 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRT$^η$: Sampling-based Motion Planning and Control from STL Specifications using Arithmetic-Geometric Mean Robustness
Feb 18, 2026Sampling-based motion planning has emerged as a powerful approach for robotics, enabling exploration of complex, high-dimensional configuration spaces. When combined with Signal Temporal Logic (STL), a temporal logic widely used for formalizing interpretable robotic tasks, these methods can address complex spatiotemporal constraints. However, traditional approaches rely on min-max robustness measures that focus only on critical time points and subformulae, creating non-smooth optimization landscapes with sharp decision boundaries that hinder efficient tree exploration. We propose RRT$^η$, a sampling-based planning framework that integrates the Arithmetic-Geometric Mean (AGM) robustness measure to evaluate satisfaction across all time points and subformulae. Our key contributions include: (1) AGM robustness interval semantics for reasoning about partial trajectories during tree construction, (2) an efficient incremental monitoring algorithm computing these intervals, and (3) enhanced Direction of Increasing Satisfaction vectors leveraging Fulfillment Priority Logic (FPL) for principled objective composition. Our framework synthesizes dynamically feasible control sequences satisfying STL specifications with high robustness while maintaining the probabilistic completeness and asymptotic optimality of RRT$^\ast$. We validate our approach on three robotic systems. A double integrator point robot, a unicycle mobile robot, and a 7-DOF robot arm, demonstrating superior performance over traditional STL robustness-based planners in multi-constraint scenarios with limited guidance signals.
Accelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Games with Delayed Rewards
Nov 26, 2024
In this paper, we tackle the challenging problem of delayed rewards in reinforcement learning (RL). While Proximal Policy Optimization (PPO) has emerged as a leading Policy Gradient method, its performance can degrade under delayed rewards. We introduce two key enhancements to PPO: a hybrid policy architecture that combines an offline policy (trained on expert demonstrations) with an online PPO policy, and a reward shaping mechanism using Time Window Temporal Logic (TWTL). The hybrid architecture leverages offline data throughout training while maintaining PPO's theoretical guarantees. Building on the monotonic improvement framework of Trust Region Policy Optimization (TRPO), we prove that our approach ensures improvement over both the offline policy and previous iterations, with a bounded performance gap of $(2\varsigma\gamma\alpha^2)/(1-\gamma)^2$, where $\alpha$ is the mixing parameter, $\gamma$ is the discount factor, and $\varsigma$ bounds the expected advantage. Additionally, we prove that our TWTL-based reward shaping preserves the optimal policy of the original problem. TWTL enables formal translation of temporal objectives into immediate feedback signals that guide learning. We demonstrate the effectiveness of our approach through extensive experiments on an inverted pendulum and a lunar lander environments, showing improvements in both learning speed and final performance compared to standard PPO and offline-only approaches.
Efficient LQR-CBF-RRT*: Safe and Optimal Motion Planning
Apr 04, 2023



Control Barrier Functions (CBF) are a powerful tool for designing safety-critical controllers and motion planners. The safety requirements are encoded as a continuously differentiable function that maps from state variables to a real value, in which the sign of its output determines whether safety is violated. In practice, the CBFs can be used to enforce safety by imposing itself as a constraint in a Quadratic Program (QP) solved point-wise in time. However, this approach costs computational resources and could lead to infeasibility in solving the QP. In this paper, we propose a novel motion planning framework that combines sampling-based methods with Linear Quadratic Regulator (LQR) and CBFs. Our approach does not require solving the QPs for control synthesis and avoids explicit collision checking during samplings. Instead, it uses LQR to generate optimal controls and CBF to reject unsafe trajectories. To improve sampling efficiency, we employ the Cross-Entropy Method (CEM) for importance sampling (IS) to sample configurations that will enhance the path with higher probability and store computed optimal gain matrices in a hash table to avoid re-computation during rewiring procedure. We demonstrate the effectiveness of our method on nonlinear control affine systems in simulation.
Adaptive Sampling-based Motion Planning with Control Barrier Functions
Jun 01, 2022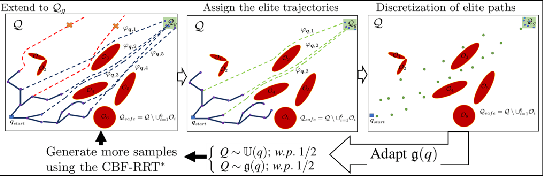
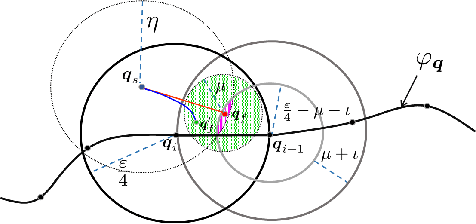
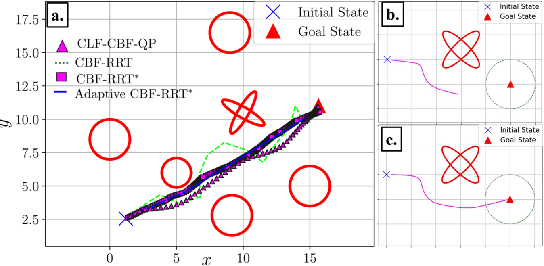
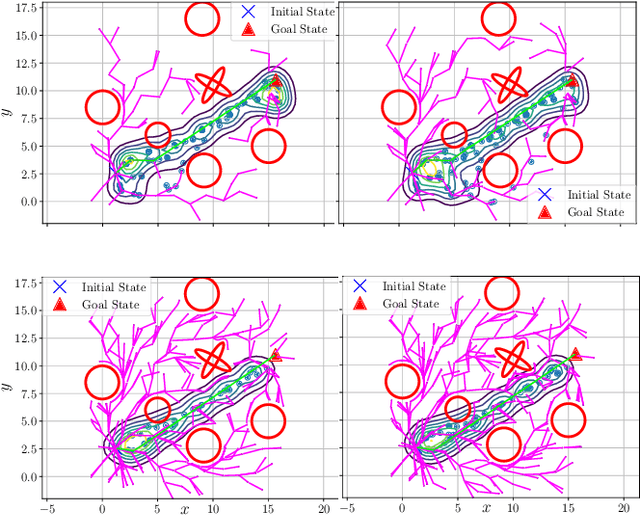
Sampling-based algorithms, such as Rapidly Exploring Random Trees (RRT) and its variants, have been used extensively for motion planning. Control barrier functions (CBFs) have been recently proposed to synthesize controllers for safety-critical systems. In this paper, we combine the effectiveness of RRT-based algorithms with the safety guarantees provided by CBFs in a method called CBF-RRT$^\ast$. CBFs are used for local trajectory planning for RRT$^\ast$, avoiding explicit collision checking of the extended paths. We prove that CBF-RRT$^\ast$ preserves the probabilistic completeness of RRT$^\ast$. Furthermore, in order to improve the sampling efficiency of the algorithm, we equip the algorithm with an adaptive sampling procedure, which is based on the cross-entropy method (CEM) for importance sampling (IS). The procedure exploits the tree of samples to focus the sampling in promising regions of the configuration space. We demonstrate the efficacy of the proposed algorithms through simulation examples.