 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUME: Upcycling Mixture-of-Experts for Scalable and Efficient Automatic Speech Recognition
Paper and Code
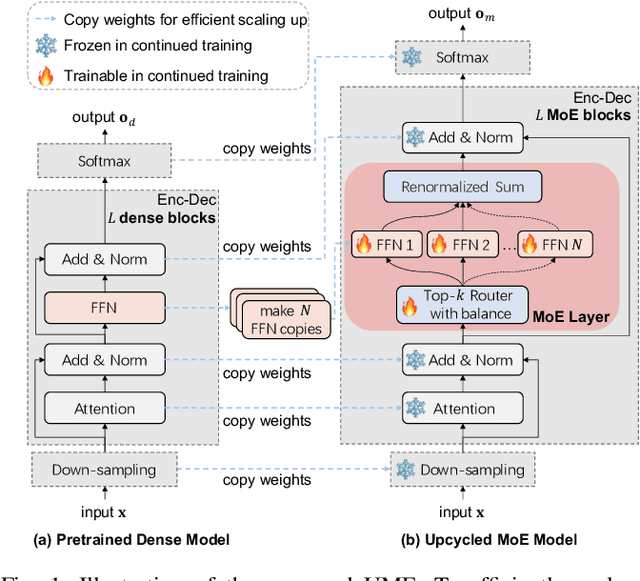
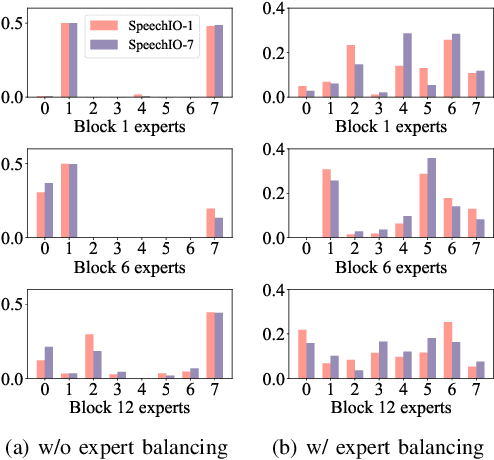

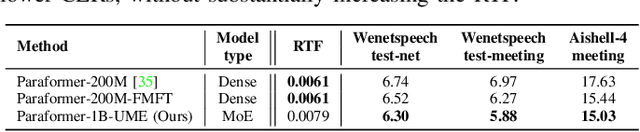
Recent advancements in scaling up models have significantly improved performance in Automatic Speech Recognition (ASR) tasks. However, training large ASR models from scratch remains costly. To address this issue, we introduce UME, a novel method that efficiently Upcycles pretrained dense ASR checkpoints into larger Mixture-of-Experts (MoE) architectures. Initially, feed-forward networks are converted into MoE layers. By reusing the pretrained weights, we establish a robust foundation for the expanded model, significantly reducing optimization time. Then, layer freezing and expert balancing strategies are employed to continue training the model, further enhancing performance. Experiments on a mixture of 170k-hour Mandarin and English datasets show that UME: 1) surpasses the pretrained baseline by a margin of 11.9% relative error rate reduction while maintaining comparable latency; 2) reduces training time by up to 86.7% and achieves superior accuracy compared to training models of the same size from scratch.