 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Key Machine Learning Principles Using Anti-learning Datasets
Nov 16, 2020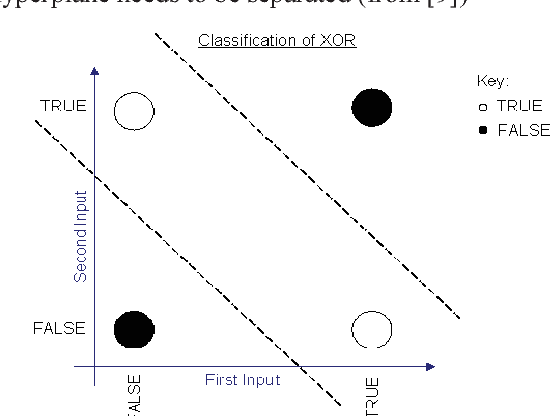

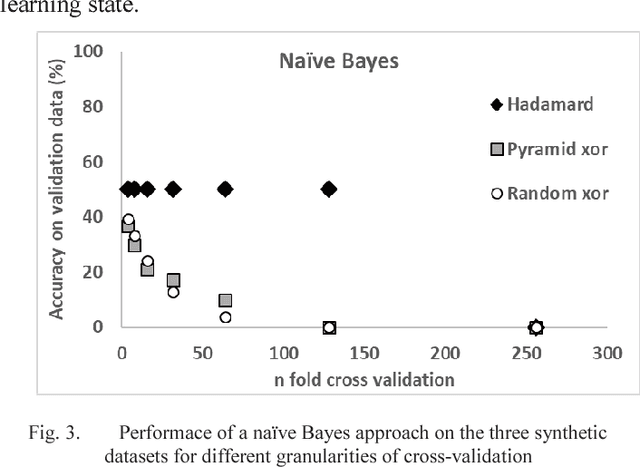
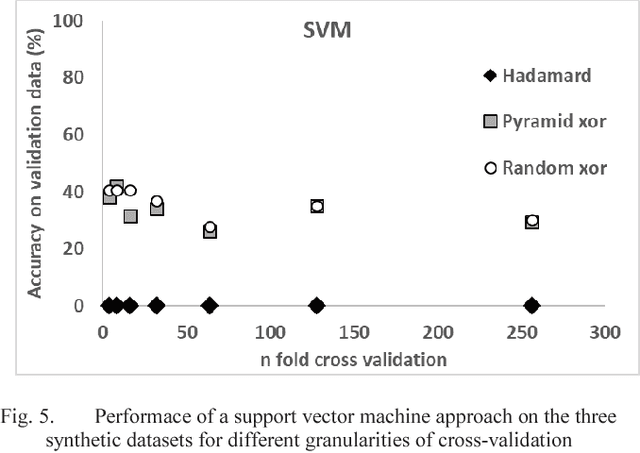
Much of the teaching of machine learning focuses on iterative hill-climbing approaches and the use of local knowledge to gain information leading to local or global maxima. In this paper we advocate the teaching of alternative methods of generalising to the best possible solution, including a method called anti-learning. By using simple teaching methods, students can achieve a deeper understanding of the importance of validation on data excluded from the training process and that each problem requires its own methods to solve. We also exemplify the requirement to train a model using sufficient data by showing that different granularities of cross-validation can yield very different results.
Ensemble Learning of Colorectal Cancer Survival Rates
Sep 02, 2014
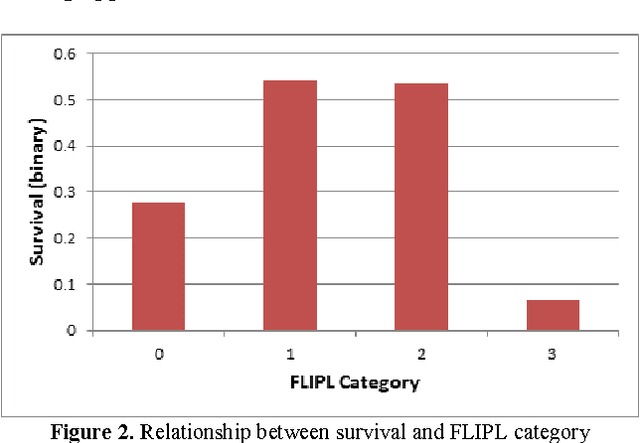
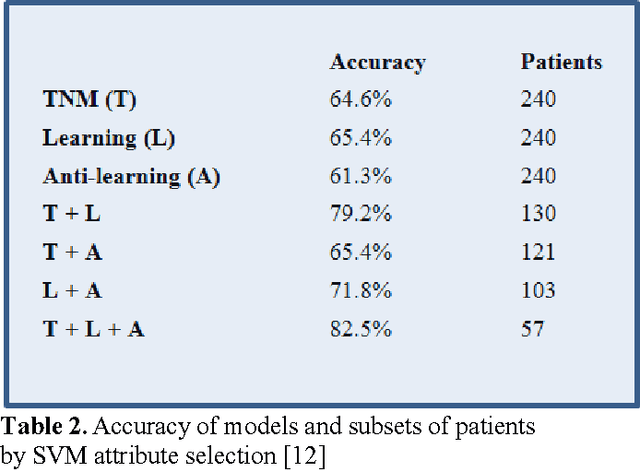

In this paper, we describe a dataset relating to cellular and physical conditions of patients who are operated upon to remove colorectal tumours. This data provides a unique insight into immunological status at the point of tumour removal, tumour classification and post-operative survival. We build on existing research on clustering and machine learning facets of this data to demonstrate a role for an ensemble approach to highlighting patients with clearer prognosis parameters. Results for survival prediction using 3 different approaches are shown for a subset of the data which is most difficult to model. The performance of each model individually is compared with subsets of the data where some agreement is reached for multiple models. Significant improvements in model accuracy on an unseen test set can be achieved for patients where agreement between models is achieved.
Data classification using the Dempster-Shafer method
Sep 02, 2014
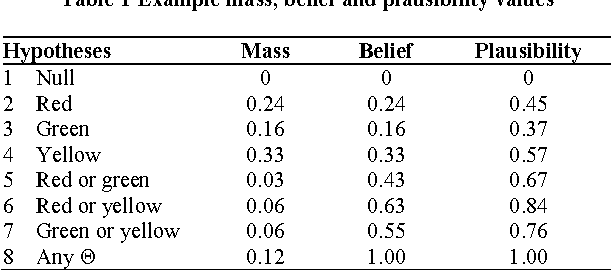
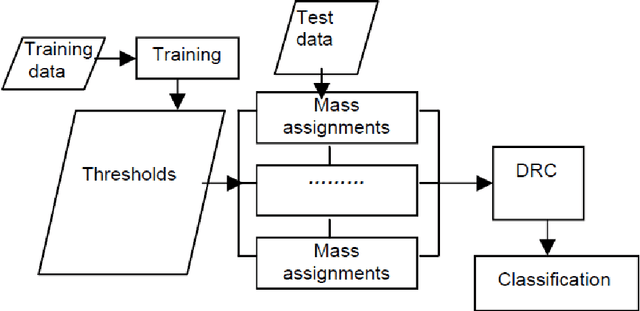

In this paper, the Dempster-Shafer method is employed as the theoretical basis for creating data classification systems. Testing is carried out using three popular (multiple attribute) benchmark datasets that have two, three and four classes. In each case, a subset of the available data is used for training to establish thresholds, limits or likelihoods of class membership for each attribute, and hence create mass functions that establish probability of class membership for each attribute of the test data. Classification of each data item is achieved by combination of these probabilities via Dempster's Rule of Combination. Results for the first two datasets show extremely high classification accuracy that is competitive with other popular methods. The third dataset is non-numerical and difficult to classify, but good results can be achieved provided the system and mass functions are designed carefully and the right attributes are chosen for combination. In all cases the Dempster-Shafer method provides comparable performance to other more popular algorithms, but the overhead of generating accurate mass functions increases the complexity with the addition of new attributes. Overall, the results suggest that the D-S approach provides a suitable framework for the design of classification systems and that automating the mass function design and calculation would increase the viability of the algorithm for complex classification problems.
Biomarker Clustering of Colorectal Cancer Data to Complement Clinical Classification
Jul 05, 2013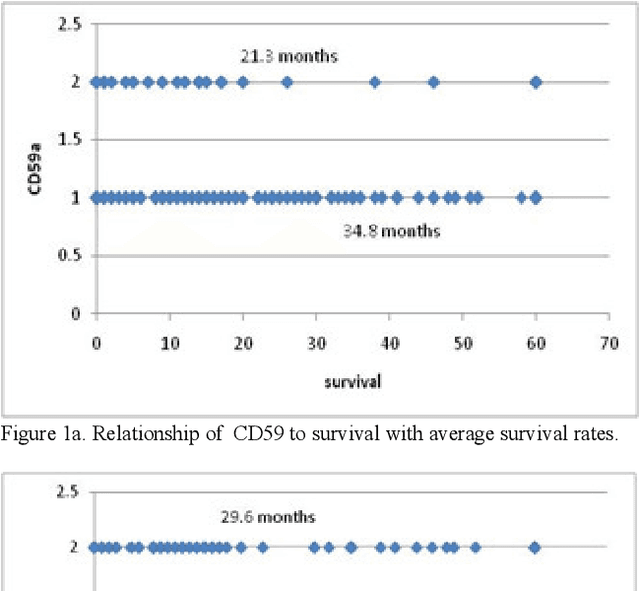
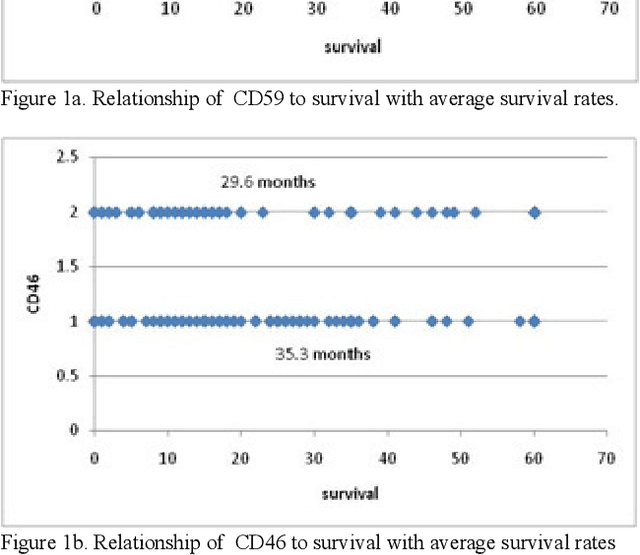
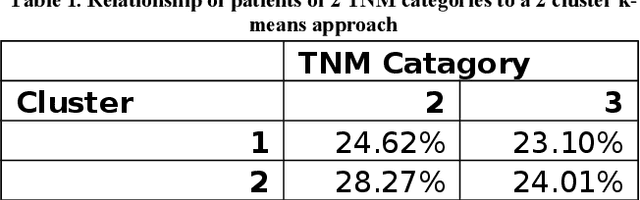

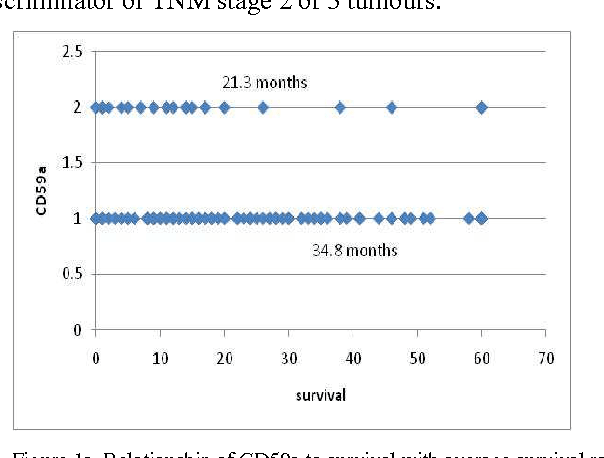
In this paper, we describe a dataset relating to cellular and physical conditions of patients who are operated upon to remove colorectal tumours. This data provides a unique insight into immunological status at the point of tumour removal, tumour classification and post-operative survival. Attempts are made to cluster this dataset and important subsets of it in an effort to characterize the data and validate existing standards for tumour classification. It is apparent from optimal clustering that existing tumour classification is largely unrelated to immunological factors within a patient and that there may be scope for re-evaluating treatment options and survival estimates based on a combination of tumour physiology and patient histochemistry.
Supervised Learning and Anti-learning of Colorectal Cancer Classes and Survival Rates from Cellular Biology Parameters
Jul 05, 2013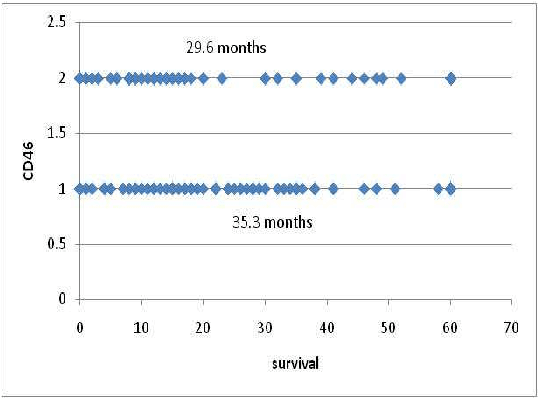
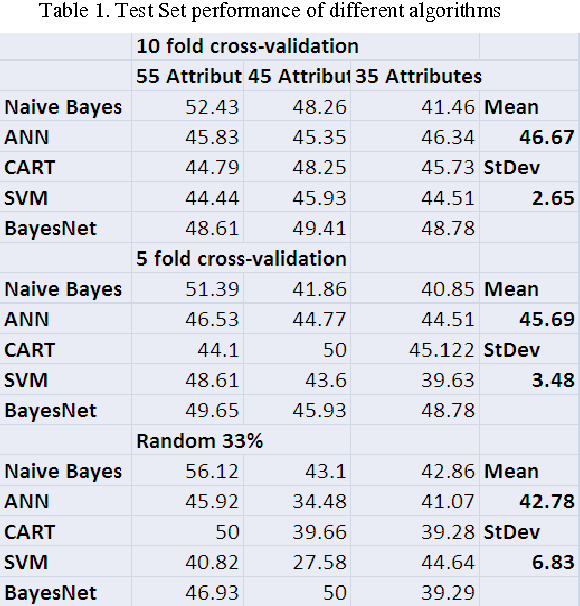
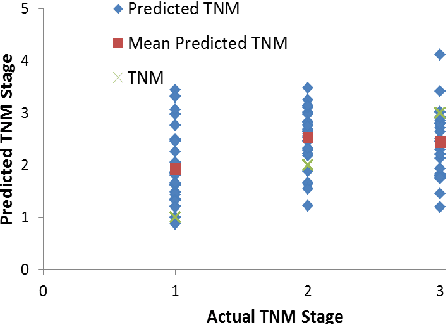
In this paper, we describe a dataset relating to cellular and physical conditions of patients who are operated upon to remove colorectal tumours. This data provides a unique insight into immunological status at the point of tumour removal, tumour classification and post-operative survival. Attempts are made to learn relationships between attributes (physical and immunological) and the resulting tumour stage and survival. Results for conventional machine learning approaches can be considered poor, especially for predicting tumour stages for the most important types of cancer. This poor performance is further investigated and compared with a synthetic, dataset based on the logical exclusive-OR function and it is shown that there is a significant level of 'anti-learning' present in all supervised methods used and this can be explained by the highly dimensional, complex and sparsely representative dataset. For predicting the stage of cancer from the immunological attributes, anti-learning approaches outperform a range of popular algorithms.
Validation of a Microsimulation of the Port of Dover
May 31, 2013



Modelling and simulating the traffic of heavily used but secure environments such as seaports and airports is of increasing importance. Errors made when simulating these environments can have long standing economic, social and environmental implications. This paper discusses issues and problems that may arise when designing a simulation strategy. Data for the Port is presented, methods for lightweight vehicle assessment that can be used to calibrate and validate simulations are also discussed along with a diagnosis of overcalibration issues. We show that decisions about where the intelligence lies in a system has important repercussions for the reliability of system statistics. Finally, conclusions are drawn about how microsimulations can be moved forward as a robust planning tool for the 21st century.