 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Guard for Learned Optimizers
Jan 28, 2022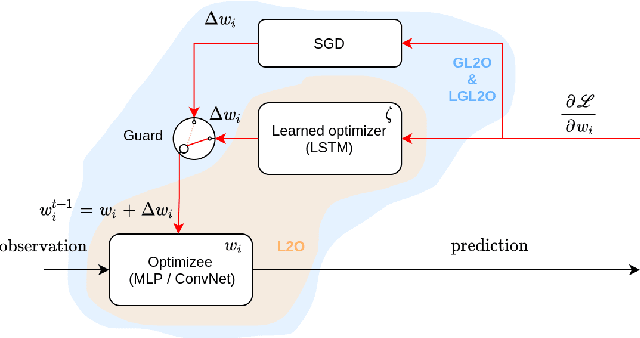

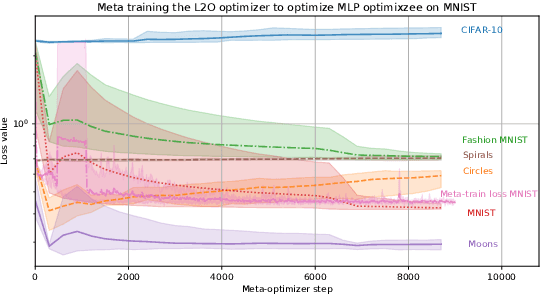
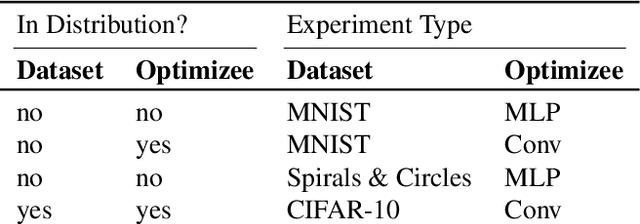
If the trend of learned components eventually outperforming their hand-crafted version continues, learned optimizers will eventually outperform hand-crafted optimizers like SGD or Adam. Even if learned optimizers (L2Os) eventually outpace hand-crafted ones in practice however, they are still not provably convergent and might fail out of distribution. These are the questions addressed here. Currently, learned optimizers frequently outperform generic hand-crafted optimizers (such as gradient descent) at the beginning of learning but they generally plateau after some time while the generic algorithms continue to make progress and often overtake the learned algorithm as Aesop's tortoise which overtakes the hare and are not. L2Os also still have a difficult time generalizing out of distribution. (Heaton et al., 2020) proposed Safeguarded L2O (GL2O) which can take a learned optimizer and safeguard it with a generic learning algorithm so that by conditionally switching between the two, the resulting algorithm is provably convergent. We propose a new class of Safeguarded L2O, called Loss-Guarded L2O (LGL2O), which is both conceptually simpler and computationally less expensive. The guarding mechanism decides solely based on the expected future loss value of both optimizers. Furthermore, we show theoretical proof of LGL2O's convergence guarantee and empirical results comparing to GL2O and other baselines showing that it combines the best of both L2O and SGD and and in practice converges much better than GL2O.
ToyArchitecture: Unsupervised Learning of Interpretable Models of the World
Apr 12, 2019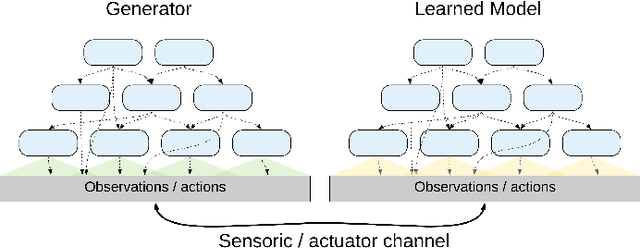
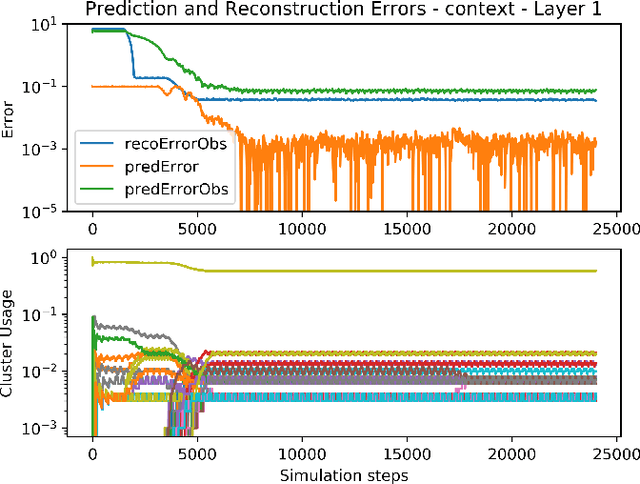
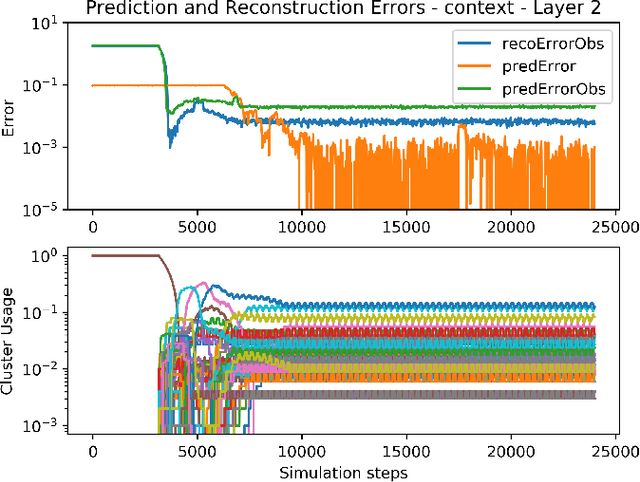
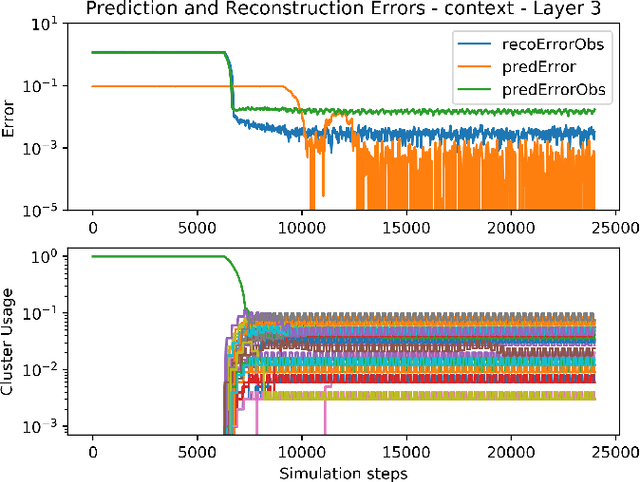
Research in Artificial Intelligence (AI) has focused mostly on two extremes: either on small improvements in narrow AI domains, or on universal theoretical frameworks which are usually uncomputable, incompatible with theories of biological intelligence, or lack practical implementations. The goal of this work is to combine the main advantages of the two: to follow a big picture view, while providing a particular theory and its implementation. In contrast with purely theoretical approaches, the resulting architecture should be usable in realistic settings, but also form the core of a framework containing all the basic mechanisms, into which it should be easier to integrate additional required functionality. In this paper, we present a novel, purposely simple, and interpretable hierarchical architecture which combines multiple different mechanisms into one system: unsupervised learning of a model of the world, learning the influence of one's own actions on the world, model-based reinforcement learning, hierarchical planning and plan execution, and symbolic/sub-symbolic integration in general. The learned model is stored in the form of hierarchical representations with the following properties: 1) they are increasingly more abstract, but can retain details when needed, and 2) they are easy to manipulate in their local and symbolic-like form, thus also allowing one to observe the learning process at each level of abstraction. On all levels of the system, the representation of the data can be interpreted in both a symbolic and a sub-symbolic manner. This enables the architecture to learn efficiently using sub-symbolic methods and to employ symbolic inference.