 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Deep Learning Histochemical Scoring System for Breast Cancer Tissue Microarray
Jan 19, 2018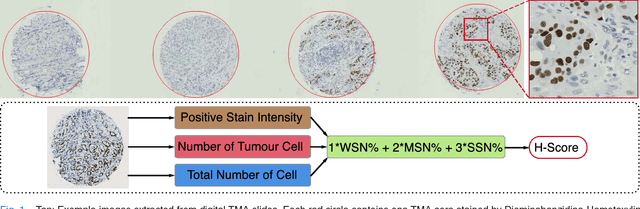
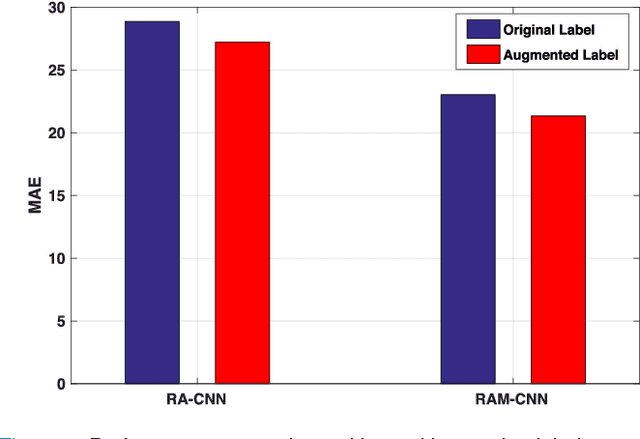
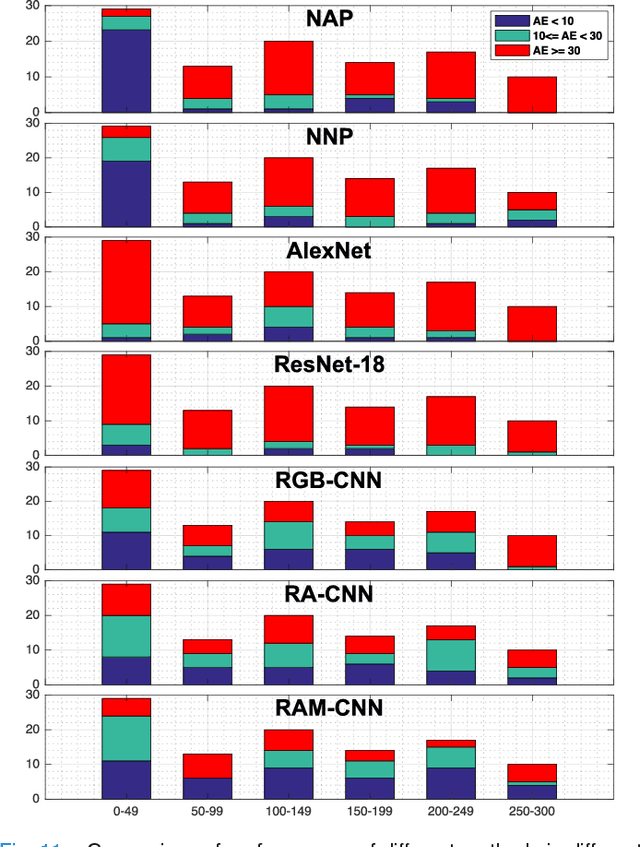

One of the methods for stratifying different molecular classes of breast cancer is the Nottingham Prognostic Index Plus (NPI+) which uses breast cancer relevant biomarkers to stain tumour tissues prepared on tissue microarray (TMA). To determine the molecular class of the tumour, pathologists will have to manually mark the nuclei activity biomarkers through a microscope and use a semi-quantitative assessment method to assign a histochemical score (H-Score) to each TMA core. Manually marking positively stained nuclei is a time consuming, imprecise and subjective process which will lead to inter-observer and intra-observer discrepancies. In this paper, we present an end-to-end deep learning system which directly predicts the H-Score automatically. Our system imitates the pathologists' decision process and uses one fully convolutional network (FCN) to extract all nuclei region (tumour and non-tumour), a second FCN to extract tumour nuclei region, and a multi-column convolutional neural network which takes the outputs of the first two FCNs and the stain intensity description image as input and acts as the high-level decision making mechanism to directly output the H-Score of the input TMA image. To the best of our knowledge, this is the first end-to-end system that takes a TMA image as input and directly outputs a clinical score. We will present experimental results which demonstrate that the H-Scores predicted by our model have very high and statistically significant correlation with experienced pathologists' scores and that the H-Score discrepancy between our algorithm and the pathologists is on par with the inter-subject discrepancy between the pathologists.
Attributes for Causal Inference in Longitudinal Observational Databases
Sep 03, 2014
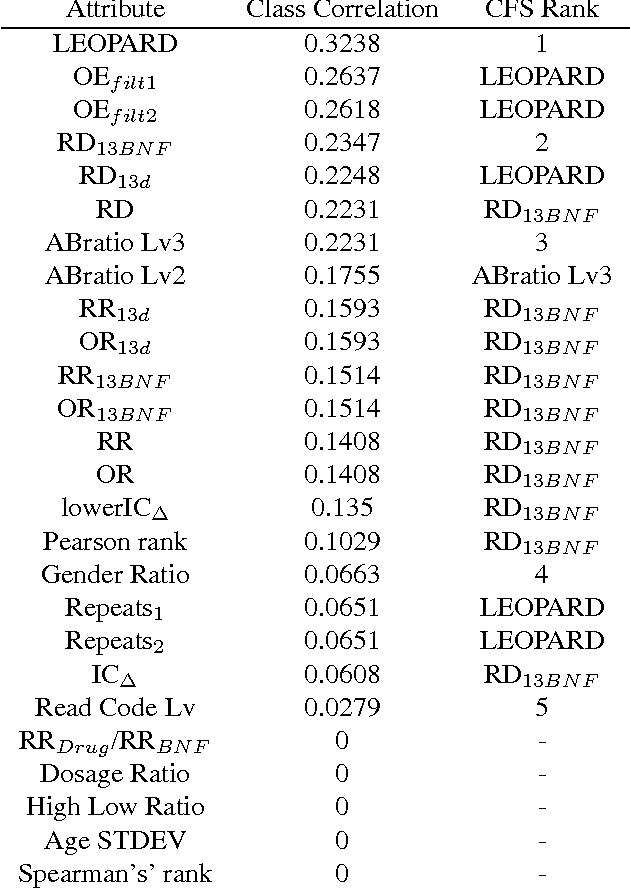
The pharmaceutical industry is plagued by the problem of side effects that can occur anytime a prescribed medication is ingested. There has been a recent interest in using the vast quantities of medical data available in longitudinal observational databases to identify causal relationships between drugs and medical events. Unfortunately the majority of existing post marketing surveillance algorithms measure how dependant or associated an event is on the presence of a drug rather than measuring causality. In this paper we investigate potential attributes that can be used in causal inference to identify side effects based on the Bradford-Hill causality criteria. Potential attributes are developed by considering five of the causality criteria and feature selection is applied to identify the most suitable of these attributes for detecting side effects. We found that attributes based on the specificity criterion may improve side effect signalling algorithms but the experiment and dosage criteria attributes investigated in this paper did not offer sufficient additional information.
Signalling Paediatric Side Effects using an Ensemble of Simple Study Designs
Sep 02, 2014
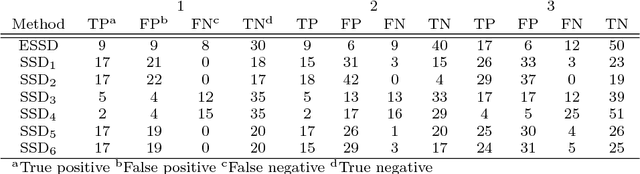
Background: Children are frequently prescribed medication off-label, meaning there has not been sufficient testing of the medication to determine its safety or effectiveness. The main reason this safety knowledge is lacking is due to ethical restrictions that prevent children from being included in the majority of clinical trials. Objective: The objective of this paper is to investigate whether an ensemble of simple study designs can be implemented to signal acutely occurring side effects effectively within the paediatric population by using historical longitudinal data. The majority of pharmacovigilance techniques are unsupervised, but this research presents a supervised framework. Methods: Multiple measures of association are calculated for each drug and medical event pair and these are used as features that are fed into a classiffier to determine the likelihood of the drug and medical event pair corresponding to an adverse drug reaction. The classiffier is trained using known adverse drug reactions or known non-adverse drug reaction relationships. Results: The novel ensemble framework obtained a false positive rate of 0:149, a sensitivity of 0:547 and a specificity of 0:851 when implemented on a reference set of drug and medical event pairs. The novel framework consistently outperformed each individual simple study design. Conclusion: This research shows that it is possible to exploit the mechanism of causality and presents a framework for signalling adverse drug reactions effectively.
A Novel Semi-Supervised Algorithm for Rare Prescription Side Effect Discovery
Sep 02, 2014


Drugs are frequently prescribed to patients with the aim of improving each patient's medical state, but an unfortunate consequence of most prescription drugs is the occurrence of undesirable side effects. Side effects that occur in more than one in a thousand patients are likely to be signalled efficiently by current drug surveillance methods, however, these same methods may take decades before generating signals for rarer side effects, risking medical morbidity or mortality in patients prescribed the drug while the rare side effect is undiscovered. In this paper we propose a novel computational meta-analysis framework for signalling rare side effects that integrates existing methods, knowledge from the web, metric learning and semi-supervised clustering. The novel framework was able to signal many known rare and serious side effects for the selection of drugs investigated, such as tendon rupture when prescribed Ciprofloxacin or Levofloxacin, renal failure with Naproxen and depression associated with Rimonabant. Furthermore, for the majority of the drug investigated it generated signals for rare side effects at a more stringent signalling threshold than existing methods and shows the potential to become a fundamental part of post marketing surveillance to detect rare side effects.
Comparison of algorithms that detect drug side effects using electronic healthcare databases
Sep 02, 2014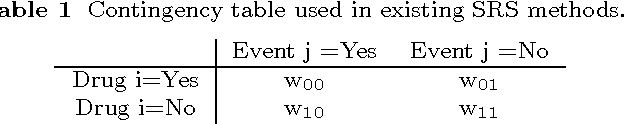

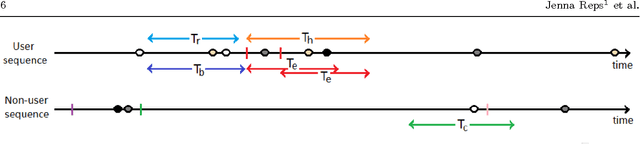

The electronic healthcare databases are starting to become more readily available and are thought to have excellent potential for generating adverse drug reaction signals. The Health Improvement Network (THIN) database is an electronic healthcare database containing medical information on over 11 million patients that has excellent potential for detecting ADRs. In this paper we apply four existing electronic healthcare database signal detecting algorithms (MUTARA, HUNT, Temporal Pattern Discovery and modified ROR) on the THIN database for a selection of drugs from six chosen drug families. This is the first comparison of ADR signalling algorithms that includes MUTARA and HUNT and enabled us to set a benchmark for the adverse drug reaction signalling ability of the THIN database. The drugs were selectively chosen to enable a comparison with previous work and for variety. It was found that no algorithm was generally superior and the algorithms' natural thresholds act at variable stringencies. Furthermore, none of the algorithms perform well at detecting rare ADRs.
Biomarker Clustering of Colorectal Cancer Data to Complement Clinical Classification
Jul 05, 2013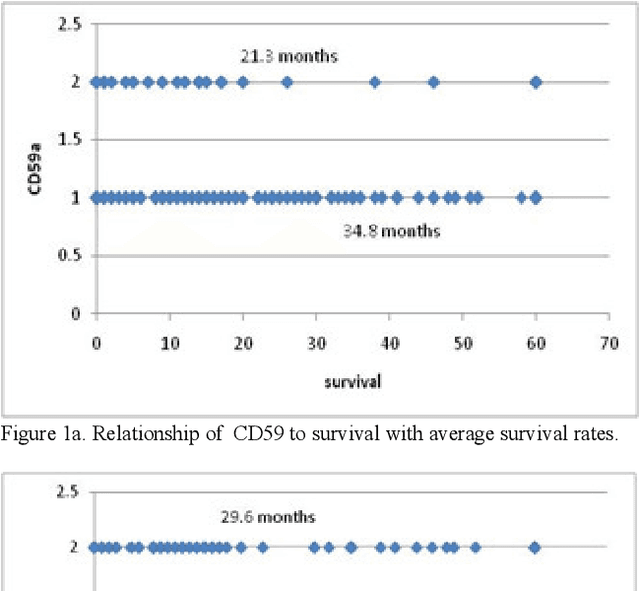
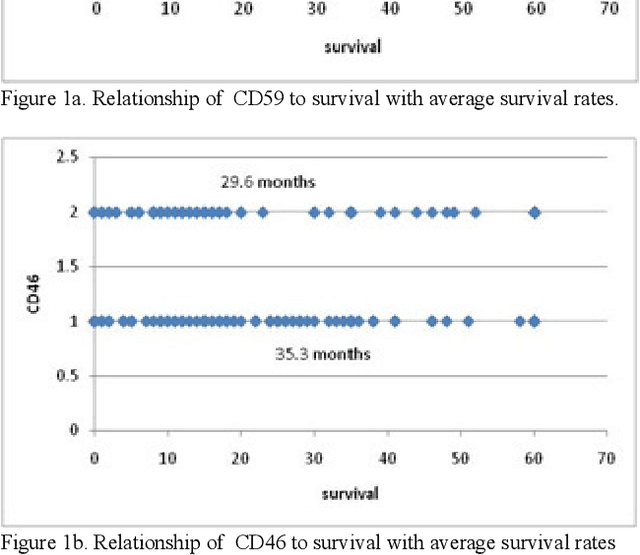
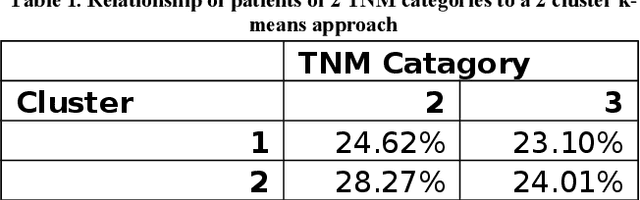

In this paper, we describe a dataset relating to cellular and physical conditions of patients who are operated upon to remove colorectal tumours. This data provides a unique insight into immunological status at the point of tumour removal, tumour classification and post-operative survival. Attempts are made to cluster this dataset and important subsets of it in an effort to characterize the data and validate existing standards for tumour classification. It is apparent from optimal clustering that existing tumour classification is largely unrelated to immunological factors within a patient and that there may be scope for re-evaluating treatment options and survival estimates based on a combination of tumour physiology and patient histochemistry.
Comparing Data-mining Algorithms Developed for Longitudinal Observational Databases
Jul 05, 2013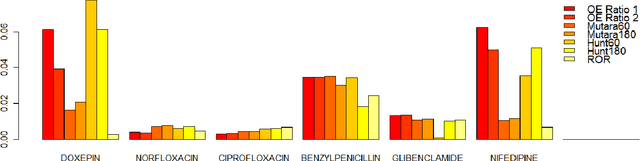

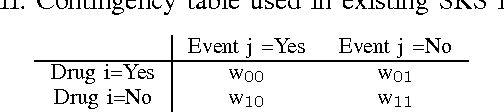
Longitudinal observational databases have become a recent interest in the post marketing drug surveillance community due to their ability of presenting a new perspective for detecting negative side effects. Algorithms mining longitudinal observation databases are not restricted by many of the limitations associated with the more conventional methods that have been developed for spontaneous reporting system databases. In this paper we investigate the robustness of four recently developed algorithms that mine longitudinal observational databases by applying them to The Health Improvement Network (THIN) for six drugs with well document known negative side effects. Our results show that none of the existing algorithms was able to consistently identify known adverse drug reactions above events related to the cause of the drug and no algorithm was superior.
Discovering Sequential Patterns in a UK General Practice Database
Jul 04, 2013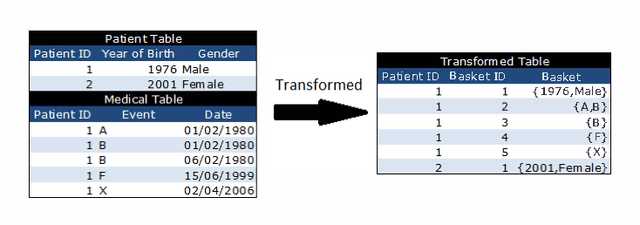



The wealth of computerised medical information becoming readily available presents the opportunity to examine patterns of illnesses, therapies and responses. These patterns may be able to predict illnesses that a patient is likely to develop, allowing the implementation of preventative actions. In this paper sequential rule mining is applied to a General Practice database to find rules involving a patients age, gender and medical history. By incorporating these rules into current health-care a patient can be highlighted as susceptible to a future illness based on past or current illnesses, gender and year of birth. This knowledge has the ability to greatly improve health-care and reduce health-care costs.