 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination as a Computational Boundary: A Hierarchy of Inevitability and the Oracle Escape
Aug 10, 2025The illusion phenomenon of large language models (LLMs) is the core obstacle to their reliable deployment. This article formalizes the large language model as a probabilistic Turing machine by constructing a "computational necessity hierarchy", and for the first time proves the illusions are inevitable on diagonalization, incomputability, and information theory boundaries supported by the new "learner pump lemma". However, we propose two "escape routes": one is to model Retrieval Enhanced Generations (RAGs) as oracle machines, proving their absolute escape through "computational jumps", providing the first formal theory for the effectiveness of RAGs; The second is to formalize continuous learning as an "internalized oracle" mechanism and implement this path through a novel neural game theory framework.Finally, this article proposes a
Multi-Agent Synergy-Driven Iterative Visual Narrative Synthesis
Jul 17, 2025Automated generation of high-quality media presentations is challenging, requiring robust content extraction, narrative planning, visual design, and overall quality optimization. Existing methods often produce presentations with logical inconsistencies and suboptimal layouts, thereby struggling to meet professional standards. To address these challenges, we introduce RCPS (Reflective Coherent Presentation Synthesis), a novel framework integrating three key components: (1) Deep Structured Narrative Planning; (2) Adaptive Layout Generation; (3) an Iterative Optimization Loop. Additionally, we propose PREVAL, a preference-based evaluation framework employing rationale-enhanced multi-dimensional models to assess presentation quality across Content, Coherence, and Design. Experimental results demonstrate that RCPS significantly outperforms baseline methods across all quality dimensions, producing presentations that closely approximate human expert standards. PREVAL shows strong correlation with human judgments, validating it as a reliable automated tool for assessing presentation quality.
When Models Know More Than They Can Explain: Quantifying Knowledge Transfer in Human-AI Collaboration
Jun 05, 2025Recent advancements in AI reasoning have driven substantial improvements across diverse tasks. A critical open question is whether these improvements also yields better knowledge transfer: the ability of models to communicate reasoning in ways humans can understand, apply, and learn from. To investigate this, we introduce Knowledge Integration and Transfer Evaluation (KITE), a conceptual and experimental framework for Human-AI knowledge transfer capabilities and conduct the first large-scale human study (N=118) explicitly designed to measure it. In our two-phase setup, humans first ideate with an AI on problem-solving strategies, then independently implement solutions, isolating model explanations' influence on human understanding. Our findings reveal that although model benchmark performance correlates with collaborative outcomes, this relationship is notably inconsistent, featuring significant outliers, indicating that knowledge transfer requires dedicated optimization. Our analysis identifies behavioral and strategic factors mediating successful knowledge transfer. We release our code, dataset, and evaluation framework to support future work on communicatively aligned models.
LoKI: Low-damage Knowledge Implanting of Large Language Models
May 28, 2025Fine-tuning adapts pretrained models for specific tasks but poses the risk of catastrophic forgetting (CF), where critical knowledge from pre-training is overwritten. Current Parameter-Efficient Fine-Tuning (PEFT) methods for Large Language Models (LLMs), while efficient, often sacrifice general capabilities. To address the issue of CF in a general-purpose PEFT framework, we propose \textbf{Lo}w-damage \textbf{K}nowledge \textbf{I}mplanting (\textbf{LoKI}), a PEFT technique that is based on a mechanistic understanding of how knowledge is stored in transformer architectures. In two real-world scenarios, LoKI demonstrates task-specific performance that is comparable to or even surpasses that of full fine-tuning and LoRA-based methods across various model types, while significantly better preserving general capabilities. Our work connects mechanistic insights into LLM knowledge storage with practical fine-tuning objectives, achieving state-of-the-art trade-offs between task specialization and the preservation of general capabilities. Our implementation is publicly available as ready-to-use code\footnote{https://github.com/Nexround/LoKI}.
IMPersona: Evaluating Individual Level LM Impersonation
Apr 08, 2025As language models achieve increasingly human-like capabilities in conversational text generation, a critical question emerges: to what extent can these systems simulate the characteristics of specific individuals? To evaluate this, we introduce IMPersona, a framework for evaluating LMs at impersonating specific individuals' writing style and personal knowledge. Using supervised fine-tuning and a hierarchical memory-inspired retrieval system, we demonstrate that even modestly sized open-source models, such as Llama-3.1-8B-Instruct, can achieve impersonation abilities at concerning levels. In blind conversation experiments, participants (mis)identified our fine-tuned models with memory integration as human in 44.44% of interactions, compared to just 25.00% for the best prompting-based approach. We analyze these results to propose detection methods and defense strategies against such impersonation attempts. Our findings raise important questions about both the potential applications and risks of personalized language models, particularly regarding privacy, security, and the ethical deployment of such technologies in real-world contexts.
Atom of Thoughts for Markov LLM Test-Time Scaling
Feb 17, 2025Large Language Models (LLMs) achieve superior performance through training-time scaling, and test-time scaling further enhances their capabilities by conducting effective reasoning during inference. However, as the scale of reasoning increases, existing test-time scaling methods suffer from accumulated historical information, which not only wastes computational resources but also interferes with effective reasoning. To address this issue, we observe that complex reasoning progress is often achieved by solving a sequence of independent subquestions, each being self-contained and verifiable. These subquestions are essentially atomic questions, relying primarily on their current state rather than accumulated history, similar to the memoryless transitions in a Markov process. Based on this observation, we propose Atom of Thoughts (AoT), where each state transition in the reasoning process consists of decomposing the current question into a dependency-based directed acyclic graph and contracting its subquestions, forming a new atomic question state. This iterative decomposition-contraction process continues until reaching directly solvable atomic questions, naturally realizing Markov transitions between question states. Furthermore, these atomic questions can be seamlessly integrated into existing test-time scaling methods, enabling AoT to serve as a plug-in enhancement for improving reasoning capabilities. Experiments across six benchmarks demonstrate the effectiveness of AoT both as a standalone framework and a plug-in enhancement. Notably, on HotpotQA, when applied to gpt-4o-mini, AoT achieves an 80.6% F1 score, surpassing o3-mini by 3.4% and DeepSeek-R1 by 10.6%. The code will be available at https://github.com/qixucen/atom.
BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval
Jul 16, 2024



Existing retrieval benchmarks primarily consist of information-seeking queries (e.g., aggregated questions from search engines) where keyword or semantic-based retrieval is usually sufficient. However, many complex real-world queries require in-depth reasoning to identify relevant documents that go beyond surface form matching. For example, finding documentation for a coding question requires understanding the logic and syntax of the functions involved. To better benchmark retrieval on such challenging queries, we introduce BRIGHT, the first text retrieval benchmark that requires intensive reasoning to retrieve relevant documents. BRIGHT is constructed from the 1,398 real-world queries collected from diverse domains (such as economics, psychology, robotics, software engineering, earth sciences, etc.), sourced from naturally occurring or carefully curated human data. Extensive evaluation reveals that even state-of-the-art retrieval models perform poorly on BRIGHT. The leading model on the MTEB leaderboard [38 ], which achieves a score of 59.0 nDCG@10,2 produces a score of nDCG@10 of 18.0 on BRIGHT. We further demonstrate that augmenting queries with Chain-of-Thought reasoning generated by large language models (LLMs) improves performance by up to 12.2 points. Moreover, BRIGHT is robust against data leakage during pretraining of the benchmarked models as we validate by showing similar performance even when documents from the benchmark are included in the training data. We believe that BRIGHT paves the way for future research on retrieval systems in more realistic and challenging settings. Our code and data are available at https://brightbenchmark.github.io.
A Multimodal Dangerous State Recognition and Early Warning System for Elderly with Intermittent Dementia
May 30, 2024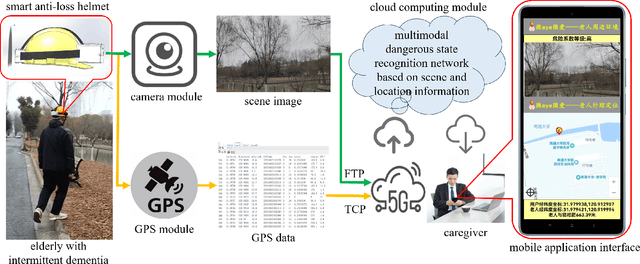
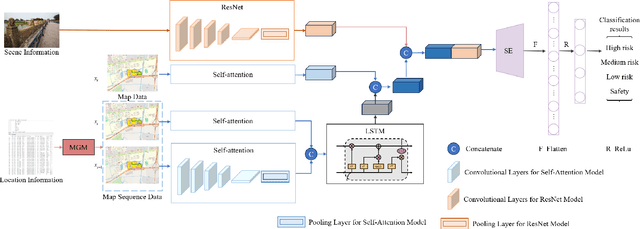
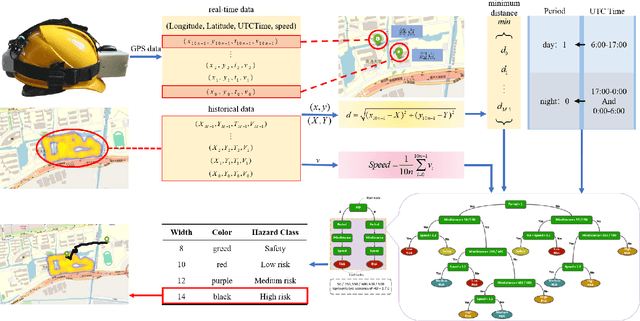
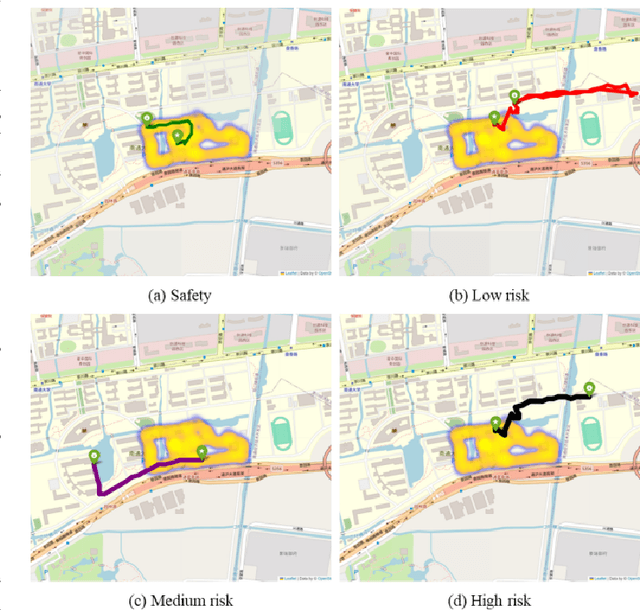
In response to the social issue of the increasing number of elderly vulnerable groups going missing due to the aggravating aging population in China, our team has developed a wearable anti-loss device and intelligent early warning system for elderly individuals with intermittent dementia using artificial intelligence and IoT technology. This system comprises an anti-loss smart helmet, a cloud computing module, and an intelligent early warning application on the caregiver's mobile device. The smart helmet integrates a miniature camera module, a GPS module, and a 5G communication module to collect first-person images and location information of the elderly. Data is transmitted remotely via 5G, FTP, and TCP protocols. In the cloud computing module, our team has proposed for the first time a multimodal dangerous state recognition network based on scene and location information to accurately assess the risk of elderly individuals going missing. Finally, the application software interface designed for the caregiver's mobile device implements multi-level early warnings. The system developed by our team requires no operation or response from the elderly, achieving fully automatic environmental perception, risk assessment, and proactive alarming. This overcomes the limitations of traditional monitoring devices, which require active operation and response, thus avoiding the issue of the digital divide for the elderly. It effectively prevents accidental loss and potential dangers for elderly individuals with dementia.
Can Language Models Solve Olympiad Programming?
Apr 16, 2024



Computing olympiads contain some of the most challenging problems for humans, requiring complex algorithmic reasoning, puzzle solving, in addition to generating efficient code. However, it has been understudied as a domain to evaluate language models (LMs). In this paper, we introduce the USACO benchmark with 307 problems from the USA Computing Olympiad, along with high-quality unit tests, reference code, and official analyses for each problem. These resources enable us to construct and test a range of LM inference methods for competitive programming for the first time. We find GPT-4 only achieves a 8.7% pass@1 accuracy with zero-shot chain-of-thought prompting, and our best inference method improves it to 20.2% using a combination of self-reflection and retrieval over episodic knowledge. However, this is far from solving the benchmark. To better understand the remaining challenges, we design a novel human-in-the-loop study and surprisingly find that a small number of targeted hints enable GPT-4 to solve 13 out of 15 problems previously unsolvable by any model and method. Our benchmark, baseline methods, quantitative results, and qualitative analysis serve as an initial step toward LMs with grounded, creative, and algorithmic reasoning.
Efficient Commercial Bank Customer Credit Risk Assessment Based on LightGBM and Feature Engineering
Aug 17, 2023Effective control of credit risk is a key link in the steady operation of commercial banks. This paper is mainly based on the customer information dataset of a foreign commercial bank in Kaggle, and we use LightGBM algorithm to build a classifier to classify customers, to help the bank judge the possibility of customer credit default. This paper mainly deals with characteristic engineering, such as missing value processing, coding, imbalanced samples, etc., which greatly improves the machine learning effect. The main innovation of this paper is to construct new feature attributes on the basis of the original dataset so that the accuracy of the classifier reaches 0.734, and the AUC reaches 0.772, which is more than many classifiers based on the same dataset. The model can provide some reference for commercial banks' credit granting, and also provide some feature processing ideas for other similar studies.