 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Semantic Risk into Distance Fields and CBFs for Online Monocular Safe Control
Jun 01, 2026We propose an online monocular perception-to-control framework that embeds semantic risk into the distance field used by Control Barrier Function (CBF)-based safe navigation and teleoperation. Many perception-based safety filters assign the same distance-based safety margin to all mapped obstacles or use semantics only as a downstream controller adjustment, rather than encoding semantic risk in the spatial representation. Our framework instead reasons online about obstacle geometry and class-dependent risk by embedding semantic information directly into the Euclidean Signed Distance Field (ESDF). This design encodes semantic risk before control optimization, so high-risk objects exert a larger spatial influence in the safety field while retaining efficient ESDF queries at runtime. Specifically, a foundation-model-based SLAM front end reconstructs dense 3-D geometry from monocular RGB video, while per-frame semantic segmentation provides pixel-level class labels that are fused into the reconstructed geometry. The resulting geometric-semantic representation is then converted into an ESDF, where semantic labels identify safety-relevant regions and impose class-dependent inflation before field computation. The semantic-aware ESDF provides the local distance values and spatial derivatives required by the CBF controller, while class-dependent gains further regulate the controller response. Extensive simulation and hardware experiments demonstrate online operation at 10--20 Hz and semantic-aware safe behavior in both teleoperation and autonomous navigation.
Conformalized Signal Temporal Logic Inference under Covariate Shift
Mar 28, 2026Signal Temporal Logic (STL) inference learns interpretable logical rules for temporal behaviors in dynamical systems. To ensure the correctness of learned STL formulas, recent approaches have incorporated conformal prediction as a statistical tool for uncertainty quantification. However, most existing methods rely on the assumption that calibration and testing data are identically distributed and exchangeable, an assumption that is frequently violated in real-world settings. This paper proposes a conformalized STL inference framework that explicitly addresses covariate shift between training and deployment trajectories dataset. From a technical standpoint, the approach first employs a template-free, differentiable STL inference method to learn an initial model, and subsequently refines it using a limited deployment side dataset to promote distribution alignment. To provide validity guarantees under distribution shift, the framework estimates the likelihood ratio between training and deployment distributions and integrates it into an STL-robustness-based weighted conformal prediction scheme. Experimental results on trajectory datasets demonstrate that the proposed framework preserves the interpretability of STL formulas while significantly improving symbolic learning reliability at deployment time.
RRT$^η$: Sampling-based Motion Planning and Control from STL Specifications using Arithmetic-Geometric Mean Robustness
Feb 18, 2026Sampling-based motion planning has emerged as a powerful approach for robotics, enabling exploration of complex, high-dimensional configuration spaces. When combined with Signal Temporal Logic (STL), a temporal logic widely used for formalizing interpretable robotic tasks, these methods can address complex spatiotemporal constraints. However, traditional approaches rely on min-max robustness measures that focus only on critical time points and subformulae, creating non-smooth optimization landscapes with sharp decision boundaries that hinder efficient tree exploration. We propose RRT$^η$, a sampling-based planning framework that integrates the Arithmetic-Geometric Mean (AGM) robustness measure to evaluate satisfaction across all time points and subformulae. Our key contributions include: (1) AGM robustness interval semantics for reasoning about partial trajectories during tree construction, (2) an efficient incremental monitoring algorithm computing these intervals, and (3) enhanced Direction of Increasing Satisfaction vectors leveraging Fulfillment Priority Logic (FPL) for principled objective composition. Our framework synthesizes dynamically feasible control sequences satisfying STL specifications with high robustness while maintaining the probabilistic completeness and asymptotic optimality of RRT$^\ast$. We validate our approach on three robotic systems. A double integrator point robot, a unicycle mobile robot, and a 7-DOF robot arm, demonstrating superior performance over traditional STL robustness-based planners in multi-constraint scenarios with limited guidance signals.
Gradient-Enhanced Partitioned Gaussian Processes for Real-Time Quadrotor Dynamics Modeling
Feb 13, 2026We present a quadrotor dynamics Gaussian Process (GP) with gradient information that achieves real-time inference via state-space partitioning and approximation, and that includes aerodynamic effects using data from mid-fidelity potential flow simulations. While traditional GP-based approaches provide reliable Bayesian predictions with uncertainty quantification, they are computationally expensive and thus unsuitable for real-time simulations. To address this challenge, we integrate gradient information to improve accuracy and introduce a novel partitioning and approximation strategy to reduce online computational cost. In particular, for the latter, we associate a local GP with each non-overlapping region; by splitting the training data into local near and far subsets, and by using Schur complements, we show that a large part of the matrix inversions required for inference can be performed offline, enabling real-time inference at frequencies above 30 Hz on standard desktop hardware. To generate a training dataset that captures aerodynamic effects, such as rotor-rotor interactions and apparent wind direction, we use the CHARM code, which is a mid-fidelity aerodynamic solver. It is applied to the SUI Endurance quadrotor to predict force and torque, along with noise at three specified locations. The derivative information is obtained via finite differences. Experimental results demonstrate that the proposed partitioned GP with gradient conditioning achieves higher accuracy than standard partitioned GPs without gradient information, while greatly reducing computational time. This framework provides an efficient foundation for real-time aerodynamic prediction and control algorithms in complex and unsteady environments.
Composable Model-Free RL for Navigation with Input-Affine Systems
Feb 13, 2026As autonomous robots move into complex, dynamic real-world environments, they must learn to navigate safely in real time, yet anticipating all possible behaviors is infeasible. We propose a composable, model-free reinforcement learning method that learns a value function and an optimal policy for each individual environment element (e.g., goal or obstacle) and composes them online to achieve goal reaching and collision avoidance. Assuming unknown nonlinear dynamics that evolve in continuous time and are input-affine, we derive a continuous-time Hamilton-Jacobi-Bellman (HJB) equation for the value function and show that the corresponding advantage function is quadratic in the action and optimal policy. Based on this structure, we introduce a model-free actor-critic algorithm that learns policies and value functions for static or moving obstacles using gradient descent. We then compose multiple reach/avoid models via a quadratically constrained quadratic program (QCQP), yielding formal obstacle-avoidance guarantees in terms of value-function level sets, providing a model-free alternative to CLF/CBF-based controllers. Simulations demonstrate improved performance over a PPO baseline applied to a discrete-time approximation.
Real-Time Navigation for Autonomous Aerial Vehicles Using Video
Apr 01, 2025Most applications in autonomous navigation using mounted cameras rely on the construction and processing of geometric 3D point clouds, which is an expensive process. However, there is another simpler way to make a space navigable quickly: to use semantic information (e.g., traffic signs) to guide the agent. However, detecting and acting on semantic information involves Computer Vision~(CV) algorithms such as object detection, which themselves are demanding for agents such as aerial drones with limited onboard resources. To solve this problem, we introduce a novel Markov Decision Process~(MDP) framework to reduce the workload of these CV approaches. We apply our proposed framework to both feature-based and neural-network-based object-detection tasks, using open-loop and closed-loop simulations as well as hardware-in-the-loop emulations. These holistic tests show significant benefits in energy consumption and speed with only a limited loss in accuracy compared to models based on static features and neural networks.
Accelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Games with Delayed Rewards
Nov 26, 2024
In this paper, we tackle the challenging problem of delayed rewards in reinforcement learning (RL). While Proximal Policy Optimization (PPO) has emerged as a leading Policy Gradient method, its performance can degrade under delayed rewards. We introduce two key enhancements to PPO: a hybrid policy architecture that combines an offline policy (trained on expert demonstrations) with an online PPO policy, and a reward shaping mechanism using Time Window Temporal Logic (TWTL). The hybrid architecture leverages offline data throughout training while maintaining PPO's theoretical guarantees. Building on the monotonic improvement framework of Trust Region Policy Optimization (TRPO), we prove that our approach ensures improvement over both the offline policy and previous iterations, with a bounded performance gap of $(2\varsigma\gamma\alpha^2)/(1-\gamma)^2$, where $\alpha$ is the mixing parameter, $\gamma$ is the discount factor, and $\varsigma$ bounds the expected advantage. Additionally, we prove that our TWTL-based reward shaping preserves the optimal policy of the original problem. TWTL enables formal translation of temporal objectives into immediate feedback signals that guide learning. We demonstrate the effectiveness of our approach through extensive experiments on an inverted pendulum and a lunar lander environments, showing improvements in both learning speed and final performance compared to standard PPO and offline-only approaches.
BoxMap: Efficient Structural Mapping and Navigation
Oct 08, 2024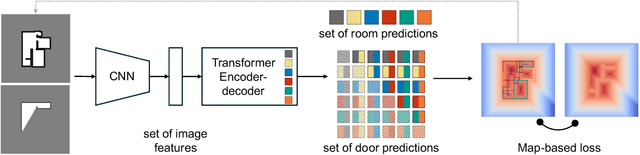
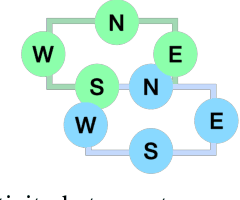
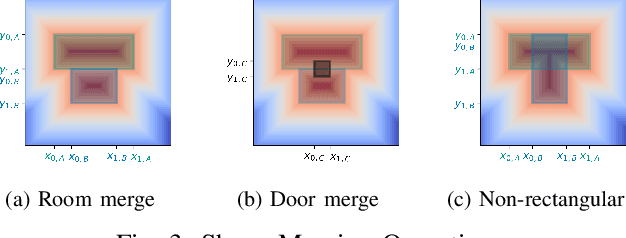
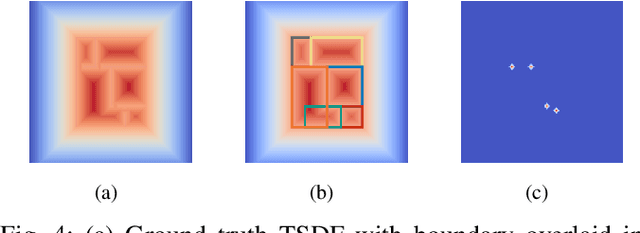
While humans can successfully navigate using abstractions, ignoring details that are irrelevant to the task at hand, most existing robotic applications require the maintenance of a detailed environment representation which consumes a significant amount of sensing, computing, and storage. These issues are particularly important in a resource-constrained setting with limited power budget. Deep learning methods can learn from prior experience to abstract knowledge of unknown environments, and use it to execute tasks (e.g., frontier exploration, object search, or scene understanding) more efficiently. We propose BoxMap, a Detection-Transformer-based architecture that takes advantage of the structure of the sensed partial environment to update a topological graph of the environment as a set of semantic entities (e.g. rooms and doors) and their relations (e.g. connectivity). These predictions from low-level measurements can then be leveraged to achieve high-level goals with lower computational costs than methods based on detailed representations. As an example application, we consider a robot equipped with a 2-D laser scanner tasked with exploring a residential building. Our BoxMap representation scales quadratically with the number of rooms (with a small constant), resulting in significant savings over a full geometric map. Moreover, our high-level topological representation results in 30.9% shorter trajectories in the exploration task with respect to a standard method.
Inverse Kinematics with Vision-Based Constraints
Jun 15, 2024This paper introduces the Visual Inverse Kinematics problem (VIK) to fill the gap between robot Inverse Kinematics (IK) and visual servo control. Different from the IK problem, the VIK problem seeks to find robot configurations subject to vision-based constraints, in addition to kinematic constraints. In this work, we develop a formulation of the VIK problem with a Field of View (FoV) constraint, enforcing the visibility of an object from a camera on the robot. Our proposed solution is based on the idea of adding a virtual kinematic chain connecting the physical robot and the object; the FoV constraint is then equivalent to a joint angle kinematic constraint. Along the way, we introduce multiple vision-based cost functions to fulfill different objectives. We solve this formulation of the VIK problem using a method that involves a semidefinite program (SDP) constraint followed by a rank minimization algorithm. The performance of this method for solving the VIK problem is validated through simulations.
Control of Microrobots Using Model Predictive Control and Gaussian Processes for Disturbance Estimation
Jun 04, 2024



This paper presents a control framework for magnetically actuated micron-scale robots ($\mu$bots) designed to mitigate disturbances and improve trajectory tracking. To address the challenges posed by unmodeled dynamics and environmental variability, we combine data-driven modeling with model-based control to accurately track desired trajectories using a relatively small amount of data. The system is represented with a simple linear model, and Gaussian Processes (GP) are employed to capture and estimate disturbances. This disturbance-enhanced model is then integrated into a Model Predictive Controller (MPC). Our approach demonstrates promising performance in both simulation and experimental setups, showcasing its potential for precise and reliable microrobot control in complex environments.