 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoKI: Low-damage Knowledge Implanting of Large Language Models
May 28, 2025Fine-tuning adapts pretrained models for specific tasks but poses the risk of catastrophic forgetting (CF), where critical knowledge from pre-training is overwritten. Current Parameter-Efficient Fine-Tuning (PEFT) methods for Large Language Models (LLMs), while efficient, often sacrifice general capabilities. To address the issue of CF in a general-purpose PEFT framework, we propose \textbf{Lo}w-damage \textbf{K}nowledge \textbf{I}mplanting (\textbf{LoKI}), a PEFT technique that is based on a mechanistic understanding of how knowledge is stored in transformer architectures. In two real-world scenarios, LoKI demonstrates task-specific performance that is comparable to or even surpasses that of full fine-tuning and LoRA-based methods across various model types, while significantly better preserving general capabilities. Our work connects mechanistic insights into LLM knowledge storage with practical fine-tuning objectives, achieving state-of-the-art trade-offs between task specialization and the preservation of general capabilities. Our implementation is publicly available as ready-to-use code\footnote{https://github.com/Nexround/LoKI}.
SCaLa: Supervised Contrastive Learning for End-to-End Automatic Speech Recognition
Oct 08, 2021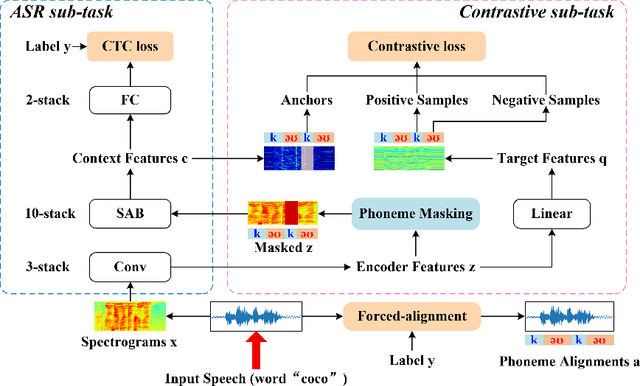
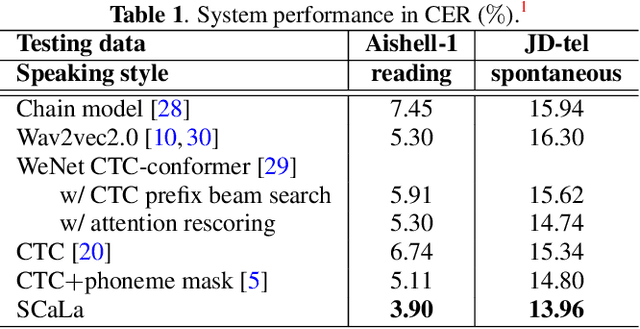
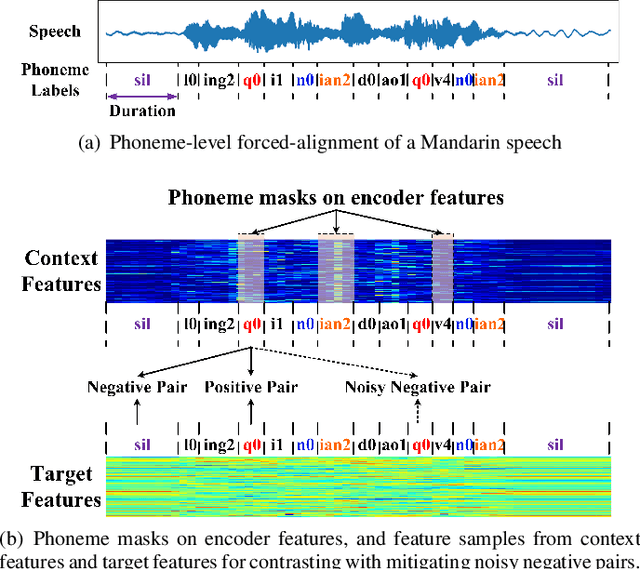
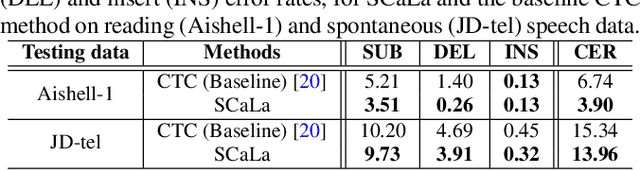
End-to-end Automatic Speech Recognition (ASR) models are usually trained to reduce the losses of the whole token sequences, while neglecting explicit phonemic-granularity supervision. This could lead to recognition errors due to similar-phoneme confusion or phoneme reduction. To alleviate this problem, this paper proposes a novel framework of Supervised Contrastive Learning (SCaLa) to enhance phonemic information learning for end-to-end ASR systems. Specifically, we introduce the self-supervised Masked Contrastive Predictive Coding (MCPC) into the fully-supervised setting. To supervise phoneme learning explicitly, SCaLa first masks the variable-length encoder features corresponding to phonemes given phoneme forced-alignment extracted from a pre-trained acoustic model, and then predicts the masked phonemes via contrastive learning. The phoneme forced-alignment can mitigate the noise of positive-negative pairs in self-supervised MCPC. Experimental results conducted on reading and spontaneous speech datasets show that the proposed approach achieves 2.84% and 1.38% Character Error Rate (CER) reductions compared to the baseline, respectively.