 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO2: A unified pre-training framework for online and offline speech recognition
Paper and Code
Oct 26, 2022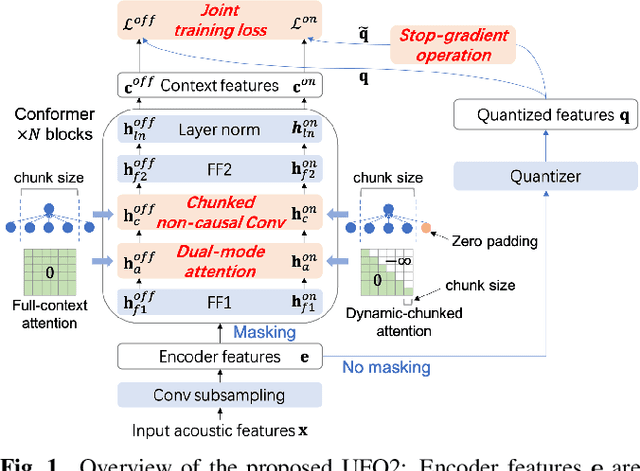
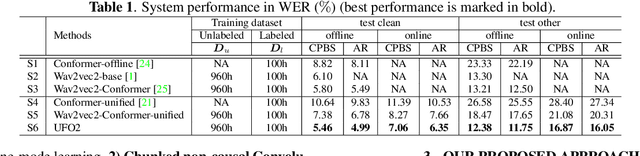

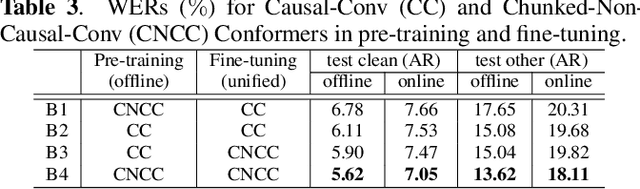
In this paper, we propose a Unified pre-training Framework for Online and Offline (UFO2) Automatic Speech Recognition (ASR), which 1) simplifies the two separate training workflows for online and offline modes into one process, and 2) improves the Word Error Rate (WER) performance with limited utterance annotating. Specifically, we extend the conventional offline-mode Self-Supervised Learning (SSL)-based ASR approach to a unified manner, where the model training is conditioned on both the full-context and dynamic-chunked inputs. To enhance the pre-trained representation model, stop-gradient operation is applied to decouple the online-mode objectives to the quantizer. Moreover, in both the pre-training and the downstream fine-tuning stages, joint losses are proposed to train the unified model with full-weight sharing for the two modes. Experimental results on the LibriSpeech dataset show that UFO2 outperforms the SSL-based baseline method by 29.7% and 18.2% relative WER reduction in offline and online modes, respectively.