 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Time-Series Foundation Models Deployment-Ready? A Systematic Study of Adversarial Robustness Across Domains
May 26, 2025Time Series Foundation Models (TSFMs), which are pretrained on large-scale, cross-domain data and capable of zero-shot forecasting in new scenarios without further training, are increasingly adopted in real-world applications. However, as the zero-shot forecasting paradigm gets popular, a critical yet overlooked question emerges: Are TSFMs robust to adversarial input perturbations? Such perturbations could be exploited in man-in-the-middle attacks or data poisoning. To address this gap, we conduct a systematic investigation into the adversarial robustness of TSFMs. Our results show that even minimal perturbations can induce significant and controllable changes in forecast behaviors, including trend reversal, temporal drift, and amplitude shift, posing serious risks to TSFM-based services. Through experiments on representative TSFMs and multiple datasets, we reveal their consistent vulnerabilities and identify potential architectural designs, such as structural sparsity and multi-task pretraining, that may improve robustness. Our findings offer actionable guidance for designing more resilient forecasting systems and provide a critical assessment of the adversarial robustness of TSFMs.
Scalable In-Context Learning on Tabular Data via Retrieval-Augmented Large Language Models
Feb 05, 2025



Recent studies have shown that large language models (LLMs), when customized with post-training on tabular data, can acquire general tabular in-context learning (TabICL) capabilities. These models are able to transfer effectively across diverse data schemas and different task domains. However, existing LLM-based TabICL approaches are constrained to few-shot scenarios due to the sequence length limitations of LLMs, as tabular instances represented in plain text consume substantial tokens. To address this limitation and enable scalable TabICL for any data size, we propose retrieval-augmented LLMs tailored to tabular data. Our approach incorporates a customized retrieval module, combined with retrieval-guided instruction-tuning for LLMs. This enables LLMs to effectively leverage larger datasets, achieving significantly improved performance across 69 widely recognized datasets and demonstrating promising scaling behavior. Extensive comparisons with state-of-the-art tabular models reveal that, while LLM-based TabICL still lags behind well-tuned numeric models in overall performance, it uncovers powerful algorithms under limited contexts, enhances ensemble diversity, and excels on specific datasets. These unique properties underscore the potential of language as a universal and accessible interface for scalable tabular data learning.
ElasTST: Towards Robust Varied-Horizon Forecasting with Elastic Time-Series Transformer
Nov 04, 2024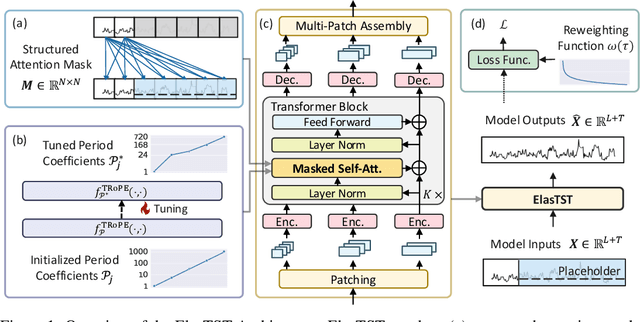
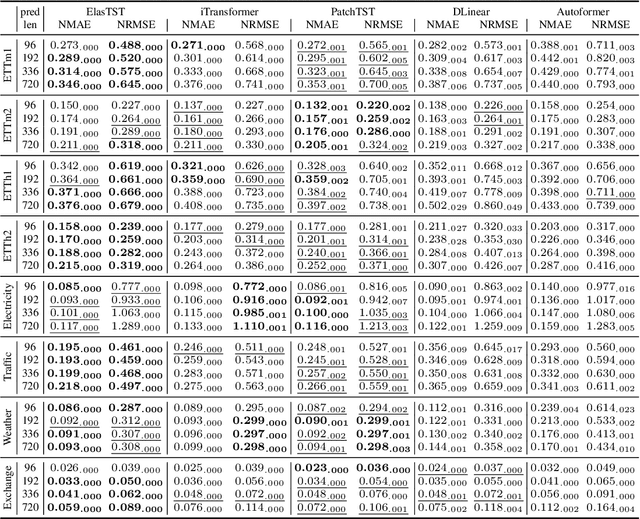
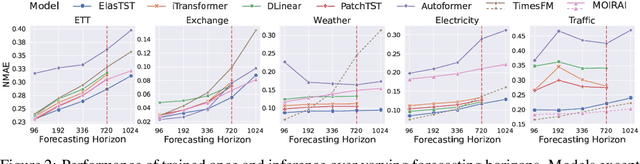
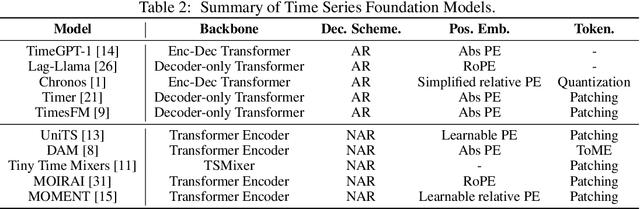
Numerous industrial sectors necessitate models capable of providing robust forecasts across various horizons. Despite the recent strides in crafting specific architectures for time-series forecasting and developing pre-trained universal models, a comprehensive examination of their capability in accommodating varied-horizon forecasting during inference is still lacking. This paper bridges this gap through the design and evaluation of the Elastic Time-Series Transformer (ElasTST). The ElasTST model incorporates a non-autoregressive design with placeholders and structured self-attention masks, warranting future outputs that are invariant to adjustments in inference horizons. A tunable version of rotary position embedding is also integrated into ElasTST to capture time-series-specific periods and enhance adaptability to different horizons. Additionally, ElasTST employs a multi-scale patch design, effectively integrating both fine-grained and coarse-grained information. During the training phase, ElasTST uses a horizon reweighting strategy that approximates the effect of random sampling across multiple horizons with a single fixed horizon setting. Through comprehensive experiments and comparisons with state-of-the-art time-series architectures and contemporary foundation models, we demonstrate the efficacy of ElasTST's unique design elements. Our findings position ElasTST as a robust solution for the practical necessity of varied-horizon forecasting.
Large Language Model as a Universal Clinical Multi-task Decoder
Jun 18, 2024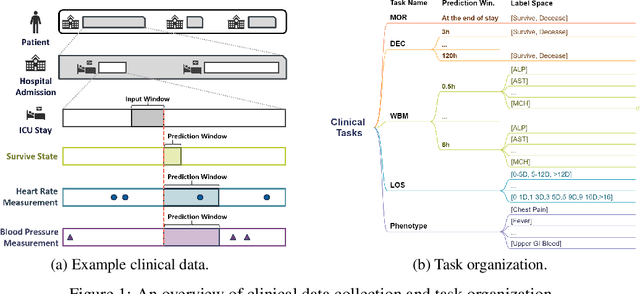
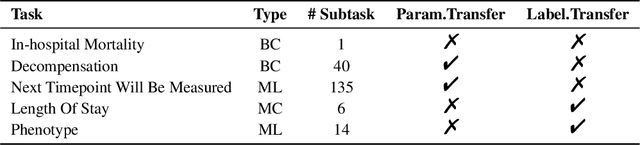
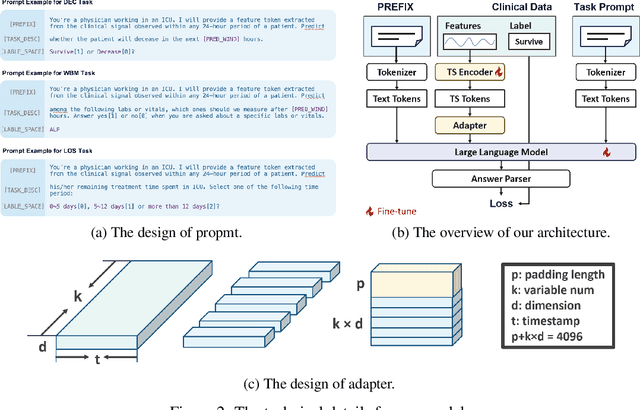
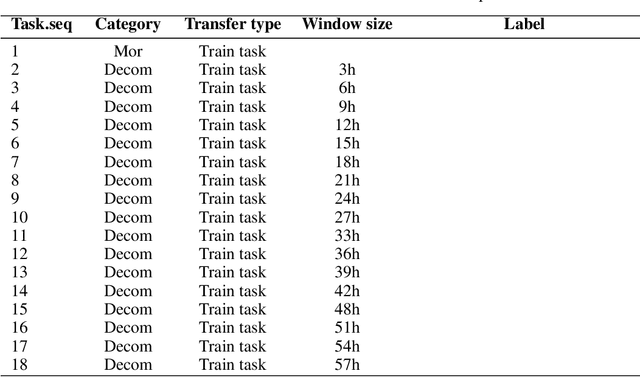
The development of effective machine learning methodologies for enhancing the efficiency and accuracy of clinical systems is crucial. Despite significant research efforts, managing a plethora of diversified clinical tasks and adapting to emerging new tasks remain significant challenges. This paper presents a novel paradigm that employs a pre-trained large language model as a universal clinical multi-task decoder. This approach leverages the flexibility and diversity of language expressions to handle task topic variations and associated arguments. The introduction of a new task simply requires the addition of a new instruction template. We validate this framework across hundreds of tasks, demonstrating its robustness in facilitating multi-task predictions, performing on par with traditional multi-task learning and single-task learning approaches. Moreover, it shows exceptional adaptability to new tasks, with impressive zero-shot performance in some instances and superior data efficiency in few-shot scenarios. This novel approach offers a unified solution to manage a wide array of new and emerging tasks in clinical applications.
Towards Foundation Models for Learning on Tabular Data
Oct 22, 2023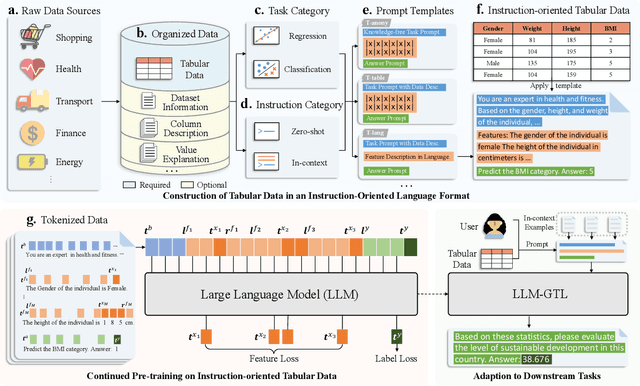
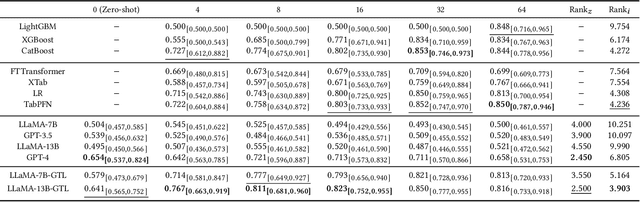

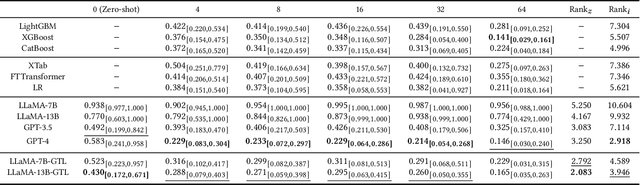
Learning on tabular data underpins numerous real-world applications. Despite considerable efforts in developing effective learning models for tabular data, current transferable tabular models remain in their infancy, limited by either the lack of support for direct instruction following in new tasks or the neglect of acquiring foundational knowledge and capabilities from diverse tabular datasets. In this paper, we propose Tabular Foundation Models (TabFMs) to overcome these limitations. TabFMs harness the potential of generative tabular learning, employing a pre-trained large language model (LLM) as the base model and fine-tuning it using purpose-designed objectives on an extensive range of tabular datasets. This approach endows TabFMs with a profound understanding and universal capabilities essential for learning on tabular data. Our evaluations underscore TabFM's effectiveness: not only does it significantly excel in instruction-following tasks like zero-shot and in-context inference, but it also showcases performance that approaches, and in instances, even transcends, the renowned yet mysterious closed-source LLMs like GPT-4. Furthermore, when fine-tuning with scarce data, our model achieves remarkable efficiency and maintains competitive performance with abundant training data. Finally, while our results are promising, we also delve into TabFM's limitations and potential opportunities, aiming to stimulate and expedite future research on developing more potent TabFMs.
NuTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining
Oct 12, 2023Recent research on time-series self-supervised models shows great promise in learning semantic representations. However, it has been limited to small-scale datasets, e.g., thousands of temporal sequences. In this work, we make key technical contributions that are tailored to the numerical properties of time-series data and allow the model to scale to large datasets, e.g., millions of temporal sequences. We adopt the Transformer architecture by first partitioning the input into non-overlapping windows. Each window is then characterized by its normalized shape and two scalar values denoting the mean and standard deviation within each window. To embed scalar values that may possess arbitrary numerical scales to high-dimensional vectors, we propose a numerically multi-scaled embedding module enumerating all possible scales for the scalar values. The model undergoes pretraining using the proposed numerically multi-scaled embedding with a simple contrastive objective on a large-scale dataset containing over a million sequences. We study its transfer performance on a number of univariate and multivariate classification benchmarks. Our method exhibits remarkable improvement against previous representation learning approaches and establishes the new state of the art, even compared with domain-specific non-learning-based methods.
ProbTS: A Unified Toolkit to Probe Deep Time-series Forecasting
Oct 11, 2023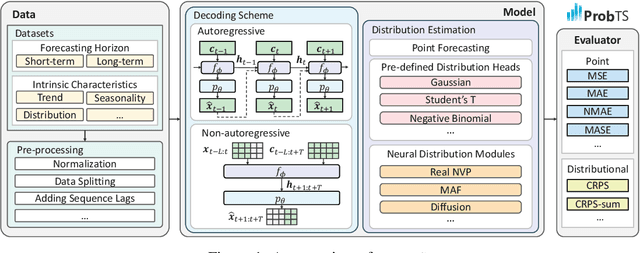
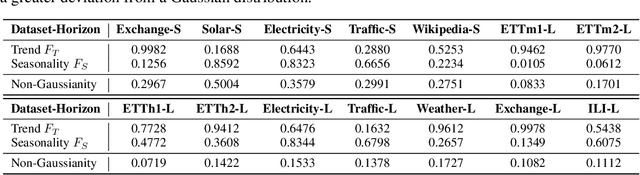
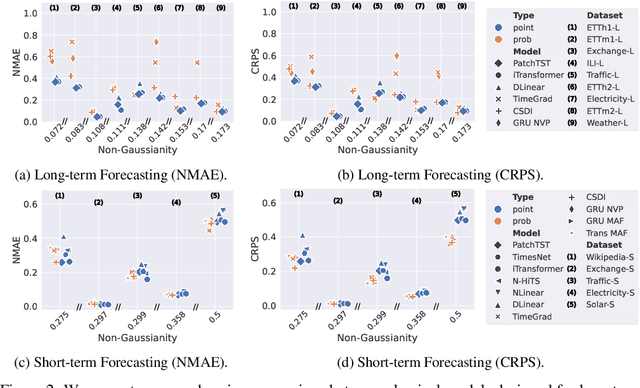
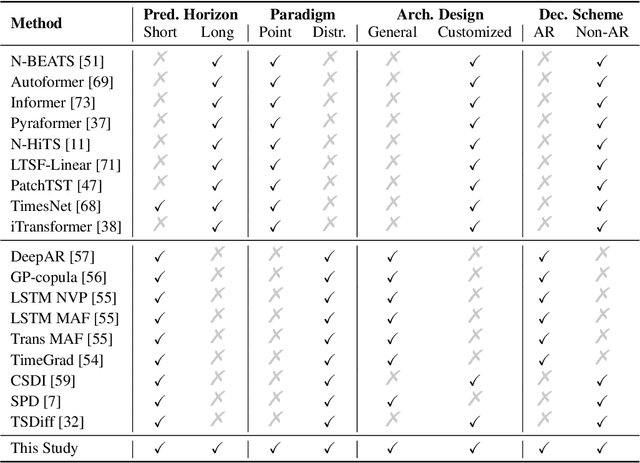
Time-series forecasting serves as a linchpin in a myriad of applications, spanning various domains. With the growth of deep learning, this arena has bifurcated into two salient branches: one focuses on crafting specific neural architectures tailored for time series, and the other harnesses advanced deep generative models for probabilistic forecasting. While both branches have made significant progress, their differences across data scenarios, methodological focuses, and decoding schemes pose profound, yet unexplored, research questions. To bridge this knowledge chasm, we introduce ProbTS, a pioneering toolkit developed to synergize and compare these two distinct branches. Endowed with a unified data module, a modularized model module, and a comprehensive evaluator module, ProbTS allows us to revisit and benchmark leading methods from both branches. The scrutiny with ProbTS highlights their distinct characteristics, relative strengths and weaknesses, and areas that need further exploration. Our analyses point to new avenues for research, aiming for more effective time-series forecasting.