 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTidyBot++: An Open-Source Holonomic Mobile Manipulator for Robot Learning
Dec 11, 2024
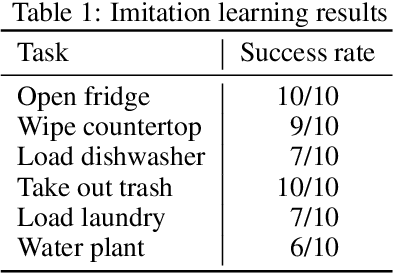
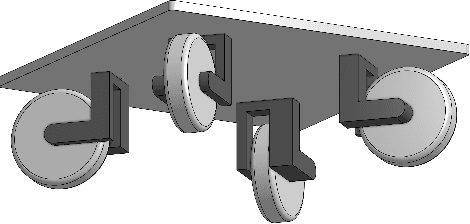

Exploiting the promise of recent advances in imitation learning for mobile manipulation will require the collection of large numbers of human-guided demonstrations. This paper proposes an open-source design for an inexpensive, robust, and flexible mobile manipulator that can support arbitrary arms, enabling a wide range of real-world household mobile manipulation tasks. Crucially, our design uses powered casters to enable the mobile base to be fully holonomic, able to control all planar degrees of freedom independently and simultaneously. This feature makes the base more maneuverable and simplifies many mobile manipulation tasks, eliminating the kinematic constraints that create complex and time-consuming motions in nonholonomic bases. We equip our robot with an intuitive mobile phone teleoperation interface to enable easy data acquisition for imitation learning. In our experiments, we use this interface to collect data and show that the resulting learned policies can successfully perform a variety of common household mobile manipulation tasks.
Hand Pose Estimation with Mems-Ultrasonic Sensors
Jun 22, 2023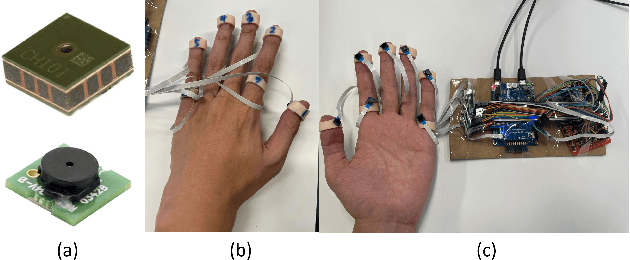

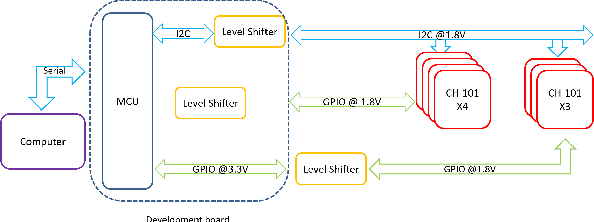
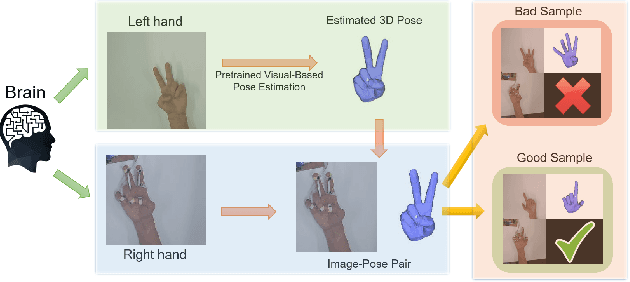
Hand tracking is an important aspect of human-computer interaction and has a wide range of applications in extended reality devices. However, current hand motion capture methods suffer from various limitations. For instance, visual-based hand pose estimation is susceptible to self-occlusion and changes in lighting conditions, while IMU-based tracking gloves experience significant drift and are not resistant to external magnetic field interference. To address these issues, we propose a novel and low-cost hand-tracking glove that utilizes several MEMS-ultrasonic sensors attached to the fingers, to measure the distance matrix among the sensors. Our lightweight deep network then reconstructs the hand pose from the distance matrix. Our experimental results demonstrate that this approach is both accurate, size-agnostic, and robust to external interference. We also show the design logic for the sensor selection, sensor configurations, circuit diagram, as well as model architecture.
TidyBot: Personalized Robot Assistance with Large Language Models
May 09, 2023For a robot to personalize physical assistance effectively, it must learn user preferences that can be generally reapplied to future scenarios. In this work, we investigate personalization of household cleanup with robots that can tidy up rooms by picking up objects and putting them away. A key challenge is determining the proper place to put each object, as people's preferences can vary greatly depending on personal taste or cultural background. For instance, one person may prefer storing shirts in the drawer, while another may prefer them on the shelf. We aim to build systems that can learn such preferences from just a handful of examples via prior interactions with a particular person. We show that robots can combine language-based planning and perception with the few-shot summarization capabilities of large language models (LLMs) to infer generalized user preferences that are broadly applicable to future interactions. This approach enables fast adaptation and achieves 91.2% accuracy on unseen objects in our benchmark dataset. We also demonstrate our approach on a real-world mobile manipulator called TidyBot, which successfully puts away 85.0% of objects in real-world test scenarios.
Clutter Detection and Removal in 3D Scenes with View-Consistent Inpainting
Apr 07, 2023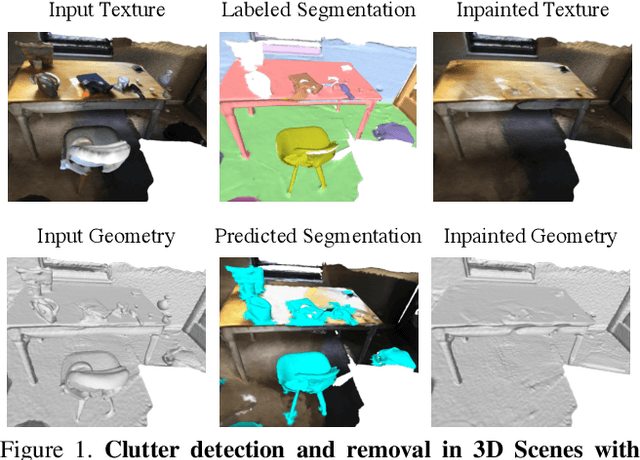

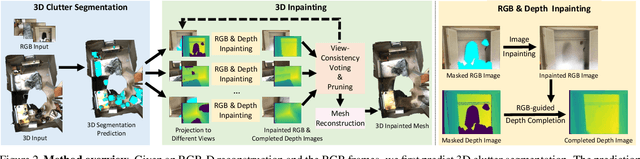
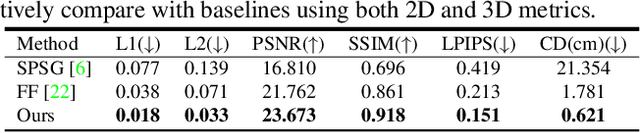
Removing clutter from scenes is essential in many applications, ranging from privacy-concerned content filtering to data augmentation. In this work, we present an automatic system that removes clutter from 3D scenes and inpaints with coherent geometry and texture. We propose techniques for its two key components: 3D segmentation from shared properties and 3D inpainting, both of which are important porblems. The definition of 3D scene clutter (frequently-moving objects) is not well captured by commonly-studied object categories in computer vision. To tackle the lack of well-defined clutter annotations, we group noisy fine-grained labels, leverage virtual rendering, and impose an instance-level area-sensitive loss. Once clutter is removed, we inpaint geometry and texture in the resulting holes by merging inpainted RGB-D images. This requires novel voting and pruning strategies that guarantee multi-view consistency across individually inpainted images for mesh reconstruction. Experiments on ScanNet and Matterport dataset show that our method outperforms baselines for clutter segmentation and 3D inpainting, both visually and quantitatively.
Differentiable Point-Based Radiance Fields for Efficient View Synthesis
Jun 08, 2022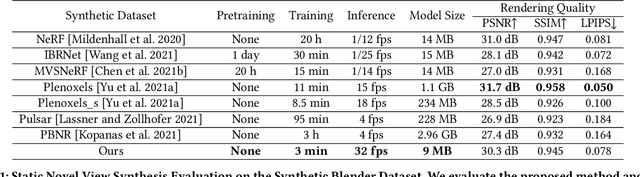
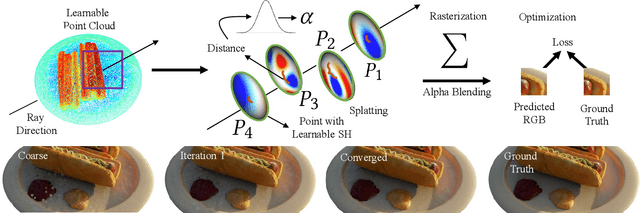
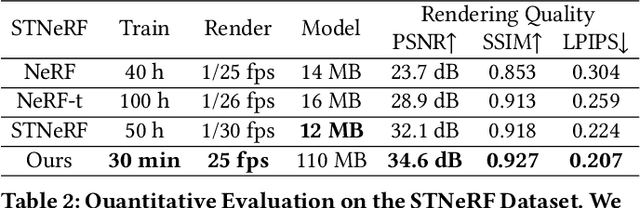

We propose a differentiable rendering algorithm for efficient novel view synthesis. By departing from volume-based representations in favor of a learned point representation, we improve on existing methods more than an order of magnitude in memory and runtime, both in training and inference. The method begins with a uniformly-sampled random point cloud and learns per-point position and view-dependent appearance, using a differentiable splat-based renderer to evolve the model to match a set of input images. Our method is up to 300x faster than NeRF in both training and inference, with only a marginal sacrifice in quality, while using less than 10~MB of memory for a static scene. For dynamic scenes, our method trains two orders of magnitude faster than STNeRF and renders at near interactive rate, while maintaining high image quality and temporal coherence even without imposing any temporal-coherency regularizers.
Self-supervised Neural Articulated Shape and Appearance Models
May 17, 2022


Learning geometry, motion, and appearance priors of object classes is important for the solution of a large variety of computer vision problems. While the majority of approaches has focused on static objects, dynamic objects, especially with controllable articulation, are less explored. We propose a novel approach for learning a representation of the geometry, appearance, and motion of a class of articulated objects given only a set of color images as input. In a self-supervised manner, our novel representation learns shape, appearance, and articulation codes that enable independent control of these semantic dimensions. Our model is trained end-to-end without requiring any articulation annotations. Experiments show that our approach performs well for different joint types, such as revolute and prismatic joints, as well as different combinations of these joints. Compared to state of the art that uses direct 3D supervision and does not output appearance, we recover more faithful geometry and appearance from 2D observations only. In addition, our representation enables a large variety of applications, such as few-shot reconstruction, the generation of novel articulations, and novel view-synthesis.
Learning Pneumatic Non-Prehensile Manipulation with a Mobile Blower
Apr 05, 2022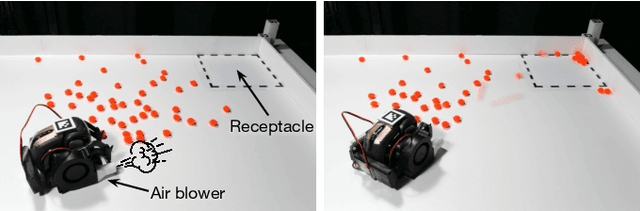
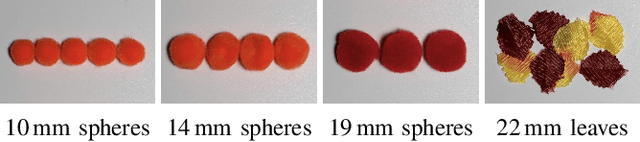

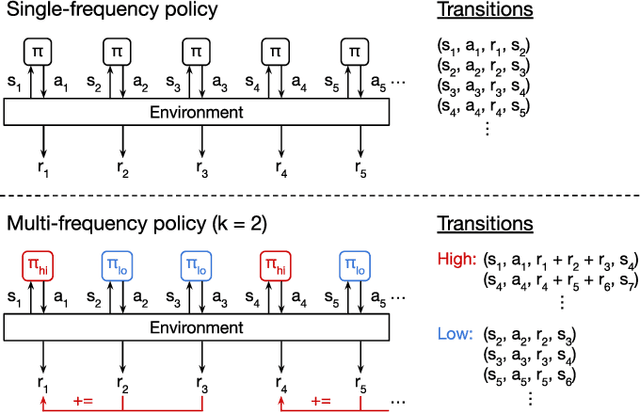
We investigate pneumatic non-prehensile manipulation (i.e., blowing) as a means of efficiently moving scattered objects into a target receptacle. Due to the chaotic nature of aerodynamic forces, a blowing controller must (i) continually adapt to unexpected changes from its actions, (ii) maintain fine-grained control, since the slightest misstep can result in large unintended consequences (e.g., scatter objects already in a pile), and (iii) infer long-range plans (e.g., move the robot to strategic blowing locations). We tackle these challenges in the context of deep reinforcement learning, introducing a multi-frequency version of the spatial action maps framework. This allows for efficient learning of vision-based policies that effectively combine high-level planning and low-level closed-loop control for dynamic mobile manipulation. Experiments show that our system learns efficient behaviors for the task, demonstrating in particular that blowing achieves better downstream performance than pushing, and that our policies improve performance over baselines. Moreover, we show that our system naturally encourages emergent specialization between the different subpolicies spanning low-level fine-grained control and high-level planning. On a real mobile robot equipped with a miniature air blower, we show that our simulation-trained policies transfer well to a real environment and can generalize to novel objects.
Spatial Intention Maps for Multi-Agent Mobile Manipulation
Mar 23, 2021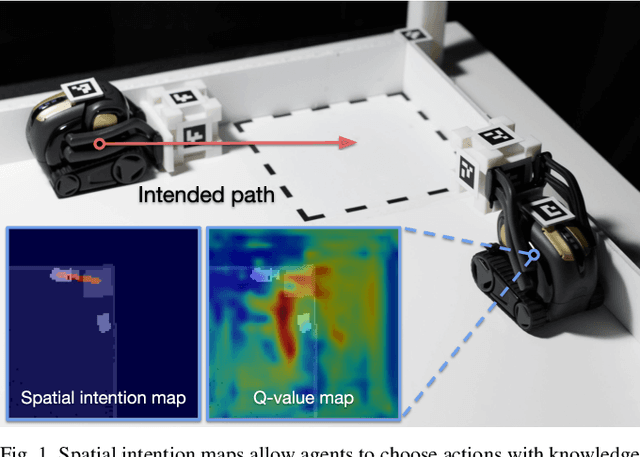
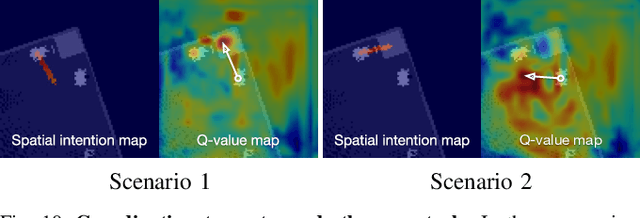
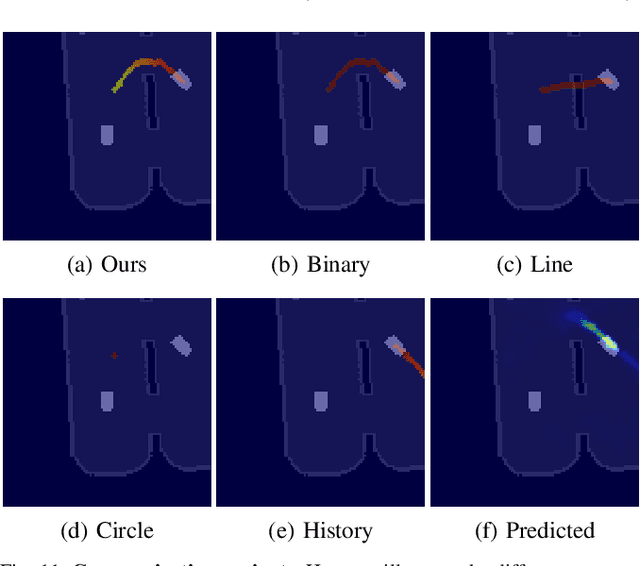
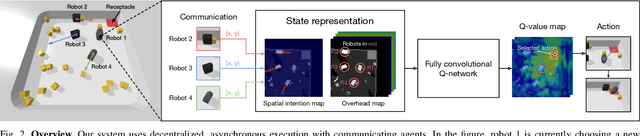
The ability to communicate intention enables decentralized multi-agent robots to collaborate while performing physical tasks. In this work, we present spatial intention maps, a new intention representation for multi-agent vision-based deep reinforcement learning that improves coordination between decentralized mobile manipulators. In this representation, each agent's intention is provided to other agents, and rendered into an overhead 2D map aligned with visual observations. This synergizes with the recently proposed spatial action maps framework, in which state and action representations are spatially aligned, providing inductive biases that encourage emergent cooperative behaviors requiring spatial coordination, such as passing objects to each other or avoiding collisions. Experiments across a variety of multi-agent environments, including heterogeneous robot teams with different abilities (lifting, pushing, or throwing), show that incorporating spatial intention maps improves performance for different mobile manipulation tasks while significantly enhancing cooperative behaviors.
Learning to Infer Semantic Parameters for 3D Shape Editing
Nov 09, 2020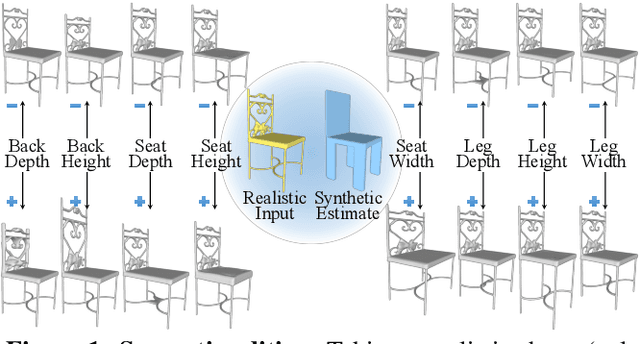

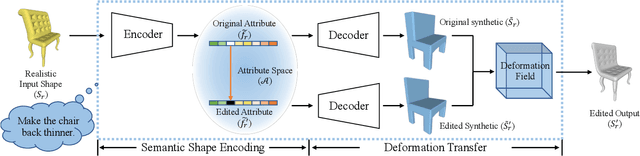
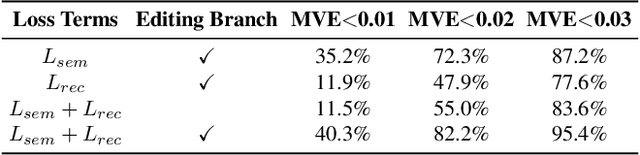
Many applications in 3D shape design and augmentation require the ability to make specific edits to an object's semantic parameters (e.g., the pose of a person's arm or the length of an airplane's wing) while preserving as much existing details as possible. We propose to learn a deep network that infers the semantic parameters of an input shape and then allows the user to manipulate those parameters. The network is trained jointly on shapes from an auxiliary synthetic template and unlabeled realistic models, ensuring robustness to shape variability while relieving the need to label realistic exemplars. At testing time, edits within the parameter space drive deformations to be applied to the original shape, which provides semantically-meaningful manipulation while preserving the details. This is in contrast to prior methods that either use autoencoders with a limited latent-space dimensionality, failing to preserve arbitrary detail, or drive deformations with purely-geometric controls, such as cages, losing the ability to update local part regions. Experiments with datasets of chairs, airplanes, and human bodies demonstrate that our method produces more natural edits than prior work.
SymmetryNet: Learning to Predict Reflectional and Rotational Symmetries of 3D Shapes from Single-View RGB-D Images
Aug 30, 2020
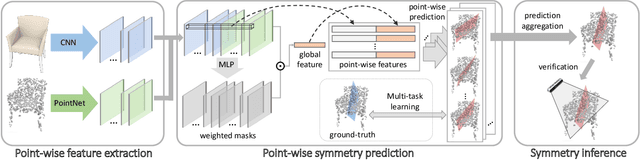
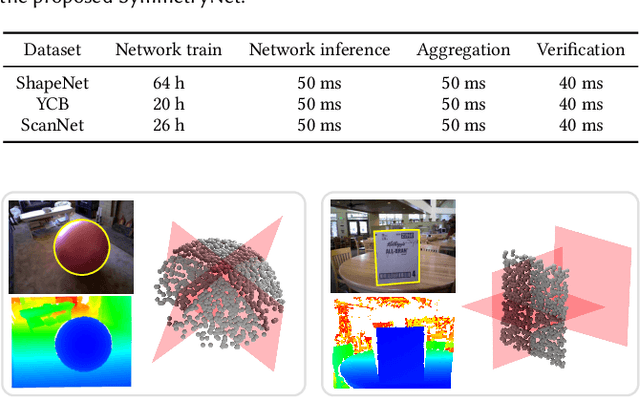
We study the problem of symmetry detection of 3D shapes from single-view RGB-D images, where severely missing data renders geometric detection approach infeasible. We propose an end-to-end deep neural network which is able to predict both reflectional and rotational symmetries of 3D objects present in the input RGB-D image. Directly training a deep model for symmetry prediction, however, can quickly run into the issue of overfitting. We adopt a multi-task learning approach. Aside from symmetry axis prediction, our network is also trained to predict symmetry correspondences. In particular, given the 3D points present in the RGB-D image, our network outputs for each 3D point its symmetric counterpart corresponding to a specific predicted symmetry. In addition, our network is able to detect for a given shape multiple symmetries of different types. We also contribute a benchmark of 3D symmetry detection based on single-view RGB-D images. Extensive evaluation on the benchmark demonstrates the strong generalization ability of our method, in terms of high accuracy of both symmetry axis prediction and counterpart estimation. In particular, our method is robust in handling unseen object instances with large variation in shape, multi-symmetry composition, as well as novel object categories.
* 15 pages