 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformalized Signal Temporal Logic Inference under Covariate Shift
Mar 28, 2026Signal Temporal Logic (STL) inference learns interpretable logical rules for temporal behaviors in dynamical systems. To ensure the correctness of learned STL formulas, recent approaches have incorporated conformal prediction as a statistical tool for uncertainty quantification. However, most existing methods rely on the assumption that calibration and testing data are identically distributed and exchangeable, an assumption that is frequently violated in real-world settings. This paper proposes a conformalized STL inference framework that explicitly addresses covariate shift between training and deployment trajectories dataset. From a technical standpoint, the approach first employs a template-free, differentiable STL inference method to learn an initial model, and subsequently refines it using a limited deployment side dataset to promote distribution alignment. To provide validity guarantees under distribution shift, the framework estimates the likelihood ratio between training and deployment distributions and integrates it into an STL-robustness-based weighted conformal prediction scheme. Experimental results on trajectory datasets demonstrate that the proposed framework preserves the interpretability of STL formulas while significantly improving symbolic learning reliability at deployment time.
DAGS-SLAM: Dynamic-Aware 3DGS SLAM via Spatiotemporal Motion Probability and Uncertainty-Aware Scheduling
Feb 25, 2026Mobile robots and IoT devices demand real-time localization and dense reconstruction under tight compute and energy budgets. While 3D Gaussian Splatting (3DGS) enables efficient dense SLAM, dynamic objects and occlusions still degrade tracking and mapping. Existing dynamic 3DGS-SLAM often relies on heavy optical flow and per-frame segmentation, which is costly for mobile deployment and brittle under challenging illumination. We present DAGS-SLAM, a dynamic-aware 3DGS-SLAM system that maintains a spatiotemporal motion probability (MP) state per Gaussian and triggers semantics on demand via an uncertainty-aware scheduler. DAGS-SLAM fuses lightweight YOLO instance priors with geometric cues to estimate and temporally update MP, propagates MP to the front-end for dynamic-aware correspondence selection, and suppresses dynamic artifacts in the back-end via MP-guided optimization. Experiments on public dynamic RGB-D benchmarks show improved reconstruction and robust tracking while sustaining real-time throughput on a commodity GPU, demonstrating a practical speed-accuracy tradeoff with reduced semantic invocations toward mobile deployment.
CrystaL: Spontaneous Emergence of Visual Latents in MLLMs
Feb 24, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable performance by integrating powerful language backbones with large-scale visual encoders. Among these, latent Chain-of-Thought (CoT) methods enable implicit reasoning in continuous hidden states, facilitating seamless vision-language integration and faster inference. However, existing heuristically predefined supervision signals in latent CoT provide limited guidance for preserving critical visual information in intermediate latent states. To address this limitation, we propose CrystaL (Crystallized Latent Reasoning), a single-stage framework with two paths to process intact and corrupted images, respectively. By explicitly aligning the attention patterns and prediction distributions across the two paths, CrystaL crystallizes latent representations into task-relevant visual semantics, without relying on auxiliary annotations or external modules. Extensive experiments on perception-intensive benchmarks demonstrate that CrystaL consistently outperforms state-of-the-art baselines, achieving substantial gains in fine-grained visual understanding while maintaining robust reasoning capabilities.
SwiftVLM: Efficient Vision-Language Model Inference via Cross-Layer Token Bypass
Feb 03, 2026Visual token pruning is a promising approach for reducing the computational cost of vision-language models (VLMs), and existing methods often rely on early pruning decisions to improve efficiency. While effective on coarse-grained reasoning tasks, they suffer from significant performance degradation on tasks requiring fine-grained visual details. Through layer-wise analysis, we reveal substantial discrepancies in visual token importance across layers, showing that tokens deemed unimportant at shallow layers can later become highly relevant for text-conditioned reasoning. To avoid irreversible critical information loss caused by premature pruning, we introduce a new pruning paradigm, termed bypass, which preserves unselected visual tokens and forwards them to subsequent pruning stages for re-evaluation. Building on this paradigm, we propose SwiftVLM, a simple and training-free method that performs pruning at model-specific layers with strong visual token selection capability, while enabling independent pruning decisions across layers. Experiments across multiple VLMs and benchmarks demonstrate that SwiftVLM consistently outperforms existing pruning strategies, achieving superior accuracy-efficiency trade-offs and more faithful visual token selection behavior.
OmniOVCD: Streamlining Open-Vocabulary Change Detection with SAM 3
Jan 20, 2026Change Detection (CD) is a fundamental task in remote sensing. It monitors the evolution of land cover over time. Based on this, Open-Vocabulary Change Detection (OVCD) introduces a new requirement. It aims to reduce the reliance on predefined categories. Existing training-free OVCD methods mostly use CLIP to identify categories. These methods also need extra models like DINO to extract features. However, combining different models often causes problems in matching features and makes the system unstable. Recently, the Segment Anything Model 3 (SAM 3) is introduced. It integrates segmentation and identification capabilities within one promptable model, which offers new possibilities for the OVCD task. In this paper, we propose OmniOVCD, a standalone framework designed for OVCD. By leveraging the decoupled output heads of SAM 3, we propose a Synergistic Fusion to Instance Decoupling (SFID) strategy. SFID first fuses the semantic, instance, and presence outputs of SAM 3 to construct land-cover masks, and then decomposes them into individual instance masks for change comparison. This design preserves high accuracy in category recognition and maintains instance-level consistency across images. As a result, the model can generate accurate change masks. Experiments on four public benchmarks (LEVIR-CD, WHU-CD, S2Looking, and SECOND) demonstrate SOTA performance, achieving IoU scores of 67.2, 66.5, 24.5, and 27.1 (class-average), respectively, surpassing all previous methods.
OpenMoCap: Rethinking Optical Motion Capture under Real-world Occlusion
Aug 18, 2025Optical motion capture is a foundational technology driving advancements in cutting-edge fields such as virtual reality and film production. However, system performance suffers severely under large-scale marker occlusions common in real-world applications. An in-depth analysis identifies two primary limitations of current models: (i) the lack of training datasets accurately reflecting realistic marker occlusion patterns, and (ii) the absence of training strategies designed to capture long-range dependencies among markers. To tackle these challenges, we introduce the CMU-Occlu dataset, which incorporates ray tracing techniques to realistically simulate practical marker occlusion patterns. Furthermore, we propose OpenMoCap, a novel motion-solving model designed specifically for robust motion capture in environments with significant occlusions. Leveraging a marker-joint chain inference mechanism, OpenMoCap enables simultaneous optimization and construction of deep constraints between markers and joints. Extensive comparative experiments demonstrate that OpenMoCap consistently outperforms competing methods across diverse scenarios, while the CMU-Occlu dataset opens the door for future studies in robust motion solving. The proposed OpenMoCap is integrated into the MoSen MoCap system for practical deployment. The code is released at: https://github.com/qianchen214/OpenMoCap.
SpotVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer
Aug 18, 2025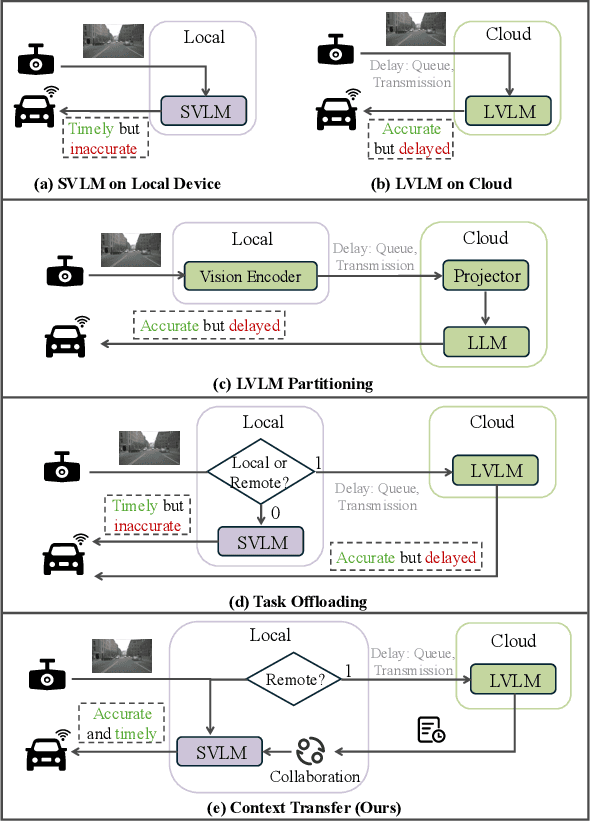
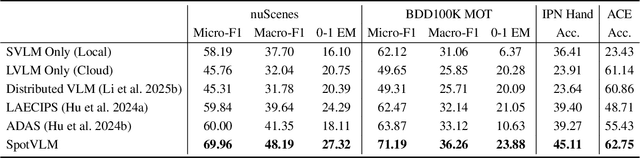
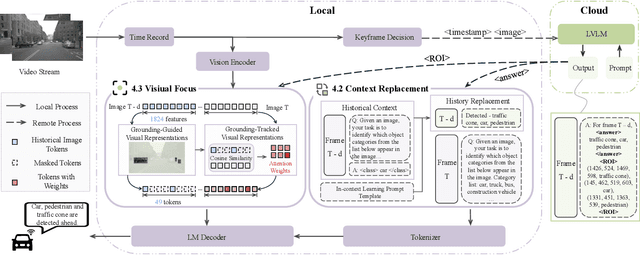
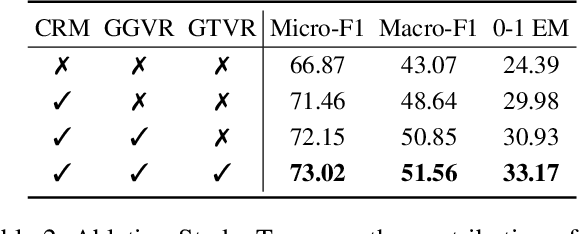
Vision-Language Models (VLMs) are increasingly deployed in real-time applications such as autonomous driving and human-computer interaction, which demand fast and reliable responses based on accurate perception. To meet these requirements, existing systems commonly employ cloud-edge collaborative architectures, such as partitioned Large Vision-Language Models (LVLMs) or task offloading strategies between Large and Small Vision-Language Models (SVLMs). However, these methods fail to accommodate cloud latency fluctuations and overlook the full potential of delayed but accurate LVLM responses. In this work, we propose a novel cloud-edge collaborative paradigm for VLMs, termed Context Transfer, which treats the delayed outputs of LVLMs as historical context to provide real-time guidance for SVLMs inference. Based on this paradigm, we design SpotVLM, which incorporates both context replacement and visual focus modules to refine historical textual input and enhance visual grounding consistency. Extensive experiments on three real-time vision tasks across four datasets demonstrate the effectiveness of the proposed framework. The new paradigm lays the groundwork for more effective and latency-aware collaboration strategies in future VLM systems.
SpecOffload: Unlocking Latent GPU Capacity for LLM Inference on Resource-Constrained Devices
May 15, 2025Efficient LLM inference on resource-constrained devices presents significant challenges in compute and memory utilization. Due to limited GPU memory, existing systems offload model weights to CPU memory, incurring substantial I/O overhead between the CPU and GPU. This leads to two major inefficiencies: (1) GPU cores are underutilized, often remaining idle while waiting for data to be loaded; and (2) GPU memory has low impact on performance, as reducing its capacity has minimal effect on overall throughput.In this paper, we propose SpecOffload, a high-throughput inference engine that embeds speculative decoding into offloading. Our key idea is to unlock latent GPU resources for storing and executing a draft model used for speculative decoding, thus accelerating inference at near-zero additional cost. To support this, we carefully orchestrate the interleaved execution of target and draft models in speculative decoding within the offloading pipeline, and propose a planner to manage tensor placement and select optimal parameters. Compared to the best baseline, SpecOffload improves GPU core utilization by 4.49x and boosts inference throughput by 2.54x. Our code is available at https://github.com/MobiSense/SpecOffload .
A Simple Detector with Frame Dynamics is a Strong Tracker
May 08, 2025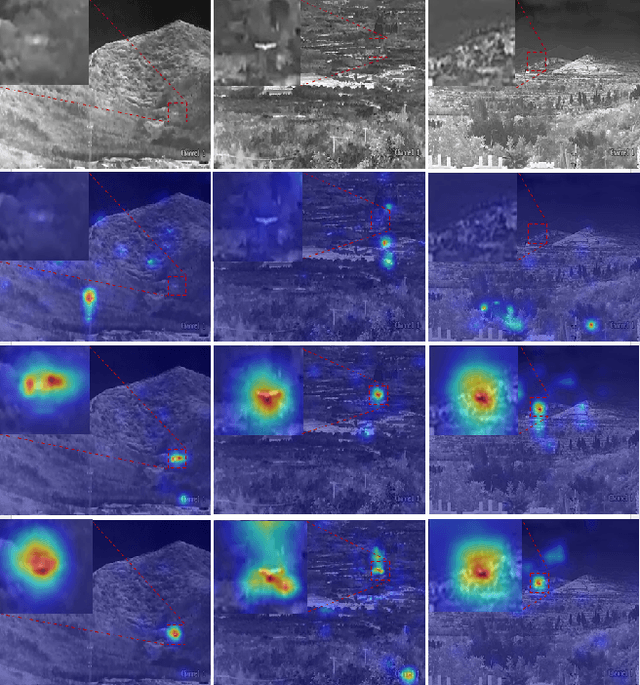
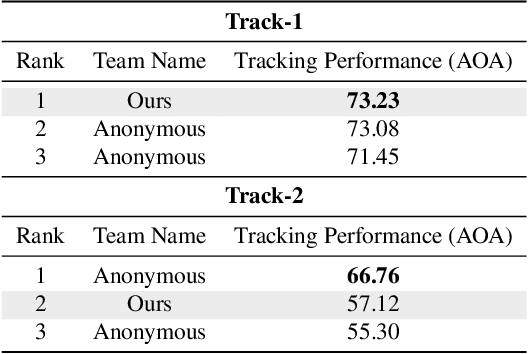
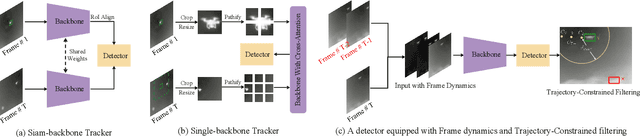
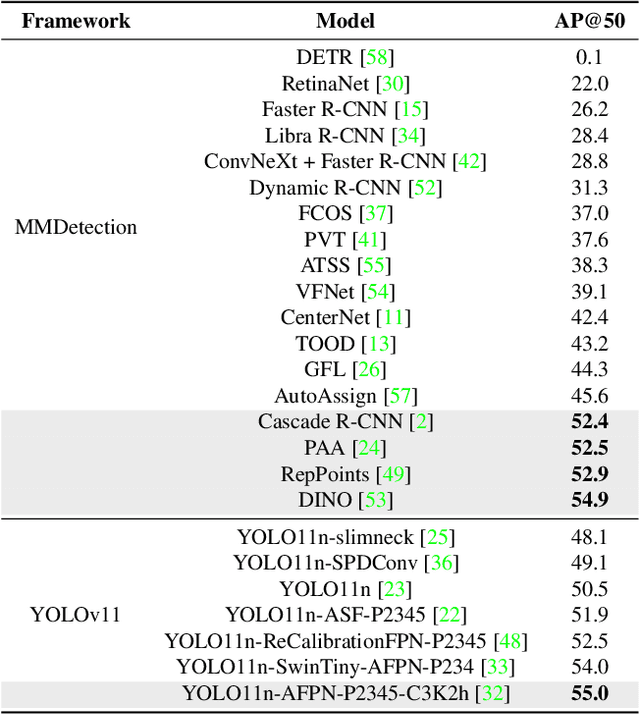
Infrared object tracking plays a crucial role in Anti-Unmanned Aerial Vehicle (Anti-UAV) applications. Existing trackers often depend on cropped template regions and have limited motion modeling capabilities, which pose challenges when dealing with tiny targets. To address this, we propose a simple yet effective infrared tiny-object tracker that enhances tracking performance by integrating global detection and motion-aware learning with temporal priors. Our method is based on object detection and achieves significant improvements through two key innovations. First, we introduce frame dynamics, leveraging frame difference and optical flow to encode both prior target features and motion characteristics at the input level, enabling the model to better distinguish the target from background clutter. Second, we propose a trajectory constraint filtering strategy in the post-processing stage, utilizing spatio-temporal priors to suppress false positives and enhance tracking robustness. Extensive experiments show that our method consistently outperforms existing approaches across multiple metrics in challenging infrared UAV tracking scenarios. Notably, we achieve state-of-the-art performance in the 4th Anti-UAV Challenge, securing 1st place in Track 1 and 2nd place in Track 2.
TLINet: Differentiable Neural Network Temporal Logic Inference
May 14, 2024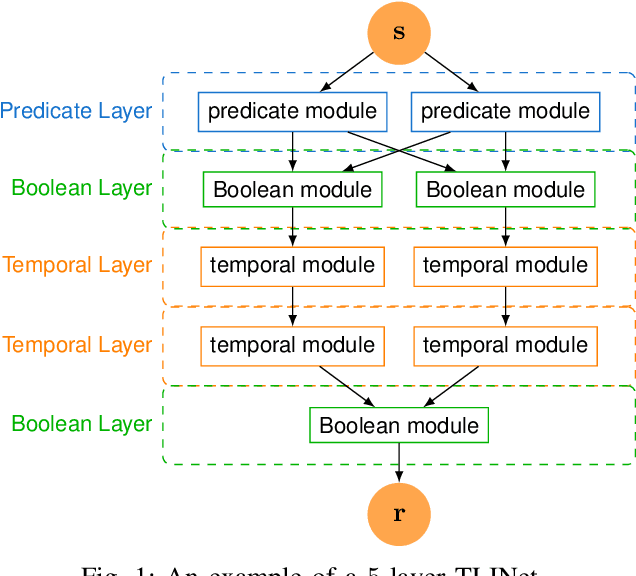
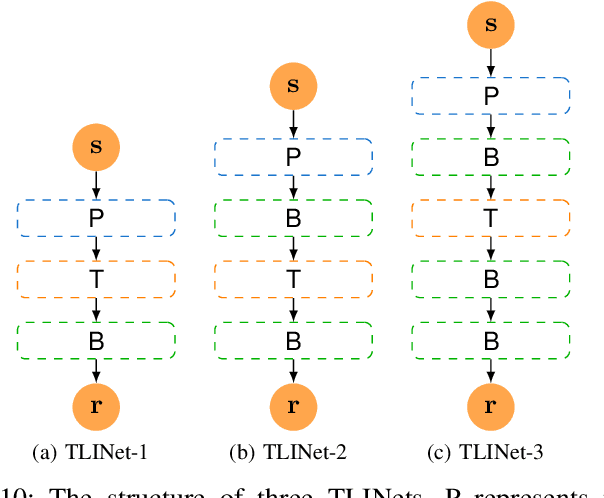
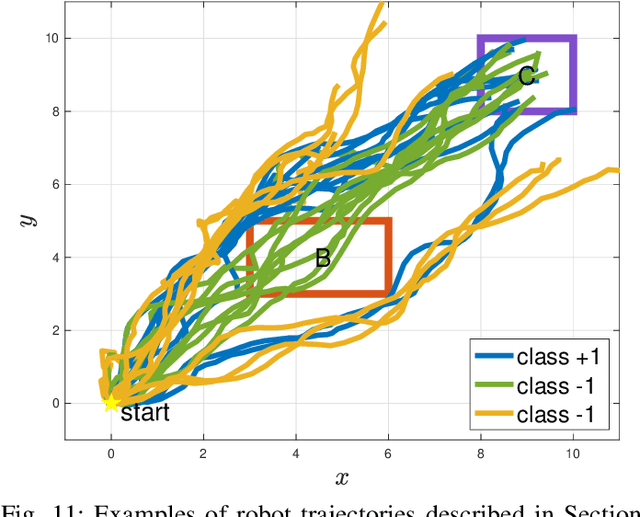
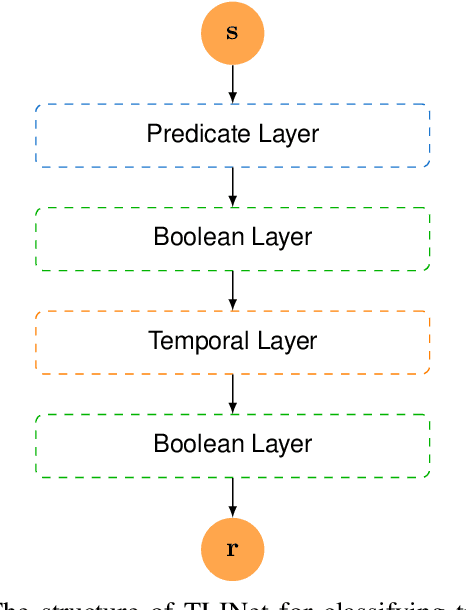
There has been a growing interest in extracting formal descriptions of the system behaviors from data. Signal Temporal Logic (STL) is an expressive formal language used to describe spatial-temporal properties with interpretability. This paper introduces TLINet, a neural-symbolic framework for learning STL formulas. The computation in TLINet is differentiable, enabling the usage of off-the-shelf gradient-based tools during the learning process. In contrast to existing approaches, we introduce approximation methods for max operator designed specifically for temporal logic-based gradient techniques, ensuring the correctness of STL satisfaction evaluation. Our framework not only learns the structure but also the parameters of STL formulas, allowing flexible combinations of operators and various logical structures. We validate TLINet against state-of-the-art baselines, demonstrating that our approach outperforms these baselines in terms of interpretability, compactness, rich expressibility, and computational efficiency.