 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Ecosystem for Open-Domain Customized Video Generation
Jun 10, 2026Recent progress in video generation has shown impressive visual synthesis capabilities. However, open-domain customized video generation remains limited by the lack of large-scale, annotated datasets capturing diverse identity-specific attributes. To address this, we introduce PexelsCustom-1M, the first publicly available million-scale dataset for identity-preserving video generation, containing one million curated <identity, text, video> triplets across 8,000+ categories. Leveraging this, we propose CustoMDiT, a parameter-efficient framework that adapts a pretrained multimodal Diffusion Transformer into a customized video generator with only 8% additional learnable parameters. Our method surpasses prior state-of-the-art. However, benchmarks such as DreamBooth cover only 100 classes, which is insufficient for real-world applications. To overcome this, we construct OpenCustom, a new benchmark with 1,000+ categories, created via cross-dataset knowledge fusion from ImageNet and MS-COCO. Extensive experiments confirm the advantages of both our dataset and model. We will open-source the entire ecosystem--including dataset, pipeline, benchmark, and implementations--to support further research.
Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
Jun 10, 2026Scientific progress depends on a repeated loop of exploration, experimentation, and abstraction. Researchers test candidate directions, interpret the evidence, and carry the resulting lessons into later attempts. We study how an AI agent can run this loop autonomously over long horizons. We introduce Arbor, a general framework for autonomous research that combines a long-lived coordinator, short-lived executors, and Hypothesis Tree Refinement (HTR), a persistent tree that links hypotheses, artifacts, evidence, and distilled insights across time. The coordinator manages global research strategy over the tree, while executors implement and test individual hypotheses in isolated worktrees. As results return, Arbor updates the tree, propagates reusable lessons, refines the search frontier, and admits verified improvements. This design turns autonomous research from a sequence of local attempts into a cumulative process in which strategy, execution, and evidence are carried across time. We evaluate Arbor under Autonomous Optimization (AO), an operational setting where an agent improves an initial research artifact through iterative experimentation without step-level human supervision. Across six real research tasks in model training, harness engineering, and data synthesis, Arbor achieves the best held-out result on all six tasks, attaining more than 2.5x the average relative held-out gain of Codex and Claude Code under the same task interface and resource budget. On MLE-Bench Lite, Arbor reaches 86.36% Any Medal with GPT-5.5, the strongest result in our comparison.
SkillOpt: Executive Strategy for Self-Evolving Agent Skills
May 25, 2026Agent skills today are hand-crafted, generated one-shot, or evolved through loosely controlled self-revision, none of which behaves like a deep-learning optimizer for the skill, and none of which reliably improves over its starting point under feedback. We argue the skill should instead be trained as the external state of a frozen agent, with the same discipline that makes weight-space optimization reproducible. SkillOpt is, to our knowledge, the first systematic controllable text-space optimizer for agent skills: a separate optimizer model turns scored rollouts into bounded add/delete/replace edits on a single skill document, and an edit is accepted only when it strictly improves a held-out validation score. A textual learning-rate budget, rejected-edit buffer, and epoch-wise slow/meta update make skill training stable while adding zero inference-time model calls at deployment. Across six benchmarks, seven target models, and three execution harnesses (direct chat, Codex, Claude Code), SkillOpt is best or tied on all 52 evaluated (model, benchmark, harness) cells and beats every per-cell competitor among human, one-shot LLM, Trace2Skill, TextGrad, GEPA, and EvoSkill skills. On GPT-5.5 it lifts the average no-skill accuracy by +23.5 points in direct chat, by +24.8 inside the Codex agentic loop, and by +19.1 inside Claude Code. Transfer experiments further show that optimized skill artifacts retain value when moved across model scales, between Codex and Claude Code execution environments, and to a nearby math benchmark without further optimization. Code: https://aka.ms/skillopt
From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills
May 22, 2026Language agents increasingly improve by reusing \emph{skills} -- structured procedural artifacts distilled from past experience. In particular, \emph{domain-level} and \emph{model-generated} skills are especially promising. They offer fast adaptation within a domain by encoding domain-specific recurring procedures, and they scale beyond labor-intensive hand-crafting. However, while extraction methods continue to proliferate, understanding remains limited, with no comprehensive study spanning the full skill lifecycle -- \textbf{experience generation}, \textbf{skill extraction}, and \textbf{skill consumption} -- to ask whether such skills actually work, when they work, and what makes them succeed or fail. To close this gap, we build a utility-grounded evaluation framework that provides systematic experimental results across extractors and target agents, covering five diverse agentic task domains. We find that model-generated skills are beneficial on average but exhibit non-trivial negative transfer, and that neither extractors nor targets behave uniformly. A model can be a strong extractor yet a weak consumer, or vice versa, with skill utility independent of model scale or baseline task strength. To explain these patterns, we then dissect each lifecycle stage in depth, analyzing how experience composition shapes skill quality, what properties characterize useful skills, and how the same skill transfers across different consumers. Finally, we translate these findings into a concrete \emph{meta-skill} that guides skill extraction toward the features tied to actual utility, which consistently improves skill quality across domains and substantially reduces negative transfer.
Covering Human Action Space for Computer Use: Data Synthesis and Benchmark
May 12, 2026Computer-use agents (CUAs) automate on-screen work, as illustrated by GPT-5.4 and Claude. Yet their reliability on complex, low-frequency interactions is still poor, limiting user trust. Our analysis of failure cases from advanced models suggests a long-tail pattern in GUI operations, where a relatively small fraction of complex and diverse interactions accounts for a disproportionate share of task failures. We hypothesize that this issue largely stems from the scarcity of data for complex interactions. To address this problem, we propose a new benchmark CUActSpot for evaluating models' capabilities on complex interactions across five modalities: GUI, text, table, canvas, and natural image, as well as a variety of actions (click, drag, draw, etc.), covering a broader range of interaction types than prior click-centric benchmarks that focus mainly on GUI widgets. We also design a renderer-based data-synthesis pipeline: scenes are automatically generated for each modality, screenshots and element coordinates are recorded, and an LLM produces matching instructions and action traces. After training on this corpus, our Phi-Ground-Any-4B outperforms open-source models with fewer than 32B parameters. We will release our benchmark, data, code, and models at https://github.com/microsoft/Phi-Ground.git
RE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
FlashPortrait: 6x Faster Infinite Portrait Animation with Adaptive Latent Prediction
Dec 18, 2025Current diffusion-based acceleration methods for long-portrait animation struggle to ensure identity (ID) consistency. This paper presents FlashPortrait, an end-to-end video diffusion transformer capable of synthesizing ID-preserving, infinite-length videos while achieving up to 6x acceleration in inference speed. In particular, FlashPortrait begins by computing the identity-agnostic facial expression features with an off-the-shelf extractor. It then introduces a Normalized Facial Expression Block to align facial features with diffusion latents by normalizing them with their respective means and variances, thereby improving identity stability in facial modeling. During inference, FlashPortrait adopts a dynamic sliding-window scheme with weighted blending in overlapping areas, ensuring smooth transitions and ID consistency in long animations. In each context window, based on the latent variation rate at particular timesteps and the derivative magnitude ratio among diffusion layers, FlashPortrait utilizes higher-order latent derivatives at the current timestep to directly predict latents at future timesteps, thereby skipping several denoising steps and achieving 6x speed acceleration. Experiments on benchmarks show the effectiveness of FlashPortrait both qualitatively and quantitatively.
Image Tokenizer Needs Post-Training
Sep 15, 2025Recent image generative models typically capture the image distribution in a pre-constructed latent space, relying on a frozen image tokenizer. However, there exists a significant discrepancy between the reconstruction and generation distribution, where current tokenizers only prioritize the reconstruction task that happens before generative training without considering the generation errors during sampling. In this paper, we comprehensively analyze the reason for this discrepancy in a discrete latent space, and, from which, we propose a novel tokenizer training scheme including both main-training and post-training, focusing on improving latent space construction and decoding respectively. During the main training, a latent perturbation strategy is proposed to simulate sampling noises, \ie, the unexpected tokens generated in generative inference. Specifically, we propose a plug-and-play tokenizer training scheme, which significantly enhances the robustness of tokenizer, thus boosting the generation quality and convergence speed, and a novel tokenizer evaluation metric, \ie, pFID, which successfully correlates the tokenizer performance to generation quality. During post-training, we further optimize the tokenizer decoder regarding a well-trained generative model to mitigate the distribution difference between generated and reconstructed tokens. With a $\sim$400M generator, a discrete tokenizer trained with our proposed main training achieves a notable 1.60 gFID and further obtains 1.36 gFID with the additional post-training. Further experiments are conducted to broadly validate the effectiveness of our post-training strategy on off-the-shelf discrete and continuous tokenizers, coupled with autoregressive and diffusion-based generators.
Phi-Ground Tech Report: Advancing Perception in GUI Grounding
Jul 31, 2025



With the development of multimodal reasoning models, Computer Use Agents (CUAs), akin to Jarvis from \textit{"Iron Man"}, are becoming a reality. GUI grounding is a core component for CUAs to execute actual actions, similar to mechanical control in robotics, and it directly leads to the success or failure of the system. It determines actions such as clicking and typing, as well as related parameters like the coordinates for clicks. Current end-to-end grounding models still achieve less than 65\% accuracy on challenging benchmarks like ScreenSpot-pro and UI-Vision, indicating they are far from being ready for deployment. % , as a single misclick can result in unacceptable consequences. In this work, we conduct an empirical study on the training of grounding models, examining details from data collection to model training. Ultimately, we developed the \textbf{Phi-Ground} model family, which achieves state-of-the-art performance across all five grounding benchmarks for models under $10B$ parameters in agent settings. In the end-to-end model setting, our model still achieves SOTA results with scores of \textit{\textbf{43.2}} on ScreenSpot-pro and \textit{\textbf{27.2}} on UI-Vision. We believe that the various details discussed in this paper, along with our successes and failures, not only clarify the construction of grounding models but also benefit other perception tasks. Project homepage: \href{https://zhangmiaosen2000.github.io/Phi-Ground/}{https://zhangmiaosen2000.github.io/Phi-Ground/}
ViaRL: Adaptive Temporal Grounding via Visual Iterated Amplification Reinforcement Learning
May 21, 2025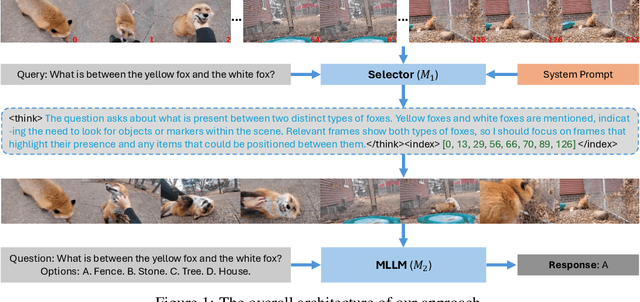
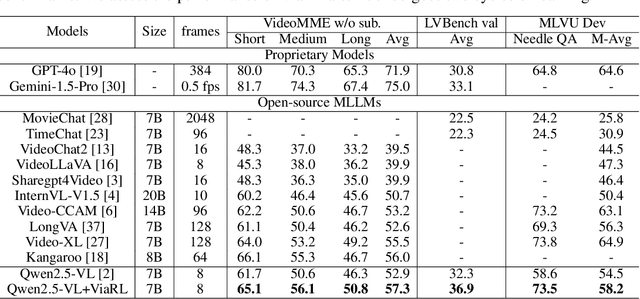
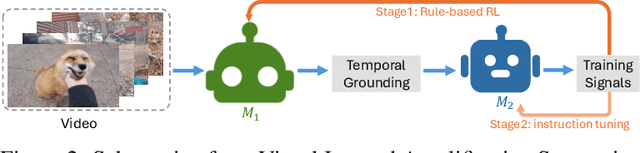

Video understanding is inherently intention-driven-humans naturally focus on relevant frames based on their goals. Recent advancements in multimodal large language models (MLLMs) have enabled flexible query-driven reasoning; however, video-based frameworks like Video Chain-of-Thought lack direct training signals to effectively identify relevant frames. Current approaches often rely on heuristic methods or pseudo-label supervised annotations, which are both costly and limited in scalability across diverse scenarios. To overcome these challenges, we introduce ViaRL, the first framework to leverage rule-based reinforcement learning (RL) for optimizing frame selection in intention-driven video understanding. An iterated amplification strategy is adopted to perform alternating cyclic training in the video CoT system, where each component undergoes iterative cycles of refinement to improve its capabilities. ViaRL utilizes the answer accuracy of a downstream model as a reward signal to train a frame selector through trial-and-error, eliminating the need for expensive annotations while closely aligning with human-like learning processes. Comprehensive experiments across multiple benchmarks, including VideoMME, LVBench, and MLVU, demonstrate that ViaRL consistently delivers superior temporal grounding performance and robust generalization across diverse video understanding tasks, highlighting its effectiveness and scalability. Notably, ViaRL achieves a nearly 15\% improvement on Needle QA, a subset of MLVU, which is required to search a specific needle within a long video and regarded as one of the most suitable benchmarks for evaluating temporal grounding.