 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Candidate Risk Factors for Prescription Drug Side Effects using Causal Contrast Set Mining
Jul 20, 2016
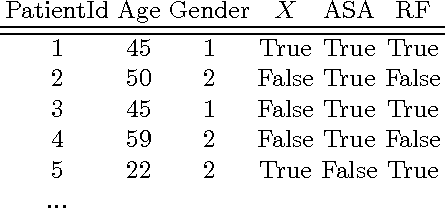
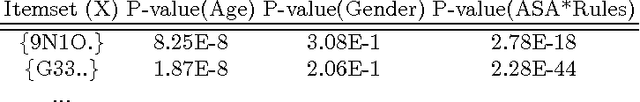

Big longitudinal observational databases present the opportunity to extract new knowledge in a cost effective manner. Unfortunately, the ability of these databases to be used for causal inference is limited due to the passive way in which the data are collected resulting in various forms of bias. In this paper we investigate a method that can overcome these limitations and determine causal contrast set rules efficiently from big data. In particular, we present a new methodology for the purpose of identifying risk factors that increase a patients likelihood of experiencing the known rare side effect of renal failure after ingesting aminosalicylates. The results show that the methodology was able to identify previously researched risk factors such as being prescribed diuretics and highlighted that patients with a higher than average risk of renal failure may be even more susceptible to experiencing it as a side effect after ingesting aminosalicylates.
Personalising Mobile Advertising Based on Users Installed Apps
Feb 24, 2015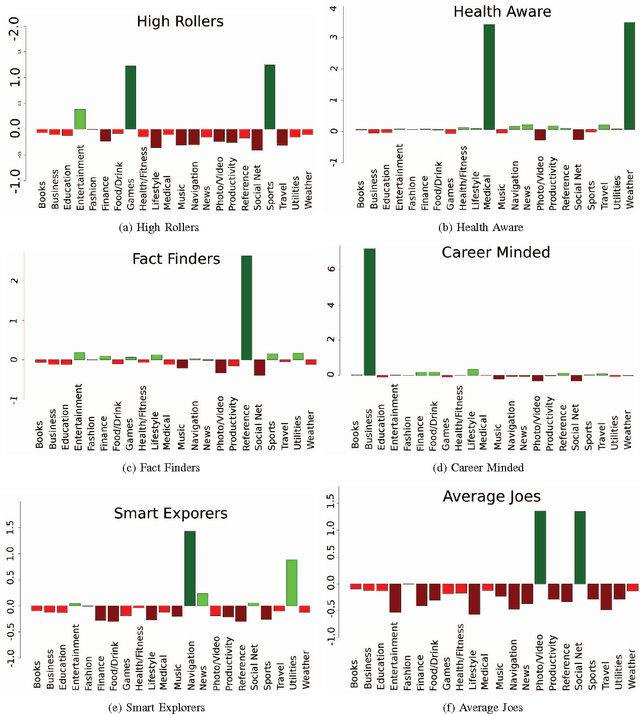
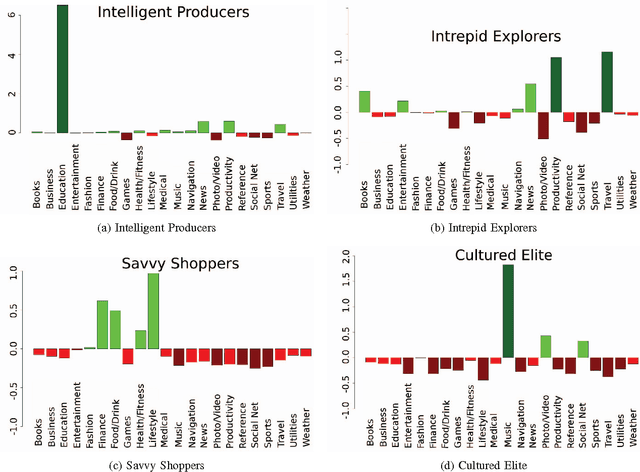
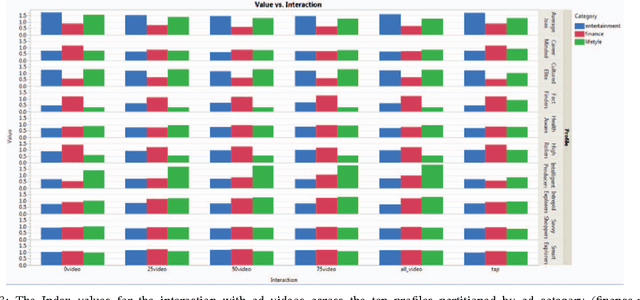

Mobile advertising is a billion pound industry that is rapidly expanding. The success of an advert is measured based on how users interact with it. In this paper we investigate whether the application of unsupervised learning and association rule mining could be used to enable personalised targeting of mobile adverts with the aim of increasing the interaction rate. Over May and June 2014 we recorded advert interactions such as tapping the advert or watching the whole advert video along with the set of apps a user has installed at the time of the interaction. Based on the apps that the users have installed we applied k-means clustering to profile the users into one of ten classes. Due to the large number of apps considered we implemented dimension reduction to reduced the app feature space by mapping the apps to their iTunes category and clustered users based on the percentage of their apps that correspond to each iTunes app category. The clustering was externally validated by investigating differences between the way the ten profiles interact with the various adverts genres (lifestyle, finance and entertainment adverts). In addition association rule mining was performed to find whether the time of the day that the advert is served and the number of apps a user has installed makes certain profiles more likely to interact with the advert genres. The results showed there were clear differences in the way the profiles interact with the different advert genres and the results of this paper suggest that mobile advert targeting would improve the frequency that users interact with an advert.
Attributes for Causal Inference in Longitudinal Observational Databases
Sep 03, 2014
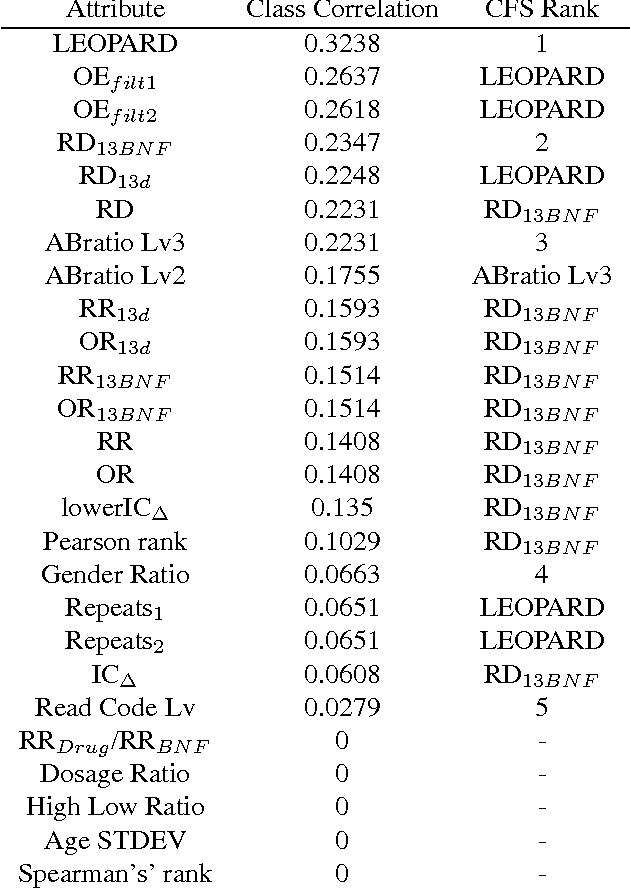
The pharmaceutical industry is plagued by the problem of side effects that can occur anytime a prescribed medication is ingested. There has been a recent interest in using the vast quantities of medical data available in longitudinal observational databases to identify causal relationships between drugs and medical events. Unfortunately the majority of existing post marketing surveillance algorithms measure how dependant or associated an event is on the presence of a drug rather than measuring causality. In this paper we investigate potential attributes that can be used in causal inference to identify side effects based on the Bradford-Hill causality criteria. Potential attributes are developed by considering five of the causality criteria and feature selection is applied to identify the most suitable of these attributes for detecting side effects. We found that attributes based on the specificity criterion may improve side effect signalling algorithms but the experiment and dosage criteria attributes investigated in this paper did not offer sufficient additional information.
A Novel Semi-Supervised Algorithm for Rare Prescription Side Effect Discovery
Sep 02, 2014

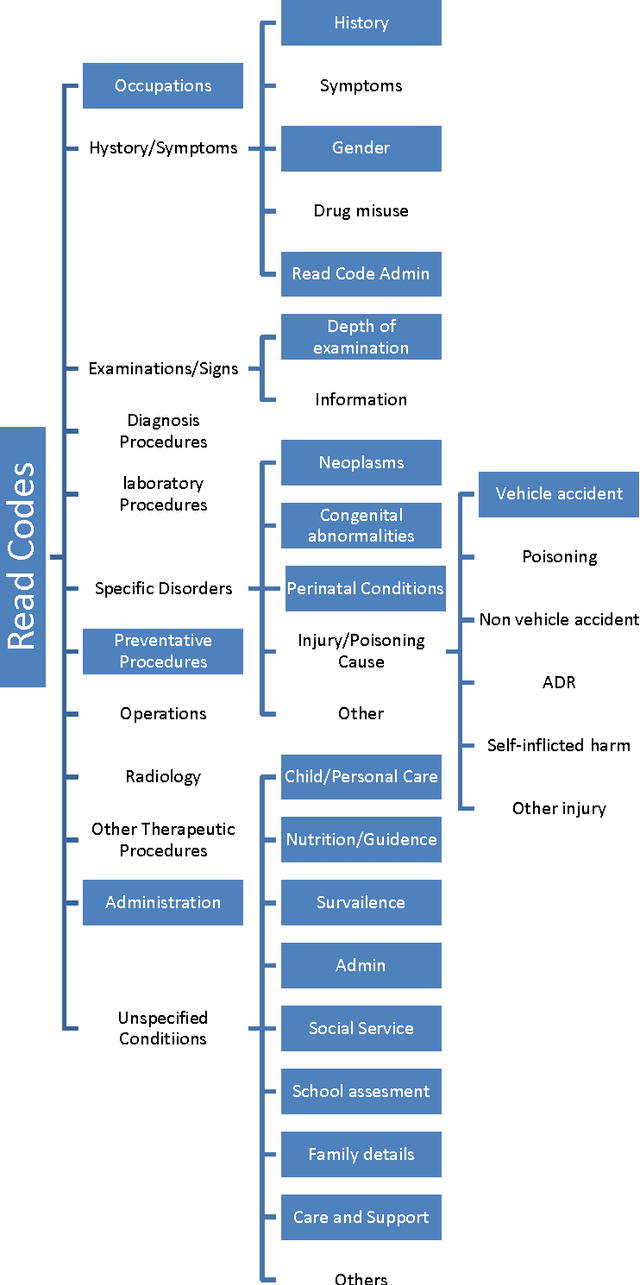

Drugs are frequently prescribed to patients with the aim of improving each patient's medical state, but an unfortunate consequence of most prescription drugs is the occurrence of undesirable side effects. Side effects that occur in more than one in a thousand patients are likely to be signalled efficiently by current drug surveillance methods, however, these same methods may take decades before generating signals for rarer side effects, risking medical morbidity or mortality in patients prescribed the drug while the rare side effect is undiscovered. In this paper we propose a novel computational meta-analysis framework for signalling rare side effects that integrates existing methods, knowledge from the web, metric learning and semi-supervised clustering. The novel framework was able to signal many known rare and serious side effects for the selection of drugs investigated, such as tendon rupture when prescribed Ciprofloxacin or Levofloxacin, renal failure with Naproxen and depression associated with Rimonabant. Furthermore, for the majority of the drug investigated it generated signals for rare side effects at a more stringent signalling threshold than existing methods and shows the potential to become a fundamental part of post marketing surveillance to detect rare side effects.
Comparison of algorithms that detect drug side effects using electronic healthcare databases
Sep 02, 2014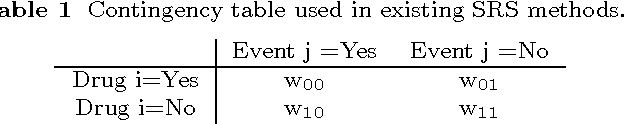

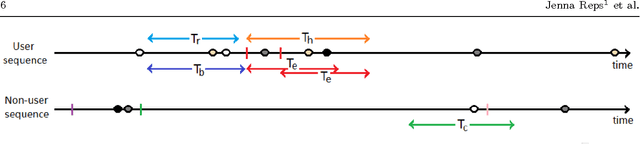

The electronic healthcare databases are starting to become more readily available and are thought to have excellent potential for generating adverse drug reaction signals. The Health Improvement Network (THIN) database is an electronic healthcare database containing medical information on over 11 million patients that has excellent potential for detecting ADRs. In this paper we apply four existing electronic healthcare database signal detecting algorithms (MUTARA, HUNT, Temporal Pattern Discovery and modified ROR) on the THIN database for a selection of drugs from six chosen drug families. This is the first comparison of ADR signalling algorithms that includes MUTARA and HUNT and enabled us to set a benchmark for the adverse drug reaction signalling ability of the THIN database. The drugs were selectively chosen to enable a comparison with previous work and for variety. It was found that no algorithm was generally superior and the algorithms' natural thresholds act at variable stringencies. Furthermore, none of the algorithms perform well at detecting rare ADRs.
Comparing Data-mining Algorithms Developed for Longitudinal Observational Databases
Jul 05, 2013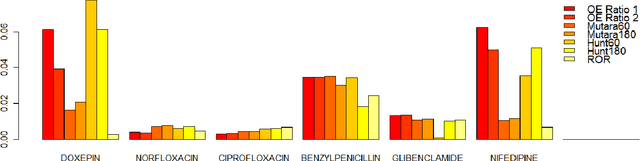

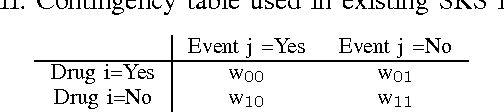
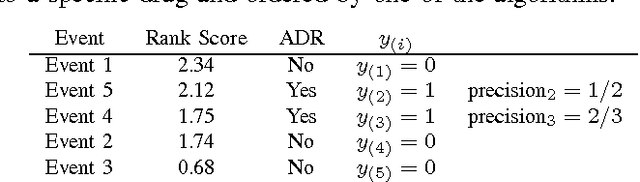
Longitudinal observational databases have become a recent interest in the post marketing drug surveillance community due to their ability of presenting a new perspective for detecting negative side effects. Algorithms mining longitudinal observation databases are not restricted by many of the limitations associated with the more conventional methods that have been developed for spontaneous reporting system databases. In this paper we investigate the robustness of four recently developed algorithms that mine longitudinal observational databases by applying them to The Health Improvement Network (THIN) for six drugs with well document known negative side effects. Our results show that none of the existing algorithms was able to consistently identify known adverse drug reactions above events related to the cause of the drug and no algorithm was superior.
Discovering Sequential Patterns in a UK General Practice Database
Jul 04, 2013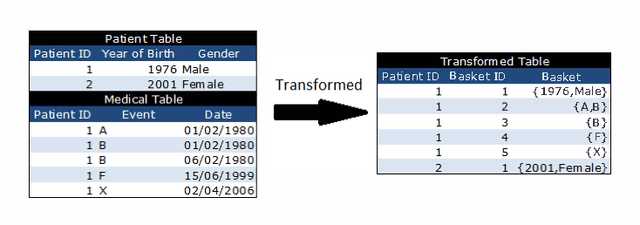



The wealth of computerised medical information becoming readily available presents the opportunity to examine patterns of illnesses, therapies and responses. These patterns may be able to predict illnesses that a patient is likely to develop, allowing the implementation of preventative actions. In this paper sequential rule mining is applied to a General Practice database to find rules involving a patients age, gender and medical history. By incorporating these rules into current health-care a patient can be highlighted as susceptible to a future illness based on past or current illnesses, gender and year of birth. This knowledge has the ability to greatly improve health-care and reduce health-care costs.
Quiet in Class: Classification, Noise and the Dendritic Cell Algorithm
Jul 04, 2013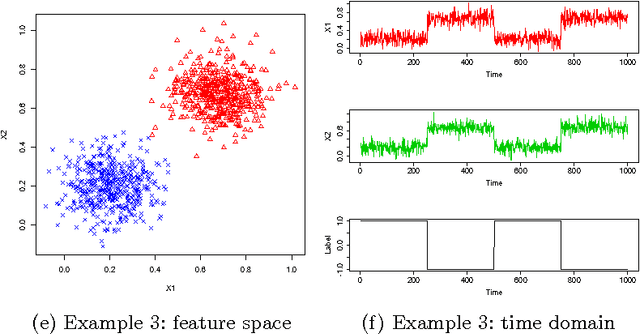
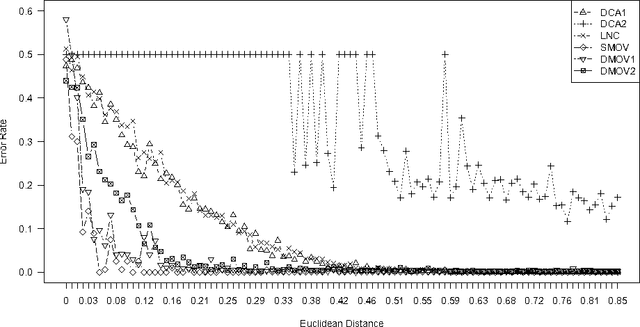
Theoretical analyses of the Dendritic Cell Algorithm (DCA) have yielded several criticisms about its underlying structure and operation. As a result, several alterations and fixes have been suggested in the literature to correct for these findings. A contribution of this work is to investigate the effects of replacing the classification stage of the DCA (which is known to be flawed) with a traditional machine learning technique. This work goes on to question the merits of those unique properties of the DCA that are yet to be thoroughly analysed. If none of these properties can be found to have a benefit over traditional approaches, then "fixing" the DCA is arguably less efficient than simply creating a new algorithm. This work examines the dynamic filtering property of the DCA and questions the utility of this unique feature for the anomaly detection problem. It is found that this feature, while advantageous for noisy, time-ordered classification, is not as useful as a traditional static filter for processing a synthetic dataset. It is concluded that there are still unique features of the DCA left to investigate. Areas that may be of benefit to the Artificial Immune Systems community are suggested.
Investigating the Detection of Adverse Drug Events in a UK General Practice Electronic Health-Care Database
Jul 03, 2013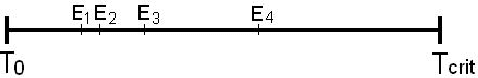
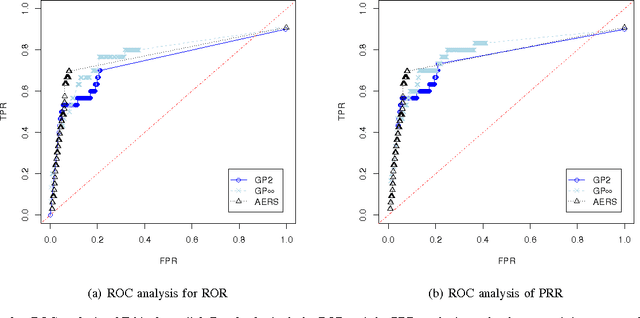
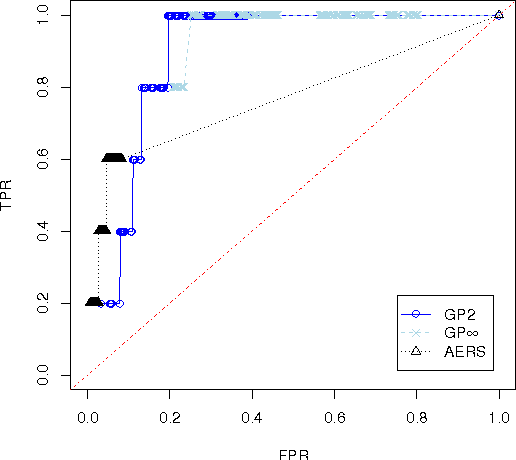
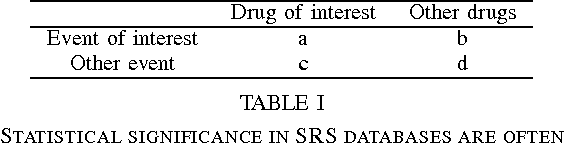
Data-mining techniques have frequently been developed for Spontaneous reporting databases. These techniques aim to find adverse drug events accurately and efficiently. Spontaneous reporting databases are prone to missing information, under reporting and incorrect entries. This often results in a detection lag or prevents the detection of some adverse drug events. These limitations do not occur in electronic health-care databases. In this paper, existing methods developed for spontaneous reporting databases are implemented on both a spontaneous reporting database and a general practice electronic health-care database and compared. The results suggests that the application of existing methods to the general practice database may help find signals that have gone undetected when using the spontaneous reporting system database. In addition the general practice database provides far more supplementary information, that if incorporated in analysis could provide a wealth of information for identifying adverse events more accurately.