 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Guard for Learned Optimizers
Jan 28, 2022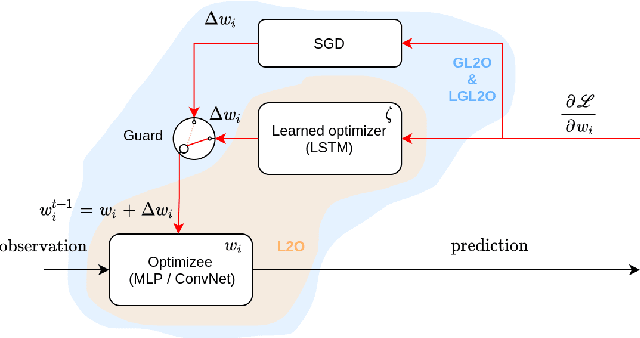

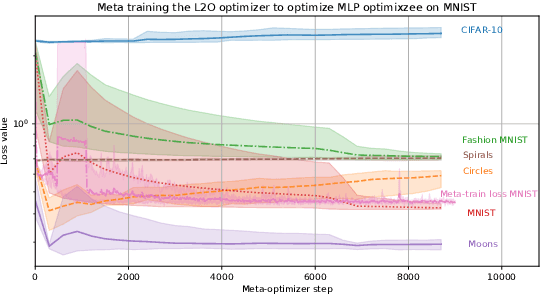
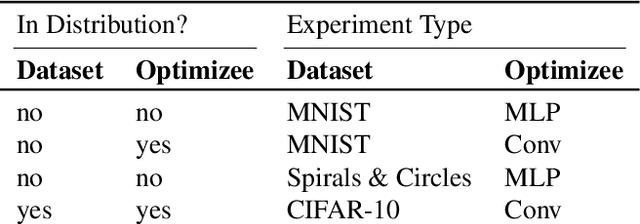
If the trend of learned components eventually outperforming their hand-crafted version continues, learned optimizers will eventually outperform hand-crafted optimizers like SGD or Adam. Even if learned optimizers (L2Os) eventually outpace hand-crafted ones in practice however, they are still not provably convergent and might fail out of distribution. These are the questions addressed here. Currently, learned optimizers frequently outperform generic hand-crafted optimizers (such as gradient descent) at the beginning of learning but they generally plateau after some time while the generic algorithms continue to make progress and often overtake the learned algorithm as Aesop's tortoise which overtakes the hare and are not. L2Os also still have a difficult time generalizing out of distribution. (Heaton et al., 2020) proposed Safeguarded L2O (GL2O) which can take a learned optimizer and safeguard it with a generic learning algorithm so that by conditionally switching between the two, the resulting algorithm is provably convergent. We propose a new class of Safeguarded L2O, called Loss-Guarded L2O (LGL2O), which is both conceptually simpler and computationally less expensive. The guarding mechanism decides solely based on the expected future loss value of both optimizers. Furthermore, we show theoretical proof of LGL2O's convergence guarantee and empirical results comparing to GL2O and other baselines showing that it combines the best of both L2O and SGD and and in practice converges much better than GL2O.
BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)
Dec 03, 2019![Figure 1 for BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F2e8dd183207e83abdc653bc126189032d6b7ab5e%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F2e8dd183207e83abdc653bc126189032d6b7ab5e%2F1-Figure2-1.png&w=640&q=75)
![Figure 3 for BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F2e8dd183207e83abdc653bc126189032d6b7ab5e%2F5-Figure6-1.png&w=640&q=75)
![Figure 4 for BADGER: Learning to (Learn [Learning Algorithms] through Multi-Agent Communication)](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F2e8dd183207e83abdc653bc126189032d6b7ab5e%2F5-Figure7-1.png&w=640&q=75)
In this work, we propose a novel memory-based multi-agent meta-learning architecture and learning procedure that allows for learning of a shared communication policy that enables the emergence of rapid adaptation to new and unseen environments by learning to learn learning algorithms through communication. Behavior, adaptation and learning to adapt emerges from the interactions of homogeneous experts inside a single agent. The proposed architecture should allow for generalization beyond the level seen in existing methods, in part due to the use of a single policy shared by all experts within the agent as well as the inherent modularity of 'Badger'.
ToyArchitecture: Unsupervised Learning of Interpretable Models of the World
Apr 12, 2019
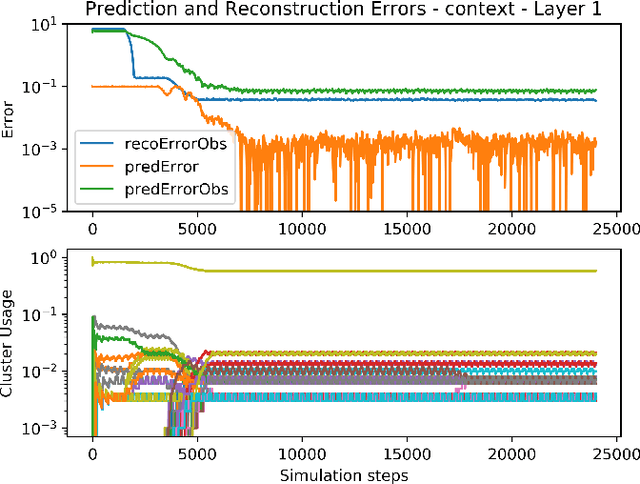
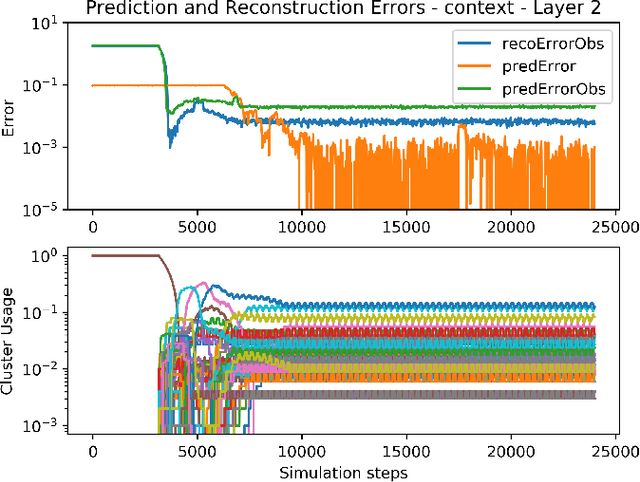
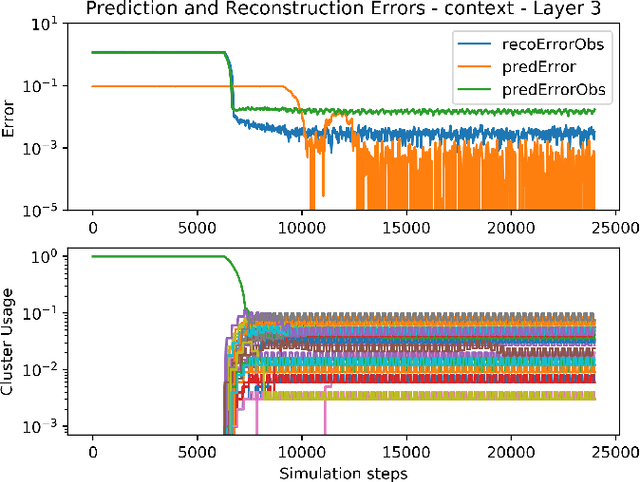
Research in Artificial Intelligence (AI) has focused mostly on two extremes: either on small improvements in narrow AI domains, or on universal theoretical frameworks which are usually uncomputable, incompatible with theories of biological intelligence, or lack practical implementations. The goal of this work is to combine the main advantages of the two: to follow a big picture view, while providing a particular theory and its implementation. In contrast with purely theoretical approaches, the resulting architecture should be usable in realistic settings, but also form the core of a framework containing all the basic mechanisms, into which it should be easier to integrate additional required functionality. In this paper, we present a novel, purposely simple, and interpretable hierarchical architecture which combines multiple different mechanisms into one system: unsupervised learning of a model of the world, learning the influence of one's own actions on the world, model-based reinforcement learning, hierarchical planning and plan execution, and symbolic/sub-symbolic integration in general. The learned model is stored in the form of hierarchical representations with the following properties: 1) they are increasingly more abstract, but can retain details when needed, and 2) they are easy to manipulate in their local and symbolic-like form, thus also allowing one to observe the learning process at each level of abstraction. On all levels of the system, the representation of the data can be interpreted in both a symbolic and a sub-symbolic manner. This enables the architecture to learn efficiently using sub-symbolic methods and to employ symbolic inference.
General AI Challenge - Round One: Gradual Learning
Aug 17, 2017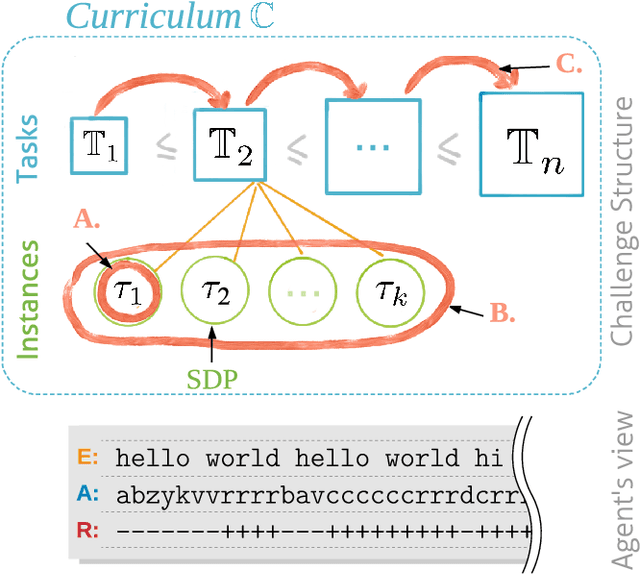
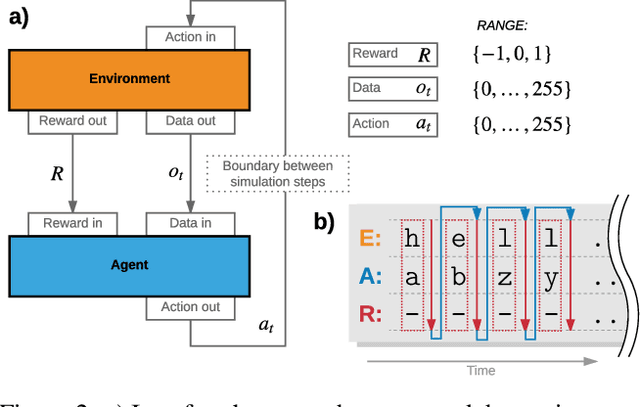
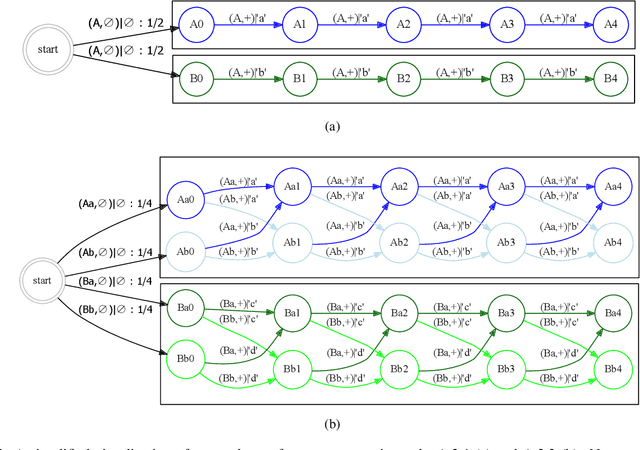
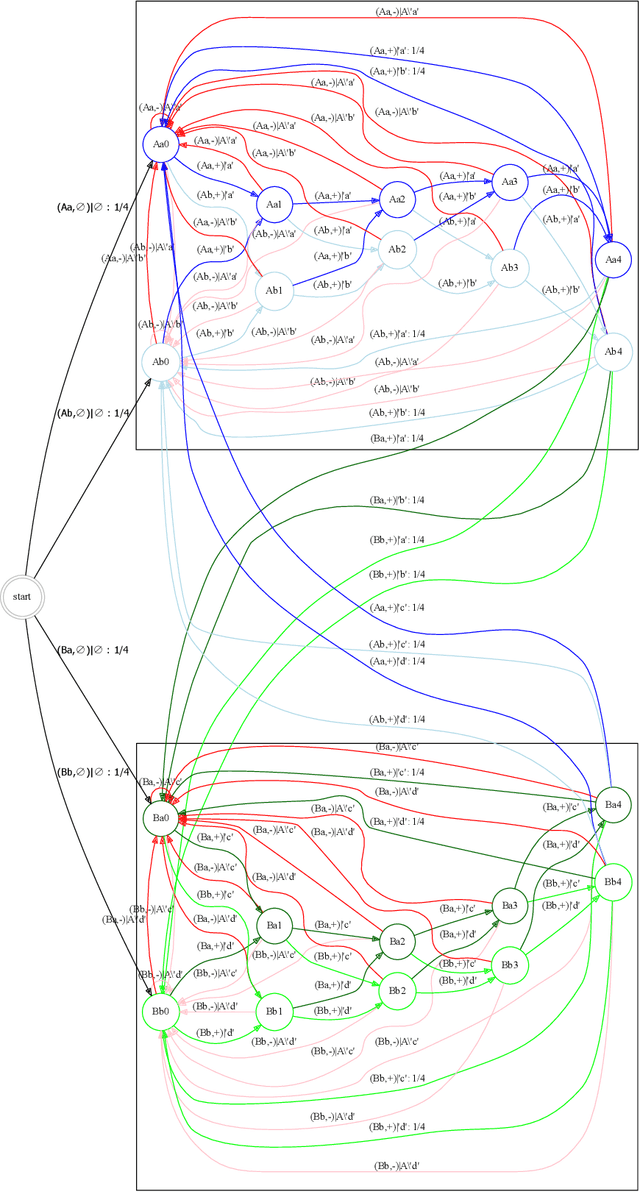
The General AI Challenge is an initiative to encourage the wider artificial intelligence community to focus on important problems in building intelligent machines with more general scope than is currently possible. The challenge comprises of multiple rounds, with the first round focusing on gradual learning, i.e. the ability to re-use already learned knowledge for efficiently learning to solve subsequent problems. In this article, we will present details of the first round of the challenge, its inspiration and aims. We also outline a more formal description of the challenge and present a preliminary analysis of its curriculum, based on ideas from computational mechanics. We believe, that such formalism will allow for a more principled approach towards investigating tasks in the challenge, building new curricula and for potentially improving consequent challenge rounds.
A Framework for Searching for General Artificial Intelligence
Nov 02, 2016
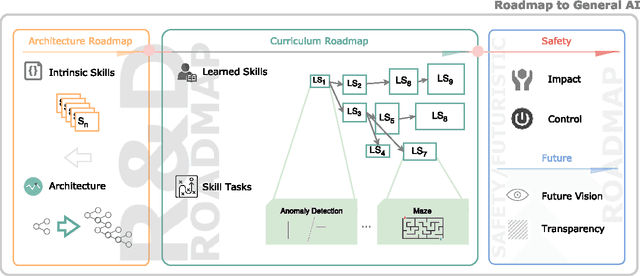
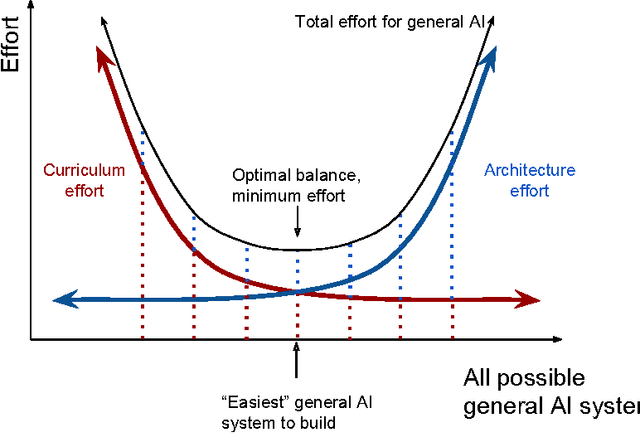
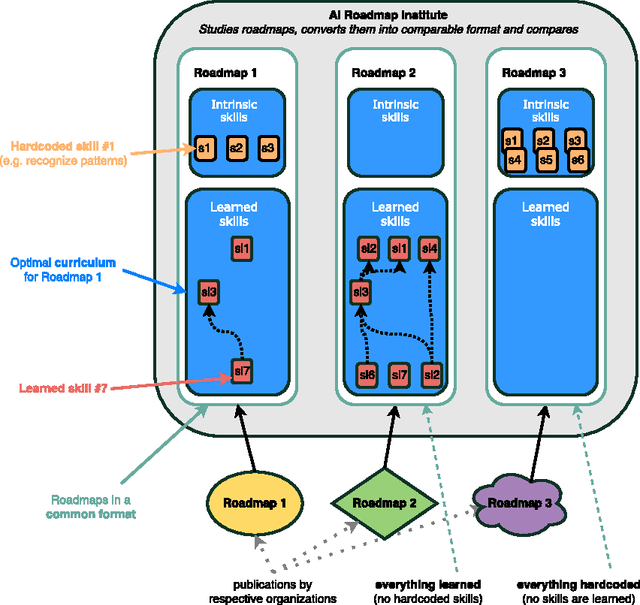
There is a significant lack of unified approaches to building generally intelligent machines. The majority of current artificial intelligence research operates within a very narrow field of focus, frequently without considering the importance of the 'big picture'. In this document, we seek to describe and unify principles that guide the basis of our development of general artificial intelligence. These principles revolve around the idea that intelligence is a tool for searching for general solutions to problems. We define intelligence as the ability to acquire skills that narrow this search, diversify it and help steer it to more promising areas. We also provide suggestions for studying, measuring, and testing the various skills and abilities that a human-level intelligent machine needs to acquire. The document aims to be both implementation agnostic, and to provide an analytic, systematic, and scalable way to generate hypotheses that we believe are needed to meet the necessary conditions in the search for general artificial intelligence. We believe that such a framework is an important stepping stone for bringing together definitions, highlighting open problems, connecting researchers willing to collaborate, and for unifying the arguably most significant search of this century.
Self-Organising Maps in Computer Security
Aug 05, 2016Some argue that biologically inspired algorithms are the future of solving difficult problems in computer science. Others strongly believe that the future lies in the exploration of mathematical foundations of problems at hand. The field of computer security tends to accept the latter view as a more appropriate approach due to its more workable validation and verification possibilities. The lack of rigorous scientific practices prevalent in biologically inspired security research does not aid in presenting bio-inspired security approaches as a viable way of dealing with complex security problems. This chapter introduces a biologically inspired algorithm, called the Self Organising Map (SOM), that was developed by Teuvo Kohonen in 1981. Since the algorithm's inception it has been scrutinised by the scientific community and analysed in more than 4000 research papers, many of which dealt with various computer security issues, from anomaly detection, analysis of executables all the way to wireless network monitoring. In this chapter a review of security related SOM research undertaken in the past is presented and analysed. The algorithm's biological analogies are detailed and the author's view on the future possibilities of this successful bio-inspired approach are given. The SOM algorithm's close relation to a number of vital functions of the human brain and the emergence of multi-core computer architectures are the two main reasons behind our assumption that the future of the SOM algorithm and its variations is promising, notably in the field of computer security.
Quiet in Class: Classification, Noise and the Dendritic Cell Algorithm
Jul 04, 2013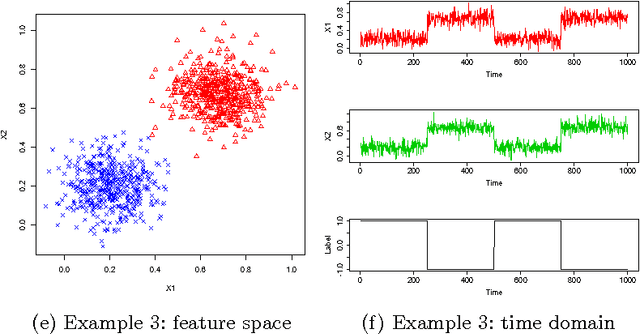
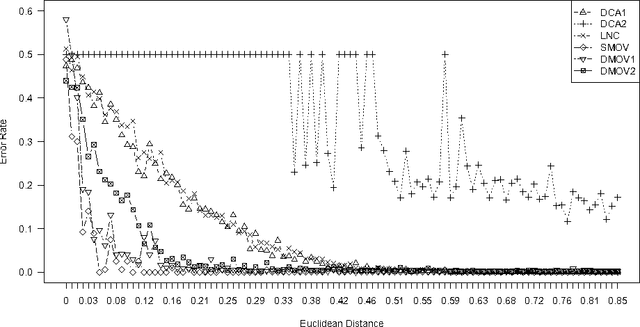
Theoretical analyses of the Dendritic Cell Algorithm (DCA) have yielded several criticisms about its underlying structure and operation. As a result, several alterations and fixes have been suggested in the literature to correct for these findings. A contribution of this work is to investigate the effects of replacing the classification stage of the DCA (which is known to be flawed) with a traditional machine learning technique. This work goes on to question the merits of those unique properties of the DCA that are yet to be thoroughly analysed. If none of these properties can be found to have a benefit over traditional approaches, then "fixing" the DCA is arguably less efficient than simply creating a new algorithm. This work examines the dynamic filtering property of the DCA and questions the utility of this unique feature for the anomaly detection problem. It is found that this feature, while advantageous for noisy, time-ordered classification, is not as useful as a traditional static filter for processing a synthetic dataset. It is concluded that there are still unique features of the DCA left to investigate. Areas that may be of benefit to the Artificial Immune Systems community are suggested.
Investigating the Detection of Adverse Drug Events in a UK General Practice Electronic Health-Care Database
Jul 03, 2013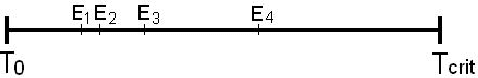
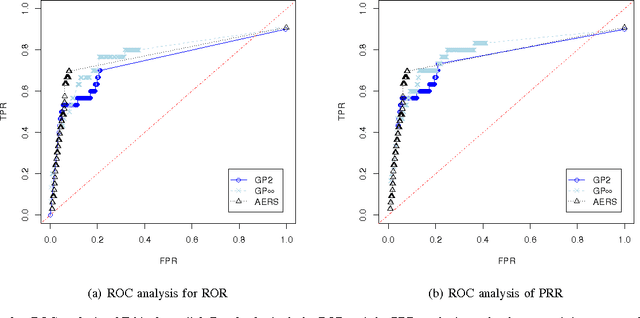
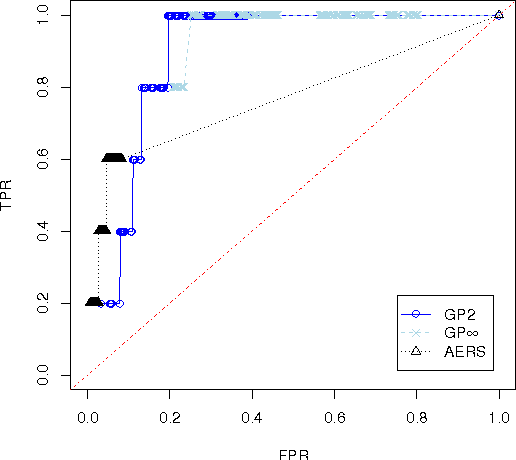
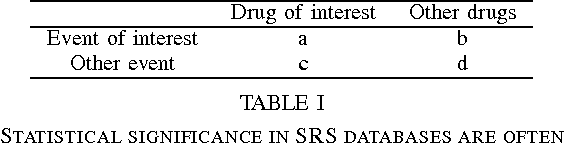
Data-mining techniques have frequently been developed for Spontaneous reporting databases. These techniques aim to find adverse drug events accurately and efficiently. Spontaneous reporting databases are prone to missing information, under reporting and incorrect entries. This often results in a detection lag or prevents the detection of some adverse drug events. These limitations do not occur in electronic health-care databases. In this paper, existing methods developed for spontaneous reporting databases are implemented on both a spontaneous reporting database and a general practice electronic health-care database and compared. The results suggests that the application of existing methods to the general practice database may help find signals that have gone undetected when using the spontaneous reporting system database. In addition the general practice database provides far more supplementary information, that if incorporated in analysis could provide a wealth of information for identifying adverse events more accurately.
Wavelet feature extraction and genetic algorithm for biomarker detection in colorectal cancer data
May 31, 2013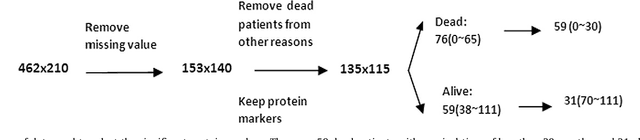

Biomarkers which predict patient's survival can play an important role in medical diagnosis and treatment. How to select the significant biomarkers from hundreds of protein markers is a key step in survival analysis. In this paper a novel method is proposed to detect the prognostic biomarkers of survival in colorectal cancer patients using wavelet analysis, genetic algorithm, and Bayes classifier. One dimensional discrete wavelet transform (DWT) is normally used to reduce the dimensionality of biomedical data. In this study one dimensional continuous wavelet transform (CWT) was proposed to extract the features of colorectal cancer data. One dimensional CWT has no ability to reduce dimensionality of data, but captures the missing features of DWT, and is complementary part of DWT. Genetic algorithm was performed on extracted wavelet coefficients to select the optimized features, using Bayes classifier to build its fitness function. The corresponding protein markers were located based on the position of optimized features. Kaplan-Meier curve and Cox regression model were used to evaluate the performance of selected biomarkers. Experiments were conducted on colorectal cancer dataset and several significant biomarkers were detected. A new protein biomarker CD46 was found to significantly associate with survival time.
Privileged Information for Data Clustering
May 31, 2013



Many machine learning algorithms assume that all input samples are independently and identically distributed from some common distribution on either the input space X, in the case of unsupervised learning, or the input and output space X x Y in the case of supervised and semi-supervised learning. In the last number of years the relaxation of this assumption has been explored and the importance of incorporation of additional information within machine learning algorithms became more apparent. Traditionally such fusion of information was the domain of semi-supervised learning. More recently the inclusion of knowledge from separate hypothetical spaces has been proposed by Vapnik as part of the supervised setting. In this work we are interested in exploring Vapnik's idea of master-class learning and the associated learning using privileged information, however within the unsupervised setting. Adoption of the advanced supervised learning paradigm for the unsupervised setting instigates investigation into the difference between privileged and technical data. By means of our proposed aRi-MAX method stability of the KMeans algorithm is improved and identification of the best clustering solution is achieved on an artificial dataset. Subsequently an information theoretic dot product based algorithm called P-Dot is proposed. This method has the ability to utilize a wide variety of clustering techniques, individually or in combination, while fusing privileged and technical data for improved clustering. Application of the P-Dot method to the task of digit recognition confirms our findings in a real-world scenario.