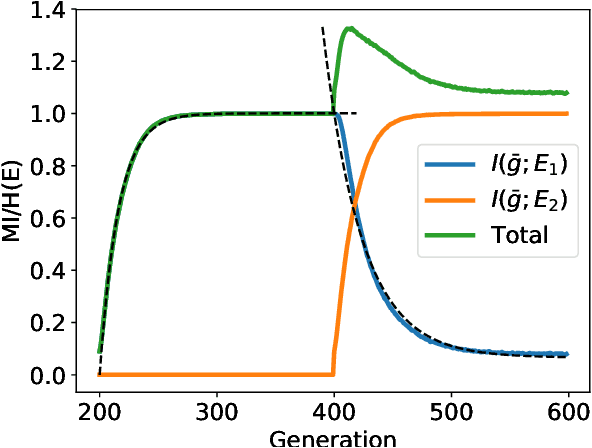

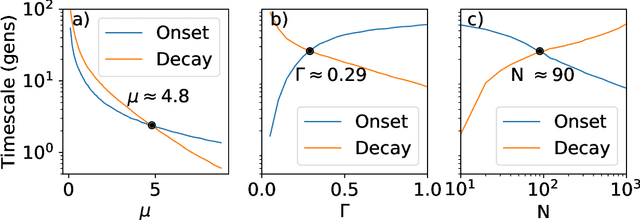
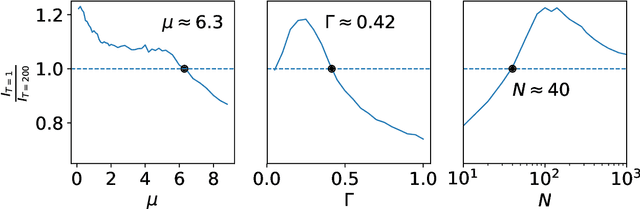
In this paper, we wish to investigate the dynamics of information transfer in evolutionary dynamics. We use information theoretic tools to track how much information an evolving population has obtained and managed to retain about different environments that it is exposed to. By understanding the dynamics of information gain and loss in a static environment, we predict how that same evolutionary system would behave when the environment is fluctuating. Specifically, we anticipate a cross-over between the regime in which fluctuations improve the ability of the evolutionary system to capture environmental information and the regime in which the fluctuations inhibit it, governed by a cross-over in the timescales of information gain and decay.
Bootstrapping of memetic from genetic evolution via inter-agent selection pressures
Apr 07, 2021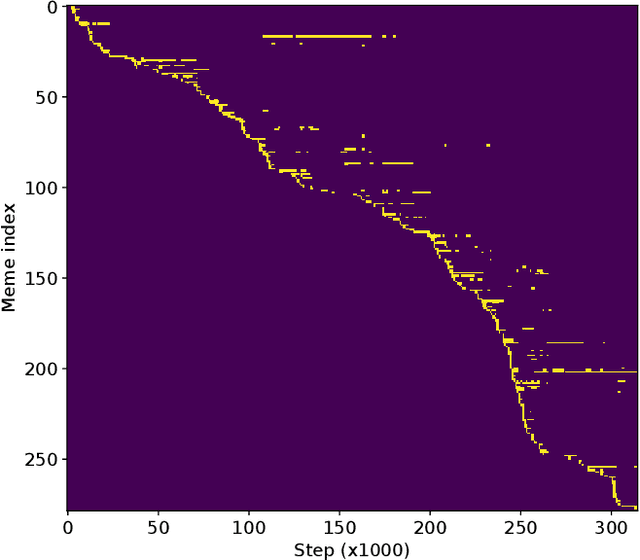

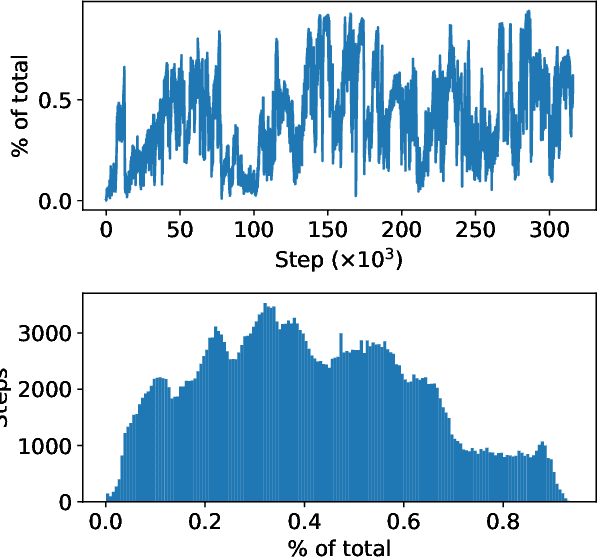
We create an artificial system of agents (attention-based neural networks) which selectively exchange messages with each-other in order to study the emergence of memetic evolution and how memetic evolutionary pressures interact with genetic evolution of the network weights. We observe that the ability of agents to exert selection pressures on each-other is essential for memetic evolution to bootstrap itself into a state which has both high-fidelity replication of memes, as well as continuing production of new memes over time. However, in this system there is very little interaction between this memetic 'ecology' and underlying tasks driving individual fitness - the emergent meme layer appears to be neither helpful nor harmful to agents' ability to learn to solve tasks. Sourcecode for these experiments is available at https://github.com/GoodAI/memes
BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)
Dec 03, 2019![Figure 1 for BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F2e8dd183207e83abdc653bc126189032d6b7ab5e%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F2e8dd183207e83abdc653bc126189032d6b7ab5e%2F1-Figure2-1.png&w=640&q=75)
![Figure 3 for BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F2e8dd183207e83abdc653bc126189032d6b7ab5e%2F5-Figure6-1.png&w=640&q=75)
![Figure 4 for BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F2e8dd183207e83abdc653bc126189032d6b7ab5e%2F5-Figure7-1.png&w=640&q=75)
In this work, we propose a novel memory-based multi-agent meta-learning architecture and learning procedure that allows for learning of a shared communication policy that enables the emergence of rapid adaptation to new and unseen environments by learning to learn learning algorithms through communication. Behavior, adaptation and learning to adapt emerges from the interactions of homogeneous experts inside a single agent. The proposed architecture should allow for generalization beyond the level seen in existing methods, in part due to the use of a single policy shared by all experts within the agent as well as the inherent modularity of 'Badger'.
Deep learning on butterfly phenotypes tests evolution's oldest mathematical model
Aug 15, 2019



Traditional anatomical analyses captured only a fraction of real phenomic information. Here, we apply deep learning to quantify total phenotypic similarity across 2468 butterfly photographs, covering 38 subspecies from the polymorphic mimicry complex of $\textit{Heliconius erato}$ and $\textit{Heliconius melpomene}$. Euclidean phenotypic distances, calculated using a deep convolutional triplet network, demonstrate significant convergence between interspecies co-mimics. This quantitatively validates a key prediction of M\"ullerian mimicry theory, evolutionary biology's oldest mathematical model. Phenotypic neighbor-joining trees are significantly correlated with wing pattern gene phylogenies, demonstrating objective, phylogenetically informative phenome capture. Comparative analyses indicate frequency-dependent, mutual convergence with coevolutionary exchange of wing pattern features. Therefore, phenotypic analysis supports reciprocal coevolution, predicted by classical mimicry theory but since disputed, and reveals mutual convergence as an intrinsic generator for the surprising diversity of M\"ullerian mimicry. This demonstrates that deep learning can generate phenomic spatial embeddings which enable quantitative tests of evolutionary hypotheses previously only testable subjectively.
* Manuscript and combined supplementary information
Generating the support with extreme value losses
Feb 08, 2019



When optimizing against the mean loss over a distribution of predictions in the context of a regression task, then even if there is a distribution of targets the optimal prediction distribution is always a delta function at a single value. Methods of constructing generative models need to overcome this tendency. We consider a simple method of summarizing the prediction error, such that the optimal strategy corresponds to outputting a distribution of predictions with a support that matches the support of the distribution of targets --- optimizing against the minimal value of the loss given a set of samples from the prediction distribution, rather than the mean. We show that models trained against this loss learn to capture the support of the target distribution and, when combined with an auxiliary classifier-like prediction task, can be projected via rejection sampling to reproduce the full distribution of targets. The resulting method works well compared to other generative modeling approaches particularly in low dimensional spaces with highly non-trivial distributions, due to mode collapse solutions being globally suboptimal with respect to the extreme value loss. However, the method is less suited to high-dimensional spaces such as images due to the scaling of the number of samples needed in order to accurately estimate the extreme value loss when the dimension of the data manifold becomes large.
On the potential for open-endedness in neural networks
Dec 12, 2018Natural evolution gives the impression of leading to an open-ended process of increasing diversity and complexity. If our goal is to produce such open-endedness artificially, this suggests an approach driven by evolutionary metaphor. On the other hand, techniques from machine learning and artificial intelligence are often considered too narrow to provide the sort of exploratory dynamics associated with evolution. In this paper, we hope to bridge that gap by reviewing common barriers to open-endedness in the evolution-inspired approach and how they are dealt with in the evolutionary case - collapse of diversity, saturation of complexity, and failure to form new kinds of individuality. We then show how these problems map onto similar issues in the machine learning approach, and discuss how the same insights and solutions which alleviated those barriers in evolutionary approaches can be ported over. At the same time, the form these issues take in the machine learning formulation suggests new ways to analyze and resolve barriers to open-endedness. Ultimately, we hope to inspire researchers to be able to interchangeably use evolutionary and gradient-descent-based machine learning methods to approach the design and creation of open-ended systems.
Being curious about the answers to questions: novelty search with learned attention
Jun 01, 2018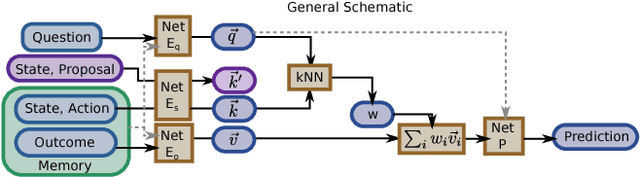
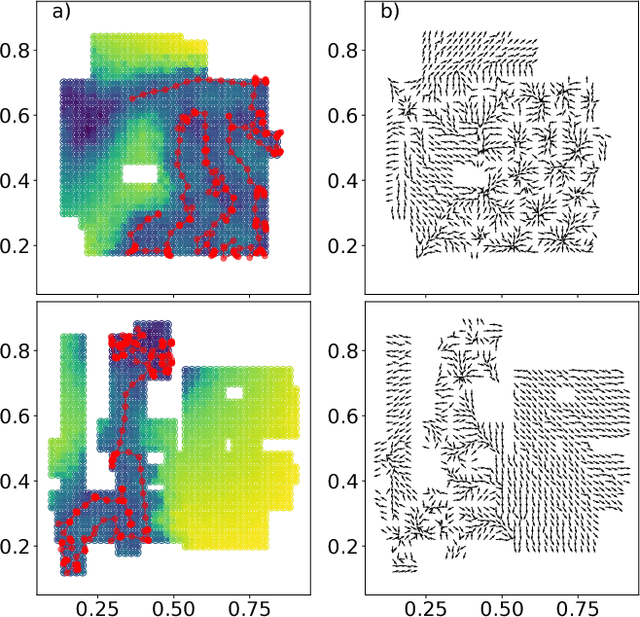
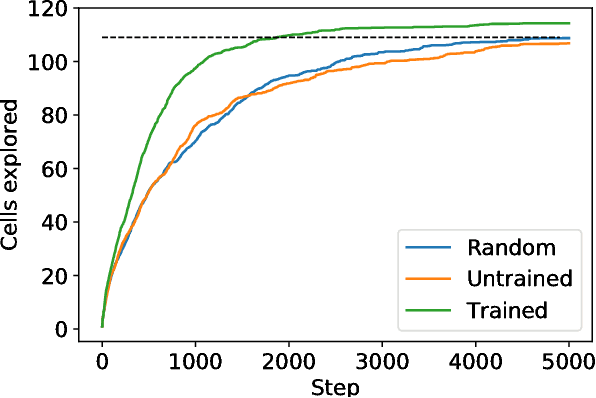
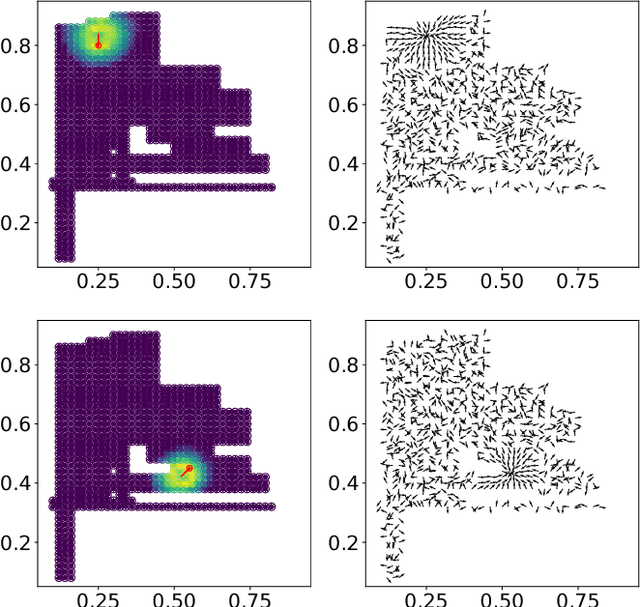
We investigate the use of attentional neural network layers in order to learn a `behavior characterization' which can be used to drive novelty search and curiosity-based policies. The space is structured towards answering a particular distribution of questions, which are used in a supervised way to train the attentional neural network. We find that in a 2d exploration task, the structure of the space successfully encodes local sensory-motor contingencies such that even a greedy local `do the most novel action' policy with no reinforcement learning or evolution can explore the space quickly. We also apply this to a high/low number guessing game task, and find that guessing according to the learned attention profile performs active inference and can discover the correct number more quickly than an exact but passive approach.
Learning to generate classifiers
Mar 30, 2018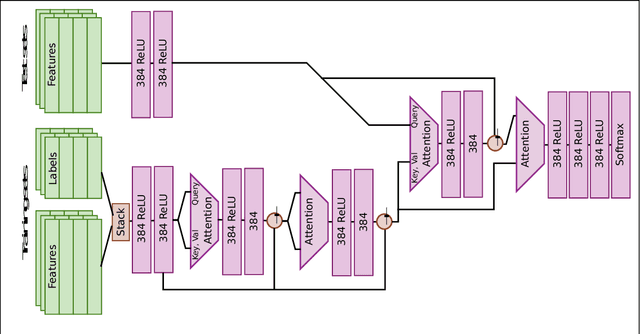
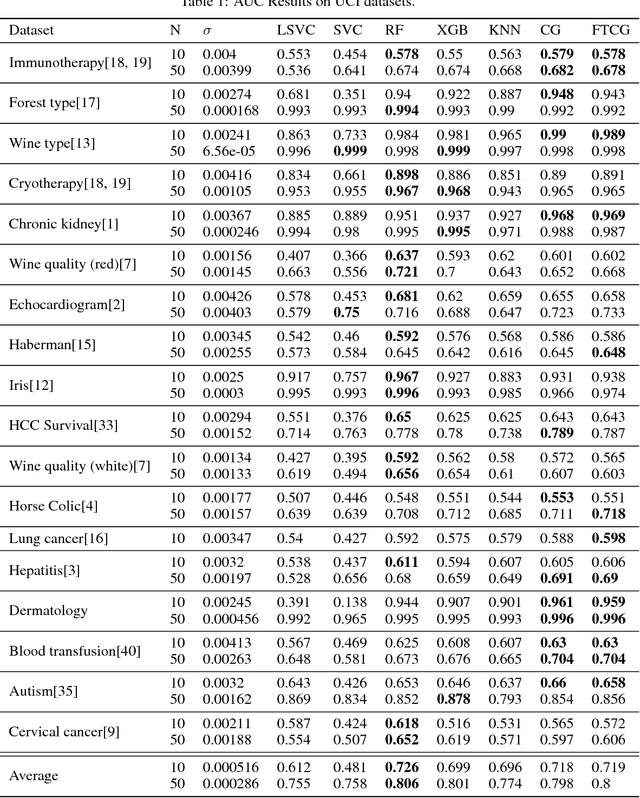

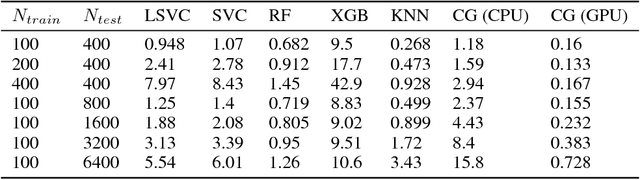
We train a network to generate mappings between training sets and classification policies (a 'classifier generator') by conditioning on the entire training set via an attentional mechanism. The network is directly optimized for test set performance on an training set of related tasks, which is then transferred to unseen 'test' tasks. We use this to optimize for performance in the low-data and unsupervised learning regimes, and obtain significantly better performance in the 10-50 datapoint regime than support vector classifiers, random forests, XGBoost, and k-nearest neighbors on a range of small datasets.
Learning body-affordances to simplify action spaces
Aug 15, 2017
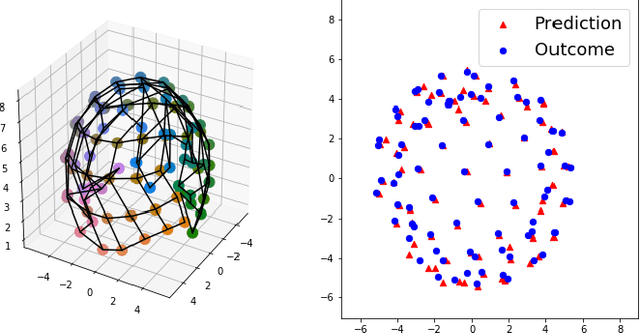
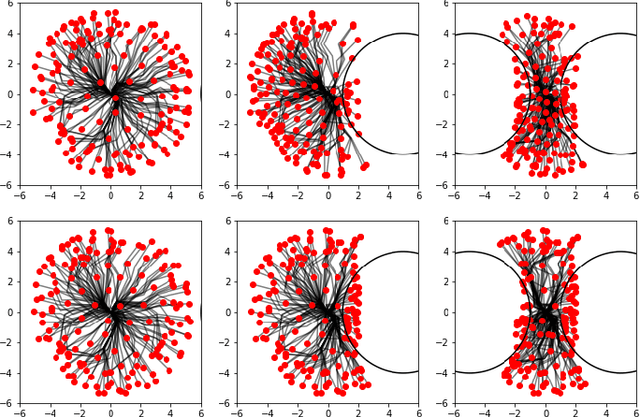
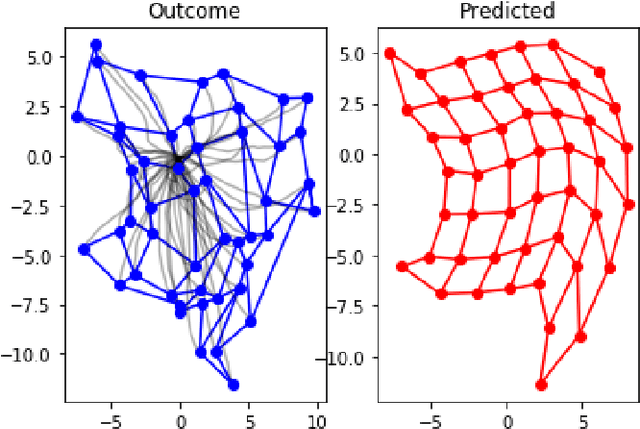
Controlling embodied agents with many actuated degrees of freedom is a challenging task. We propose a method that can discover and interpolate between context dependent high-level actions or body-affordances. These provide an abstract, low-dimensional interface indexing high-dimensional and time- extended action policies. Our method is related to recent ap- proaches in the machine learning literature but is conceptually simpler and easier to implement. More specifically our method requires the choice of a n-dimensional target sensor space that is endowed with a distance metric. The method then learns an also n-dimensional embedding of possibly reactive body-affordances that spread as far as possible throughout the target sensor space.
Counterfactual Control for Free from Generative Models
Mar 09, 2017

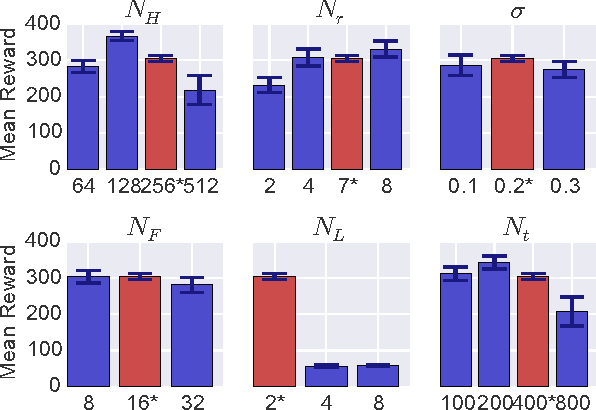

We introduce a method by which a generative model learning the joint distribution between actions and future states can be used to automatically infer a control scheme for any desired reward function, which may be altered on the fly without retraining the model. In this method, the problem of action selection is reduced to one of gradient descent on the latent space of the generative model, with the model itself providing the means of evaluating outcomes and finding the gradient, much like how the reward network in Deep Q-Networks (DQN) provides gradient information for the action generator. Unlike DQN or Actor-Critic, which are conditional models for a specific reward, using a generative model of the full joint distribution permits the reward to be changed on the fly. In addition, the generated futures can be inspected to gain insight in to what the network 'thinks' will happen, and to what went wrong when the outcomes deviate from prediction.