 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Adverse Drug Reaction Signalling Framework Imitating Bradford Hill's Causality Considerations
Jul 21, 2016

Big longitudinal observational medical data potentially hold a wealth of information and have been recognised as potential sources for gaining new drug safety knowledge. Unfortunately there are many complexities and underlying issues when analysing longitudinal observational data. Due to these complexities, existing methods for large-scale detection of negative side effects using observational data all tend to have issues distinguishing between association and causality. New methods that can better discriminate causal and non-causal relationships need to be developed to fully utilise the data. In this paper we propose using a set of causality considerations developed by the epidemiologist Bradford Hill as a basis for engineering features that enable the application of supervised learning for the problem of detecting negative side effects. The Bradford Hill considerations look at various perspectives of a drug and outcome relationship to determine whether it shows causal traits. We taught a classifier to find patterns within these perspectives and it learned to discriminate between association and causality. The novelty of this research is the combination of supervised learning and Bradford Hill's causality considerations to automate the Bradford Hill's causality assessment. We evaluated the framework on a drug safety gold standard know as the observational medical outcomes partnership's nonspecified association reference set. The methodology obtained excellent discriminate ability with area under the curves ranging between 0.792-0.940 (existing method optimal: 0.73) and a mean average precision of 0.640 (existing method optimal: 0.141). The proposed features can be calculated efficiently and be readily updated, making the framework suitable for big observational data.
Refining adverse drug reaction signals by incorporating interaction variables identified using emergent pattern mining
Jul 20, 2016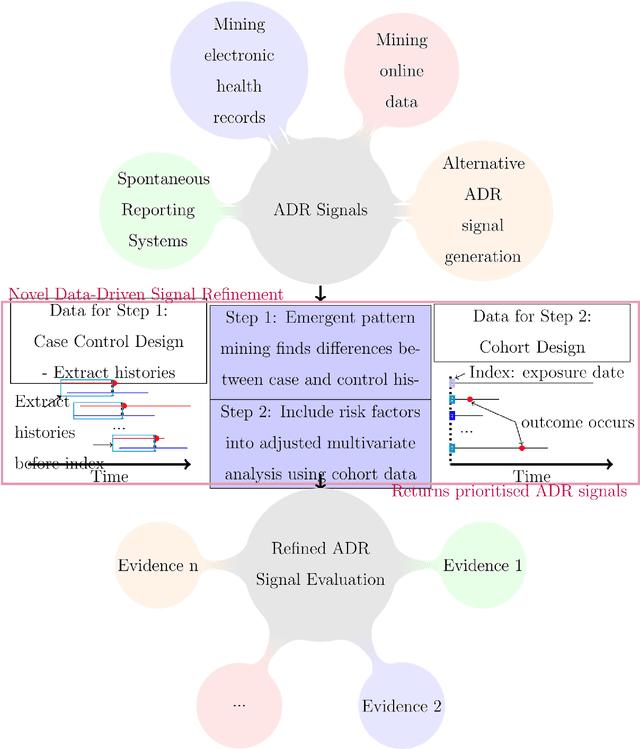
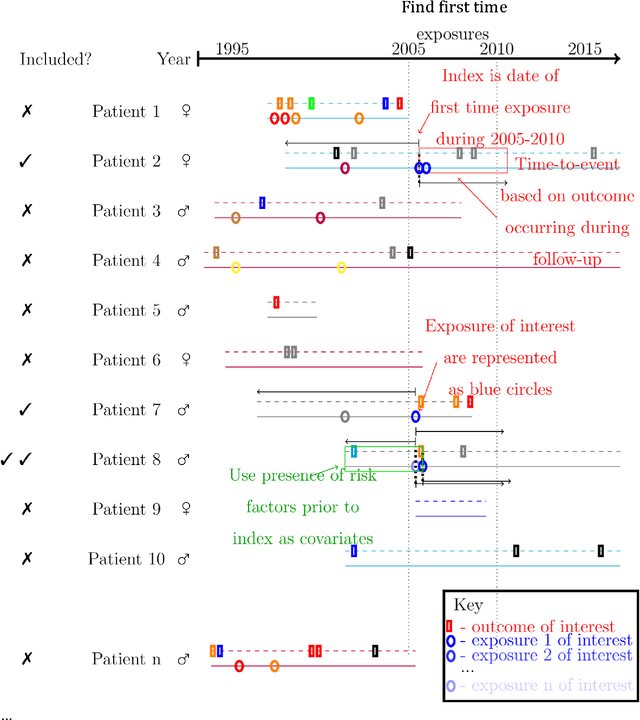
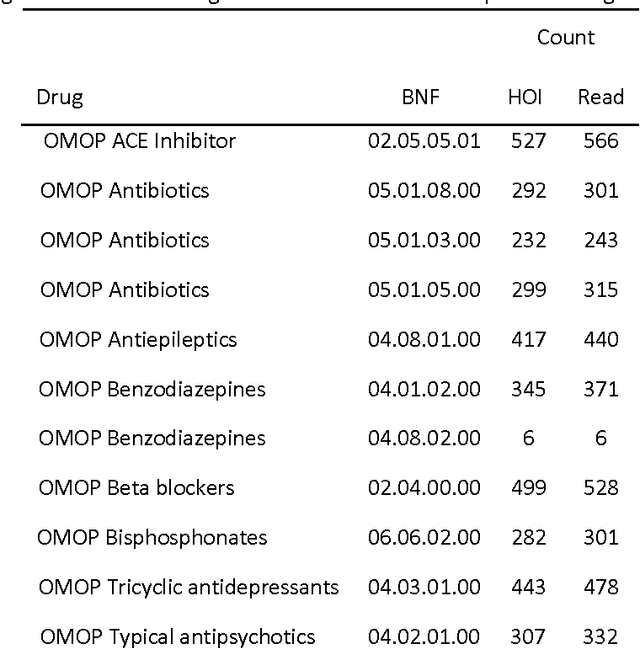
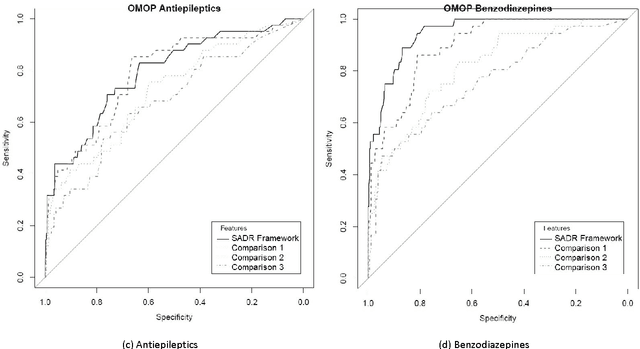
Purpose: To develop a framework for identifying and incorporating candidate confounding interaction terms into a regularised cox regression analysis to refine adverse drug reaction signals obtained via longitudinal observational data. Methods: We considered six drug families that are commonly associated with myocardial infarction in observational healthcare data, but where the causal relationship ground truth is known (adverse drug reaction or not). We applied emergent pattern mining to find itemsets of drugs and medical events that are associated with the development of myocardial infarction. These are the candidate confounding interaction terms. We then implemented a cohort study design using regularised cox regression that incorporated and accounted for the candidate confounding interaction terms. Results The methodology was able to account for signals generated due to confounding and a cox regression with elastic net regularisation correctly ranked the drug families known to be true adverse drug reactions above those.
Attributes for Causal Inference in Longitudinal Observational Databases
Sep 03, 2014
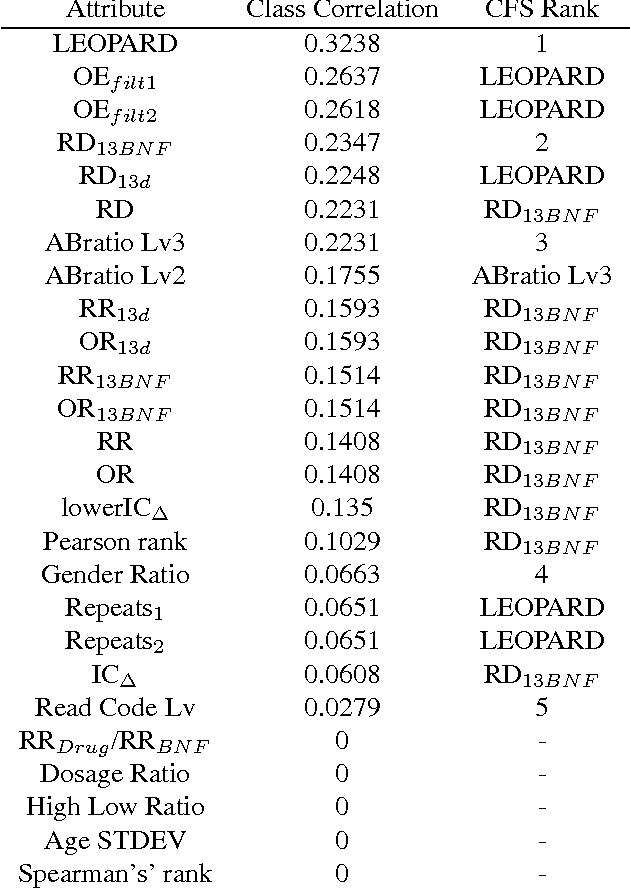
The pharmaceutical industry is plagued by the problem of side effects that can occur anytime a prescribed medication is ingested. There has been a recent interest in using the vast quantities of medical data available in longitudinal observational databases to identify causal relationships between drugs and medical events. Unfortunately the majority of existing post marketing surveillance algorithms measure how dependant or associated an event is on the presence of a drug rather than measuring causality. In this paper we investigate potential attributes that can be used in causal inference to identify side effects based on the Bradford-Hill causality criteria. Potential attributes are developed by considering five of the causality criteria and feature selection is applied to identify the most suitable of these attributes for detecting side effects. We found that attributes based on the specificity criterion may improve side effect signalling algorithms but the experiment and dosage criteria attributes investigated in this paper did not offer sufficient additional information.
Signalling Paediatric Side Effects using an Ensemble of Simple Study Designs
Sep 02, 2014
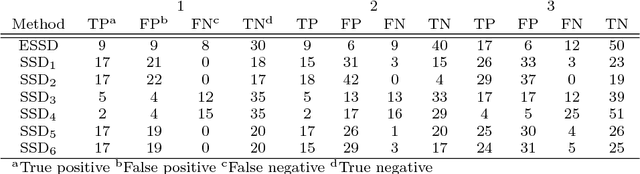
Background: Children are frequently prescribed medication off-label, meaning there has not been sufficient testing of the medication to determine its safety or effectiveness. The main reason this safety knowledge is lacking is due to ethical restrictions that prevent children from being included in the majority of clinical trials. Objective: The objective of this paper is to investigate whether an ensemble of simple study designs can be implemented to signal acutely occurring side effects effectively within the paediatric population by using historical longitudinal data. The majority of pharmacovigilance techniques are unsupervised, but this research presents a supervised framework. Methods: Multiple measures of association are calculated for each drug and medical event pair and these are used as features that are fed into a classiffier to determine the likelihood of the drug and medical event pair corresponding to an adverse drug reaction. The classiffier is trained using known adverse drug reactions or known non-adverse drug reaction relationships. Results: The novel ensemble framework obtained a false positive rate of 0:149, a sensitivity of 0:547 and a specificity of 0:851 when implemented on a reference set of drug and medical event pairs. The novel framework consistently outperformed each individual simple study design. Conclusion: This research shows that it is possible to exploit the mechanism of causality and presents a framework for signalling adverse drug reactions effectively.
A Novel Semi-Supervised Algorithm for Rare Prescription Side Effect Discovery
Sep 02, 2014

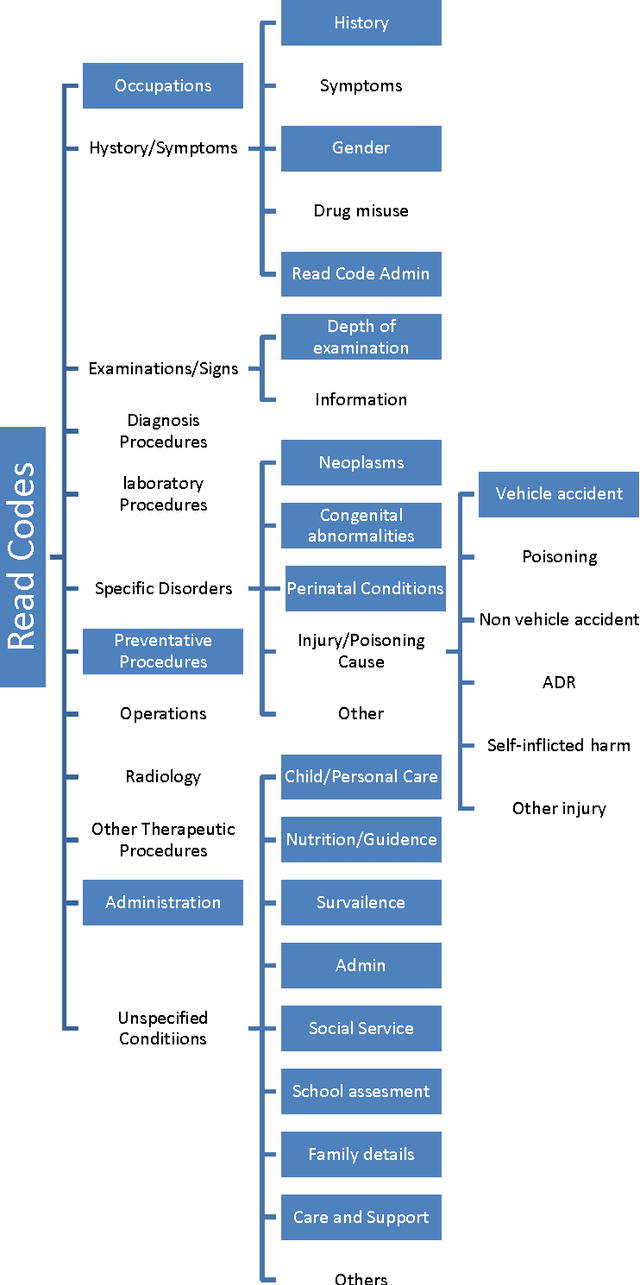

Drugs are frequently prescribed to patients with the aim of improving each patient's medical state, but an unfortunate consequence of most prescription drugs is the occurrence of undesirable side effects. Side effects that occur in more than one in a thousand patients are likely to be signalled efficiently by current drug surveillance methods, however, these same methods may take decades before generating signals for rarer side effects, risking medical morbidity or mortality in patients prescribed the drug while the rare side effect is undiscovered. In this paper we propose a novel computational meta-analysis framework for signalling rare side effects that integrates existing methods, knowledge from the web, metric learning and semi-supervised clustering. The novel framework was able to signal many known rare and serious side effects for the selection of drugs investigated, such as tendon rupture when prescribed Ciprofloxacin or Levofloxacin, renal failure with Naproxen and depression associated with Rimonabant. Furthermore, for the majority of the drug investigated it generated signals for rare side effects at a more stringent signalling threshold than existing methods and shows the potential to become a fundamental part of post marketing surveillance to detect rare side effects.
Comparing Data-mining Algorithms Developed for Longitudinal Observational Databases
Jul 05, 2013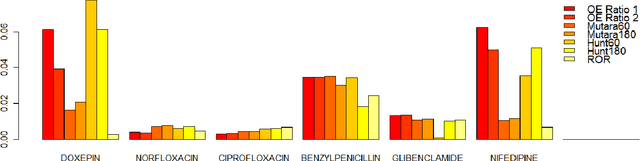

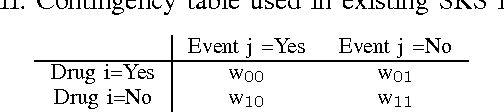
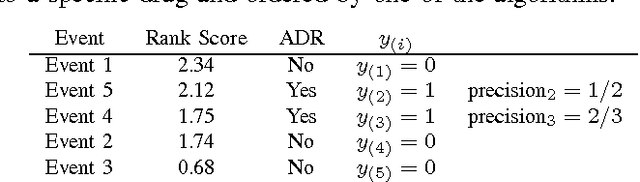
Longitudinal observational databases have become a recent interest in the post marketing drug surveillance community due to their ability of presenting a new perspective for detecting negative side effects. Algorithms mining longitudinal observation databases are not restricted by many of the limitations associated with the more conventional methods that have been developed for spontaneous reporting system databases. In this paper we investigate the robustness of four recently developed algorithms that mine longitudinal observational databases by applying them to The Health Improvement Network (THIN) for six drugs with well document known negative side effects. Our results show that none of the existing algorithms was able to consistently identify known adverse drug reactions above events related to the cause of the drug and no algorithm was superior.
Discovering Sequential Patterns in a UK General Practice Database
Jul 04, 2013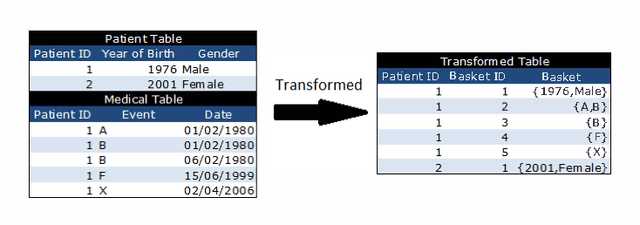



The wealth of computerised medical information becoming readily available presents the opportunity to examine patterns of illnesses, therapies and responses. These patterns may be able to predict illnesses that a patient is likely to develop, allowing the implementation of preventative actions. In this paper sequential rule mining is applied to a General Practice database to find rules involving a patients age, gender and medical history. By incorporating these rules into current health-care a patient can be highlighted as susceptible to a future illness based on past or current illnesses, gender and year of birth. This knowledge has the ability to greatly improve health-care and reduce health-care costs.
Investigating the Detection of Adverse Drug Events in a UK General Practice Electronic Health-Care Database
Jul 03, 2013
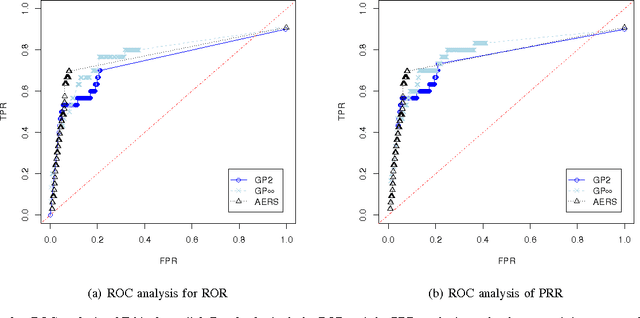
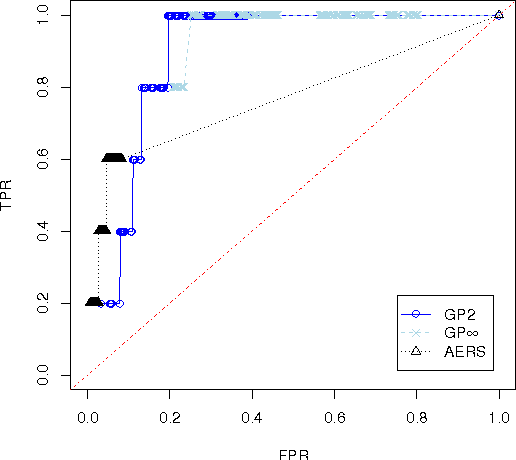
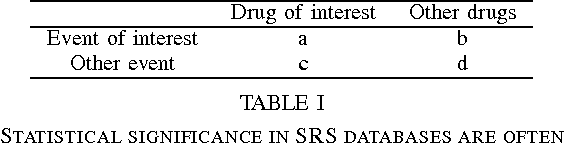
Data-mining techniques have frequently been developed for Spontaneous reporting databases. These techniques aim to find adverse drug events accurately and efficiently. Spontaneous reporting databases are prone to missing information, under reporting and incorrect entries. This often results in a detection lag or prevents the detection of some adverse drug events. These limitations do not occur in electronic health-care databases. In this paper, existing methods developed for spontaneous reporting databases are implemented on both a spontaneous reporting database and a general practice electronic health-care database and compared. The results suggests that the application of existing methods to the general practice database may help find signals that have gone undetected when using the spontaneous reporting system database. In addition the general practice database provides far more supplementary information, that if incorporated in analysis could provide a wealth of information for identifying adverse events more accurately.