 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
Feb 03, 2026Language agents have shown strong promise for task automation. Realizing this promise for increasingly complex, long-horizon tasks has driven the rise of a sub-agent-as-tools paradigm for multi-turn task solving. However, existing designs still lack a dynamic abstraction view of sub-agents, thereby hurting adaptability. We address this challenge with a unified, framework-agnostic agent abstraction that models any agent as a tuple Instruction, Context, Tools, Model. This tuple acts as a compositional recipe for capabilities, enabling the system to spawn specialized executors for each task on demand. Building on this abstraction, we introduce an agentic system AOrchestra, where the central orchestrator concretizes the tuple at each step: it curates task-relevant context, selects tools and models, and delegates execution via on-the-fly automatic agent creation. Such designs enable reducing human engineering efforts, and remain framework-agnostic with plug-and-play support for diverse agents as task executors. It also enables a controllable performance-cost trade-off, allowing the system to approach Pareto-efficient. Across three challenging benchmarks (GAIA, SWE-Bench, Terminal-Bench), AOrchestra achieves 16.28% relative improvement against the strongest baseline when paired with Gemini-3-Flash. The code is available at: https://github.com/FoundationAgents/AOrchestra
Self-Supervised Prompt Optimization
Feb 07, 2025



Well-designed prompts are crucial for enhancing Large language models' (LLMs) reasoning capabilities while aligning their outputs with task requirements across diverse domains. However, manually designed prompts require expertise and iterative experimentation. While existing prompt optimization methods aim to automate this process, they rely heavily on external references such as ground truth or by humans, limiting their applicability in real-world scenarios where such data is unavailable or costly to obtain. To address this, we propose Self-Supervised Prompt Optimization (SPO), a cost-efficient framework that discovers effective prompts for both closed and open-ended tasks without requiring external reference. Motivated by the observations that prompt quality manifests directly in LLM outputs and LLMs can effectively assess adherence to task requirements, we derive evaluation and optimization signals purely from output comparisons. Specifically, SPO selects superior prompts through pairwise output comparisons evaluated by an LLM evaluator, followed by an LLM optimizer that aligns outputs with task requirements. Extensive experiments demonstrate that SPO outperforms state-of-the-art prompt optimization methods, achieving comparable or superior results with significantly lower costs (e.g., 1.1% to 5.6% of existing methods) and fewer samples (e.g., three samples). The code is available at https://github.com/geekan/MetaGPT.
Data Interpreter: An LLM Agent For Data Science
Mar 12, 2024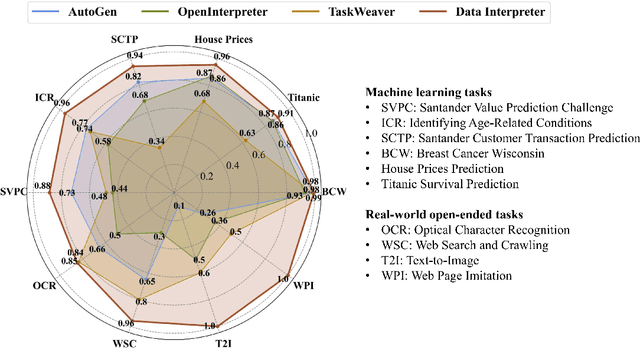
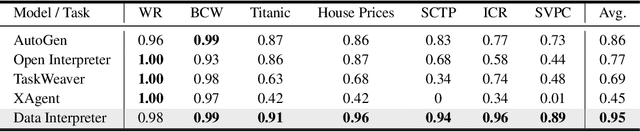
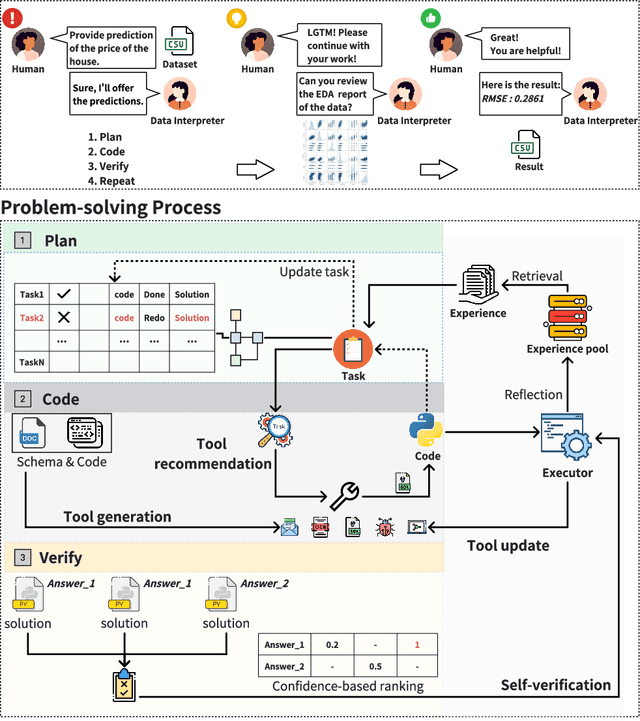

Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness. However, their performance can be compromised in data science scenarios that require real-time data adjustment, expertise in optimization due to complex dependencies among various tasks, and the ability to identify logical errors for precise reasoning. In this study, we introduce the Data Interpreter, a solution designed to solve with code that emphasizes three pivotal techniques to augment problem-solving in data science: 1) dynamic planning with hierarchical graph structures for real-time data adaptability;2) tool integration dynamically to enhance code proficiency during execution, enriching the requisite expertise;3) logical inconsistency identification in feedback, and efficiency enhancement through experience recording. We evaluate the Data Interpreter on various data science and real-world tasks. Compared to open-source baselines, it demonstrated superior performance, exhibiting significant improvements in machine learning tasks, increasing from 0.86 to 0.95. Additionally, it showed a 26% increase in the MATH dataset and a remarkable 112% improvement in open-ended tasks. The solution will be released at https://github.com/geekan/MetaGPT.