 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
Feb 03, 2026Language agents have shown strong promise for task automation. Realizing this promise for increasingly complex, long-horizon tasks has driven the rise of a sub-agent-as-tools paradigm for multi-turn task solving. However, existing designs still lack a dynamic abstraction view of sub-agents, thereby hurting adaptability. We address this challenge with a unified, framework-agnostic agent abstraction that models any agent as a tuple Instruction, Context, Tools, Model. This tuple acts as a compositional recipe for capabilities, enabling the system to spawn specialized executors for each task on demand. Building on this abstraction, we introduce an agentic system AOrchestra, where the central orchestrator concretizes the tuple at each step: it curates task-relevant context, selects tools and models, and delegates execution via on-the-fly automatic agent creation. Such designs enable reducing human engineering efforts, and remain framework-agnostic with plug-and-play support for diverse agents as task executors. It also enables a controllable performance-cost trade-off, allowing the system to approach Pareto-efficient. Across three challenging benchmarks (GAIA, SWE-Bench, Terminal-Bench), AOrchestra achieves 16.28% relative improvement against the strongest baseline when paired with Gemini-3-Flash. The code is available at: https://github.com/FoundationAgents/AOrchestra
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025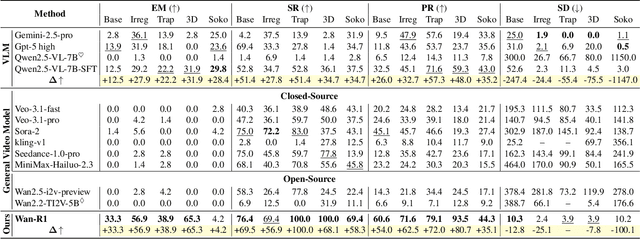

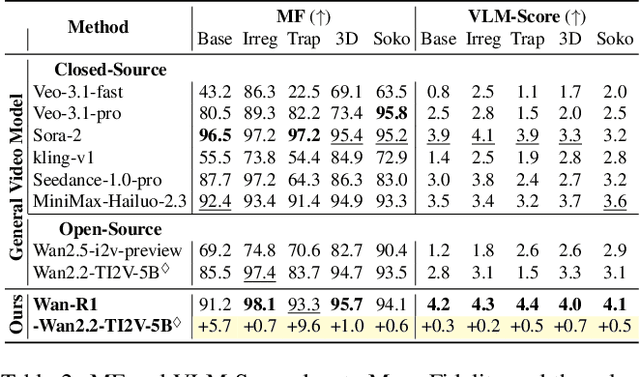
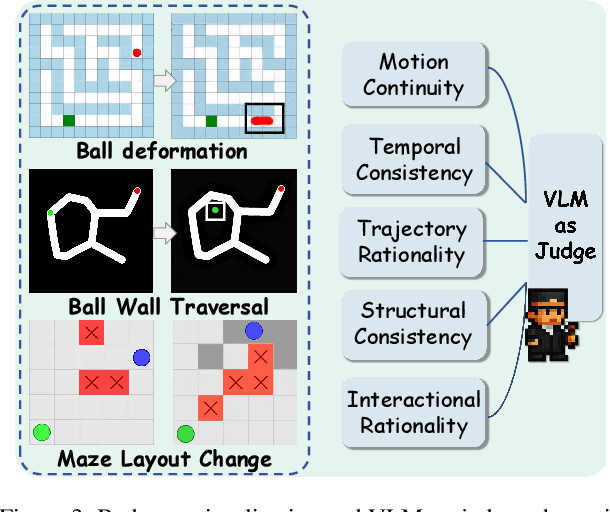
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
TimeSense:Making Large Language Models Proficient in Time-Series Analysis
Nov 09, 2025In the time-series domain, an increasing number of works combine text with temporal data to leverage the reasoning capabilities of large language models (LLMs) for various downstream time-series understanding tasks. This enables a single model to flexibly perform tasks that previously required specialized models for each domain. However, these methods typically rely on text labels for supervision during training, biasing the model toward textual cues while potentially neglecting the full temporal features. Such a bias can lead to outputs that contradict the underlying time-series context. To address this issue, we construct the EvalTS benchmark, comprising 10 tasks across three difficulty levels, from fundamental temporal pattern recognition to complex real-world reasoning, to evaluate models under more challenging and realistic scenarios. We also propose TimeSense, a multimodal framework that makes LLMs proficient in time-series analysis by balancing textual reasoning with a preserved temporal sense. TimeSense incorporates a Temporal Sense module that reconstructs the input time-series within the model's context, ensuring that textual reasoning is grounded in the time-series dynamics. Moreover, to enhance spatial understanding of time-series data, we explicitly incorporate coordinate-based positional embeddings, which provide each time point with spatial context and enable the model to capture structural dependencies more effectively. Experimental results demonstrate that TimeSense achieves state-of-the-art performance across multiple tasks, and it particularly outperforms existing methods on complex multi-dimensional time-series reasoning tasks.
VisJudge-Bench: Aesthetics and Quality Assessment of Visualizations
Oct 25, 2025Visualization, a domain-specific yet widely used form of imagery, is an effective way to turn complex datasets into intuitive insights, and its value depends on whether data are faithfully represented, clearly communicated, and aesthetically designed. However, evaluating visualization quality is challenging: unlike natural images, it requires simultaneous judgment across data encoding accuracy, information expressiveness, and visual aesthetics. Although multimodal large language models (MLLMs) have shown promising performance in aesthetic assessment of natural images, no systematic benchmark exists for measuring their capabilities in evaluating visualizations. To address this, we propose VisJudge-Bench, the first comprehensive benchmark for evaluating MLLMs' performance in assessing visualization aesthetics and quality. It contains 3,090 expert-annotated samples from real-world scenarios, covering single visualizations, multiple visualizations, and dashboards across 32 chart types. Systematic testing on this benchmark reveals that even the most advanced MLLMs (such as GPT-5) still exhibit significant gaps compared to human experts in judgment, with a Mean Absolute Error (MAE) of 0.551 and a correlation with human ratings of only 0.429. To address this issue, we propose VisJudge, a model specifically designed for visualization aesthetics and quality assessment. Experimental results demonstrate that VisJudge significantly narrows the gap with human judgment, reducing the MAE to 0.442 (a 19.8% reduction) and increasing the consistency with human experts to 0.681 (a 58.7% improvement) compared to GPT-5. The benchmark is available at https://github.com/HKUSTDial/VisJudgeBench.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
Atom of Thoughts for Markov LLM Test-Time Scaling
Feb 17, 2025Large Language Models (LLMs) achieve superior performance through training-time scaling, and test-time scaling further enhances their capabilities by conducting effective reasoning during inference. However, as the scale of reasoning increases, existing test-time scaling methods suffer from accumulated historical information, which not only wastes computational resources but also interferes with effective reasoning. To address this issue, we observe that complex reasoning progress is often achieved by solving a sequence of independent subquestions, each being self-contained and verifiable. These subquestions are essentially atomic questions, relying primarily on their current state rather than accumulated history, similar to the memoryless transitions in a Markov process. Based on this observation, we propose Atom of Thoughts (AoT), where each state transition in the reasoning process consists of decomposing the current question into a dependency-based directed acyclic graph and contracting its subquestions, forming a new atomic question state. This iterative decomposition-contraction process continues until reaching directly solvable atomic questions, naturally realizing Markov transitions between question states. Furthermore, these atomic questions can be seamlessly integrated into existing test-time scaling methods, enabling AoT to serve as a plug-in enhancement for improving reasoning capabilities. Experiments across six benchmarks demonstrate the effectiveness of AoT both as a standalone framework and a plug-in enhancement. Notably, on HotpotQA, when applied to gpt-4o-mini, AoT achieves an 80.6% F1 score, surpassing o3-mini by 3.4% and DeepSeek-R1 by 10.6%. The code will be available at https://github.com/qixucen/atom.
Self-Supervised Prompt Optimization
Feb 07, 2025



Well-designed prompts are crucial for enhancing Large language models' (LLMs) reasoning capabilities while aligning their outputs with task requirements across diverse domains. However, manually designed prompts require expertise and iterative experimentation. While existing prompt optimization methods aim to automate this process, they rely heavily on external references such as ground truth or by humans, limiting their applicability in real-world scenarios where such data is unavailable or costly to obtain. To address this, we propose Self-Supervised Prompt Optimization (SPO), a cost-efficient framework that discovers effective prompts for both closed and open-ended tasks without requiring external reference. Motivated by the observations that prompt quality manifests directly in LLM outputs and LLMs can effectively assess adherence to task requirements, we derive evaluation and optimization signals purely from output comparisons. Specifically, SPO selects superior prompts through pairwise output comparisons evaluated by an LLM evaluator, followed by an LLM optimizer that aligns outputs with task requirements. Extensive experiments demonstrate that SPO outperforms state-of-the-art prompt optimization methods, achieving comparable or superior results with significantly lower costs (e.g., 1.1% to 5.6% of existing methods) and fewer samples (e.g., three samples). The code is available at https://github.com/geekan/MetaGPT.
Abnormality Forecasting: Time Series Anomaly Prediction via Future Context Modeling
Oct 16, 2024Identifying anomalies from time series data plays an important role in various fields such as infrastructure security, intelligent operation and maintenance, and space exploration. Current research focuses on detecting the anomalies after they occur, which can lead to significant financial/reputation loss or infrastructure damage. In this work we instead study a more practical yet very challenging problem, time series anomaly prediction, aiming at providing early warnings for abnormal events before their occurrence. To tackle this problem, we introduce a novel principled approach, namely future context modeling (FCM). Its key insight is that the future abnormal events in a target window can be accurately predicted if their preceding observation window exhibits any subtle difference to normal data. To effectively capture such differences, FCM first leverages long-term forecasting models to generate a discriminative future context based on the observation data, aiming to amplify those subtle but unusual difference. It then models a normality correlation of the observation data with the forecasting future context to complement the normality modeling of the observation data in foreseeing possible abnormality in the target window. A joint variate-time attention learning is also introduced in FCM to leverage both temporal signals and features of the time series data for more discriminative normality modeling in the aforementioned two views. Comprehensive experiments on five datasets demonstrate that FCM gains good recall rate (70\%+) on multiple datasets and significantly outperforms all baselines in F1 score. Code is available at https://github.com/mala-lab/FCM.
AFlow: Automating Agentic Workflow Generation
Oct 14, 2024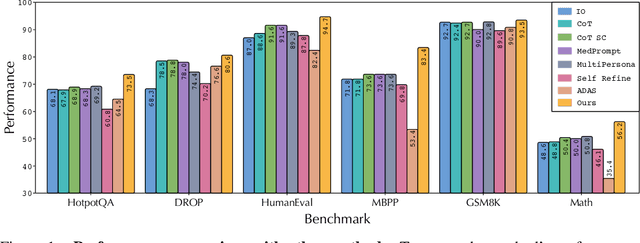

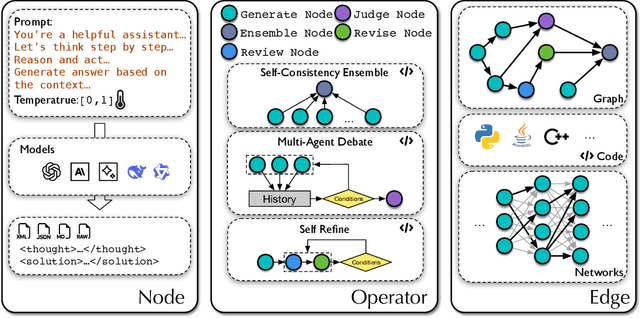
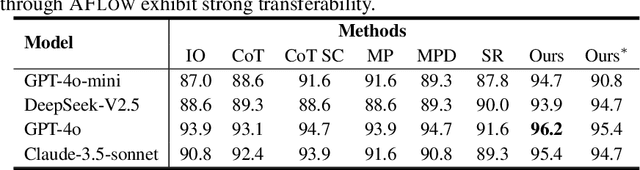
Large language models (LLMs) have demonstrated remarkable potential in solving complex tasks across diverse domains, typically by employing agentic workflows that follow detailed instructions and operational sequences. However, constructing these workflows requires significant human effort, limiting scalability and generalizability. Recent research has sought to automate the generation and optimization of these workflows, but existing methods still rely on initial manual setup and fall short of achieving fully automated and effective workflow generation. To address this challenge, we reformulate workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. We introduce AFlow, an automated framework that efficiently explores this space using Monte Carlo Tree Search, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Empirical evaluations across six benchmark datasets demonstrate AFlow's efficacy, yielding a 5.7% average improvement over state-of-the-art baselines. Furthermore, AFlow enables smaller models to outperform GPT-4o on specific tasks at 4.55% of its inference cost in dollars. The code will be available at https://github.com/geekan/MetaGPT.
MobileExperts: A Dynamic Tool-Enabled Agent Team in Mobile Devices
Jul 04, 2024



The attainment of autonomous operations in mobile computing devices has consistently been a goal of human pursuit. With the development of Large Language Models (LLMs) and Visual Language Models (VLMs), this aspiration is progressively turning into reality. While contemporary research has explored automation of simple tasks on mobile devices via VLMs, there remains significant room for improvement in handling complex tasks and reducing high reasoning costs. In this paper, we introduce MobileExperts, which for the first time introduces tool formulation and multi-agent collaboration to address the aforementioned challenges. More specifically, MobileExperts dynamically assembles teams based on the alignment of agent portraits with the human requirements. Following this, each agent embarks on an independent exploration phase, formulating its tools to evolve into an expert. Lastly, we develop a dual-layer planning mechanism to establish coordinate collaboration among experts. To validate our effectiveness, we design a new benchmark of hierarchical intelligence levels, offering insights into algorithm's capability to address tasks across a spectrum of complexity. Experimental results demonstrate that MobileExperts performs better on all intelligence levels and achieves ~ 22% reduction in reasoning costs, thus verifying the superiority of our design.