 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning LLMs with Contrastive Alignment Instructions for Machine Translation in Unseen, Low-resource Languages
Jan 11, 2024This article introduces contrastive alignment instructions (AlignInstruct) to address two challenges in machine translation (MT) on large language models (LLMs). One is the expansion of supported languages to previously unseen ones. The second relates to the lack of data in low-resource languages. Model fine-tuning through MT instructions (MTInstruct) is a straightforward approach to the first challenge. However, MTInstruct is limited by weak cross-lingual signals inherent in the second challenge. AlignInstruct emphasizes cross-lingual supervision via a cross-lingual discriminator built using statistical word alignments. Our results based on fine-tuning the BLOOMZ models (1b1, 3b, and 7b1) in up to 24 unseen languages showed that: (1) LLMs can effectively translate unseen languages using MTInstruct; (2) AlignInstruct led to consistent improvements in translation quality across 48 translation directions involving English; (3) Discriminator-based instructions outperformed their generative counterparts as cross-lingual instructions; (4) AlignInstruct improved performance in 30 zero-shot directions.
Boredom-driven curious learning by Homeo-Heterostatic Value Gradients
Jun 05, 2018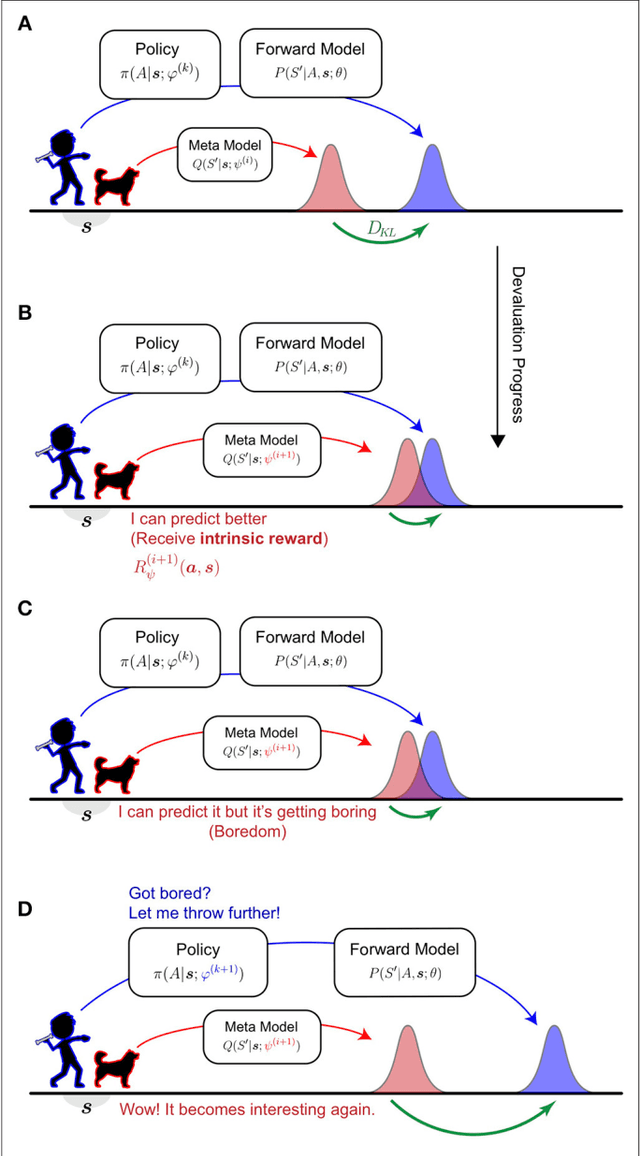


This paper presents the Homeo-Heterostatic Value Gradients (HHVG) algorithm as a formal account on the constructive interplay between boredom and curiosity which gives rise to effective exploration and superior forward model learning. We envisaged actions as instrumental in agent's own epistemic disclosure. This motivated two central algorithmic ingredients: devaluation and devaluation progress, both underpin agent's cognition concerning intrinsically generated rewards. The two serve as an instantiation of homeostatic and heterostatic intrinsic motivation. A key insight from our algorithm is that the two seemingly opposite motivations can be reconciled---without which exploration and information-gathering cannot be effectively carried out. We supported this claim with empirical evidence, showing that boredom-enabled agents consistently outperformed other curious or explorative agent variants in model building benchmarks based on self-assisted experience accumulation.
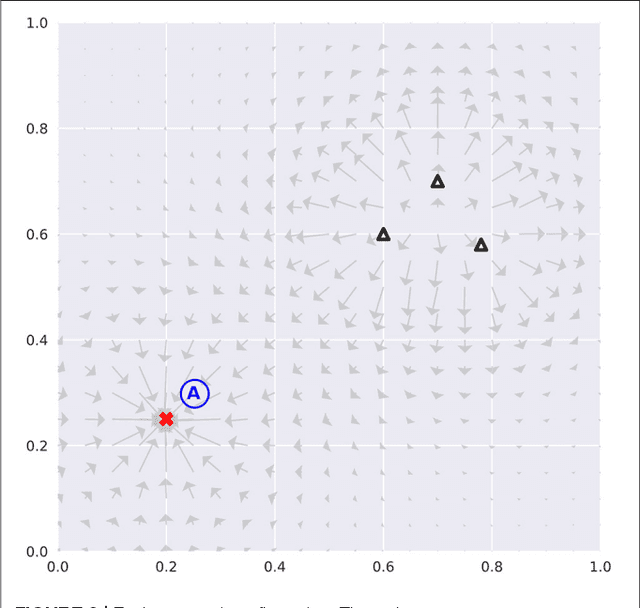
Counterfactual Control for Free from Generative Models
Mar 09, 2017


We introduce a method by which a generative model learning the joint distribution between actions and future states can be used to automatically infer a control scheme for any desired reward function, which may be altered on the fly without retraining the model. In this method, the problem of action selection is reduced to one of gradient descent on the latent space of the generative model, with the model itself providing the means of evaluating outcomes and finding the gradient, much like how the reward network in Deep Q-Networks (DQN) provides gradient information for the action generator. Unlike DQN or Actor-Critic, which are conditional models for a specific reward, using a generative model of the full joint distribution permits the reward to be changed on the fly. In addition, the generated futures can be inspected to gain insight in to what the network 'thinks' will happen, and to what went wrong when the outcomes deviate from prediction.