 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Complete Online Decentralized Multi-Agent Pathfinding with Rapid Information Sharing using Motion Constraints
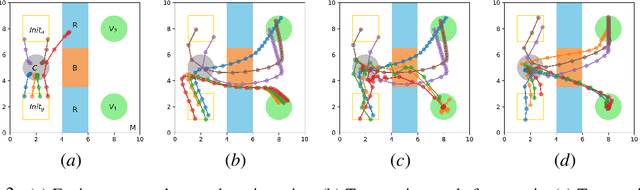
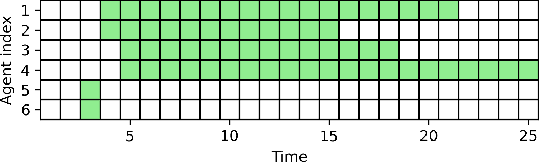
May 12, 2025We introduce PRISM (Pathfinding with Rapid Information Sharing using Motion Constraints), a decentralized algorithm designed to address the multi-task multi-agent pathfinding (MT-MAPF) problem. PRISM enables large teams of agents to concurrently plan safe and efficient paths for multiple tasks while avoiding collisions. It employs a rapid communication strategy that uses information packets to exchange motion constraint information, enhancing cooperative pathfinding and situational awareness, even in scenarios without direct communication. We prove that PRISM resolves and avoids all deadlock scenarios when possible, a critical challenge in decentralized pathfinding. Empirically, we evaluate PRISM across five environments and 25 random scenarios, benchmarking it against the centralized Conflict-Based Search (CBS) and the decentralized Token Passing with Task Swaps (TPTS) algorithms. PRISM demonstrates scalability and solution quality, supporting 3.4 times more agents than CBS and handling up to 2.5 times more tasks in narrow passage environments than TPTS. Additionally, PRISM matches CBS in solution quality while achieving faster computation times, even under low-connectivity conditions. Its decentralized design reduces the computational burden on individual agents, making it scalable for large environments. These results confirm PRISM's robustness, scalability, and effectiveness in complex and dynamic pathfinding scenarios.
Solving Multi-Agent Safe Optimal Control with Distributed Epigraph Form MARL
Apr 21, 2025Tasks for multi-robot systems often require the robots to collaborate and complete a team goal while maintaining safety. This problem is usually formalized as a constrained Markov decision process (CMDP), which targets minimizing a global cost and bringing the mean of constraint violation below a user-defined threshold. Inspired by real-world robotic applications, we define safety as zero constraint violation. While many safe multi-agent reinforcement learning (MARL) algorithms have been proposed to solve CMDPs, these algorithms suffer from unstable training in this setting. To tackle this, we use the epigraph form for constrained optimization to improve training stability and prove that the centralized epigraph form problem can be solved in a distributed fashion by each agent. This results in a novel centralized training distributed execution MARL algorithm named Def-MARL. Simulation experiments on 8 different tasks across 2 different simulators show that Def-MARL achieves the best overall performance, satisfies safety constraints, and maintains stable training. Real-world hardware experiments on Crazyflie quadcopters demonstrate the ability of Def-MARL to safely coordinate agents to complete complex collaborative tasks compared to other methods.
From Abstraction to Reality: DARPA's Vision for Robust Sim-to-Real Autonomy
Mar 14, 2025
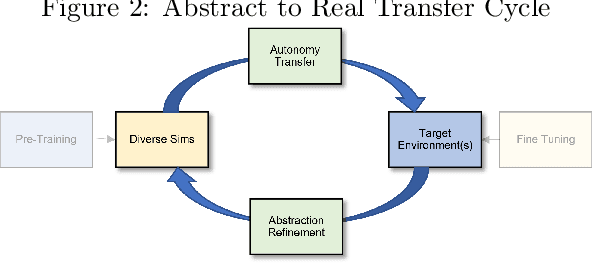


The DARPA Transfer from Imprecise and Abstract Models to Autonomous Technologies (TIAMAT) program aims to address rapid and robust transfer of autonomy technologies across dynamic and complex environments, goals, and platforms. Existing methods for simulation-to-reality (sim-to-real) transfer often rely on high-fidelity simulations and struggle with broad adaptation, particularly in time-sensitive scenarios. Although many approaches have shown incredible performance at specific tasks, most techniques fall short when posed with unforeseen, complex, and dynamic real-world scenarios due to the inherent limitations of simulation. In contrast to current research that aims to bridge the gap between simulation environments and the real world through increasingly sophisticated simulations and a combination of methods typically assuming a small sim-to-real gap -- such as domain randomization, domain adaptation, imitation learning, meta-learning, policy distillation, and dynamic optimization -- TIAMAT takes a different approach by instead emphasizing transfer and adaptation of the autonomy stack directly to real-world environments by utilizing a breadth of low(er)-fidelity simulations to create broadly effective sim-to-real transfers. By abstractly learning from multiple simulation environments in reference to their shared semantics, TIAMAT's approaches aim to achieve abstract-to-real transfer for effective and rapid real-world adaptation. Furthermore, this program endeavors to improve the overall autonomy pipeline by addressing the inherent challenges in translating simulated behaviors into effective real-world performance.
Accelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Games with Delayed Rewards
Nov 26, 2024
In this paper, we tackle the challenging problem of delayed rewards in reinforcement learning (RL). While Proximal Policy Optimization (PPO) has emerged as a leading Policy Gradient method, its performance can degrade under delayed rewards. We introduce two key enhancements to PPO: a hybrid policy architecture that combines an offline policy (trained on expert demonstrations) with an online PPO policy, and a reward shaping mechanism using Time Window Temporal Logic (TWTL). The hybrid architecture leverages offline data throughout training while maintaining PPO's theoretical guarantees. Building on the monotonic improvement framework of Trust Region Policy Optimization (TRPO), we prove that our approach ensures improvement over both the offline policy and previous iterations, with a bounded performance gap of $(2\varsigma\gamma\alpha^2)/(1-\gamma)^2$, where $\alpha$ is the mixing parameter, $\gamma$ is the discount factor, and $\varsigma$ bounds the expected advantage. Additionally, we prove that our TWTL-based reward shaping preserves the optimal policy of the original problem. TWTL enables formal translation of temporal objectives into immediate feedback signals that guide learning. We demonstrate the effectiveness of our approach through extensive experiments on an inverted pendulum and a lunar lander environments, showing improvements in both learning speed and final performance compared to standard PPO and offline-only approaches.
RPCBF: Constructing Safety Filters Robust to Model Error and Disturbances via Policy Control Barrier Functions
Oct 15, 2024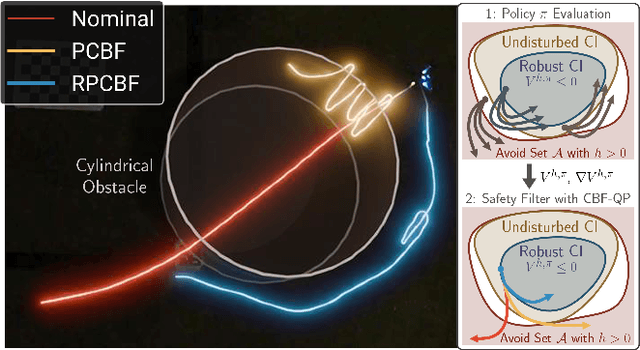
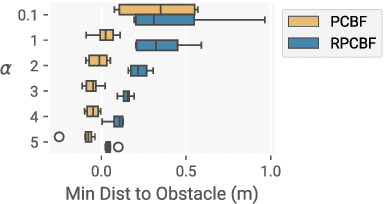

Control Barrier Functions (CBFs) have proven to be an effective tool for performing safe control synthesis for nonlinear systems. However, guaranteeing safety in the presence of disturbances and input constraints for high relative degree systems is a difficult problem. In this work, we propose the Robust Policy CBF (RPCBF), a practical method of constructing CBF approximations that is easy to implement and robust to disturbances via the estimation of a value function. We demonstrate the effectiveness of our method in simulation on a variety of high relative degree input-constrained systems. Finally, we demonstrate the benefits of RPCBF in compensating for model errors on a hardware quadcopter platform by treating the model errors as disturbances. The project page can be found at https://oswinso.xyz/rpcbf.
Temporal Logic Planning via Zero-Shot Policy Composition
Aug 08, 2024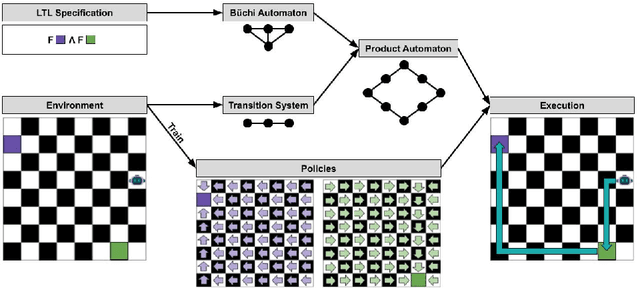
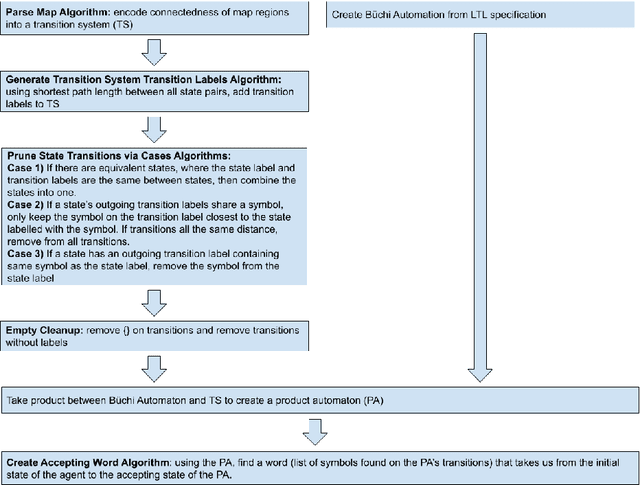
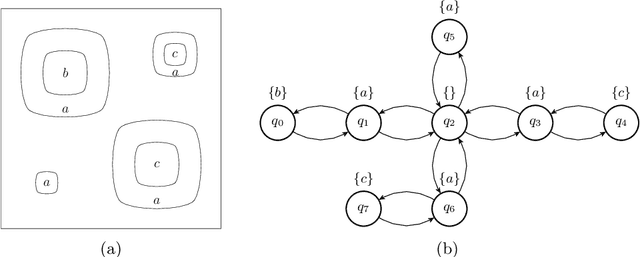
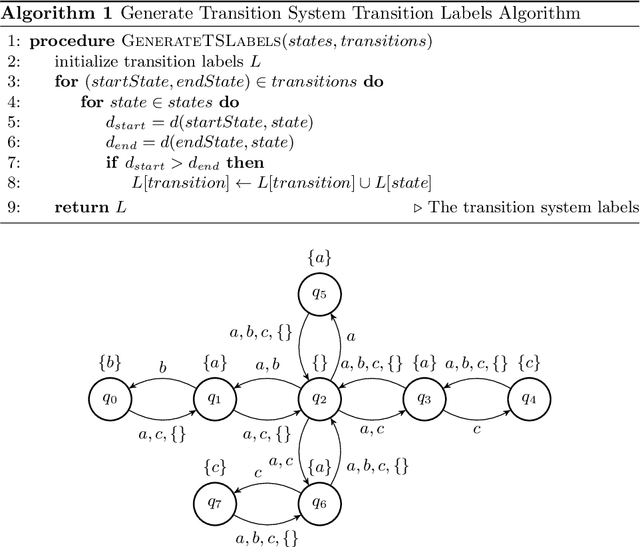
This work develops a zero-shot mechanism for an agent to satisfy a Linear Temporal Logic (LTL) specification given existing task primitives. Oftentimes, autonomous robots need to satisfy spatial and temporal goals that are unknown until run time. Prior research addresses the problem by learning policies that are capable of executing a high-level task specified using LTL, but they incorporate the specification into the learning process; therefore, any change to the specification requires retraining the policy. Other related research addresses the problem by creating skill-machines which, given a specification change, do not require full policy retraining but require fine-tuning on the skill-machine to guarantee satisfaction. We present a more a flexible approach -- to learn a set of minimum-violation (MV) task primitive policies that can be used to satisfy arbitrary LTL specifications without retraining or fine-tuning. Task primitives can be learned offline using reinforcement learning (RL) methods and combined using Boolean composition at deployment. This work focuses on creating and pruning a transition system (TS) representation of the environment in order to solve for deterministic, non-ambiguous, and feasible solutions to LTL specifications given an environment and a set of MV task primitive policies. We show that our pruned TS is deterministic, contains no unrealizable transitions, and is sound. Through simulation, we show that our approach is executable and we verify our MV policies produce the expected symbols.
Evaluating Collaborative Autonomy in Opposed Environments using Maritime Capture-the-Flag Competitions
Apr 25, 2024



The objective of this work is to evaluate multi-agent artificial intelligence methods when deployed on teams of unmanned surface vehicles (USV) in an adversarial environment. Autonomous agents were evaluated in real-world scenarios using the Aquaticus test-bed, which is a Capture-the-Flag (CTF) style competition involving teams of USV systems. Cooperative teaming algorithms of various foundations in behavior-based optimization and deep reinforcement learning (RL) were deployed on these USV systems in two versus two teams and tested against each other during a competition period in the fall of 2023. Deep reinforcement learning applied to USV agents was achieved via the Pyquaticus test bed, a lightweight gymnasium environment that allows simulated CTF training in a low-level environment. The results of the experiment demonstrate that rule-based cooperation for behavior-based agents outperformed those trained in Deep-reinforcement learning paradigms as implemented in these competitions. Further integration of the Pyquaticus gymnasium environment for RL with MOOS-IvP in terms of configuration and control schema will allow for more competitive CTF games in future studies. As the development of experimental deep RL methods continues, the authors expect that the competitive gap between behavior-based autonomy and deep RL will be reduced. As such, this report outlines the overall competition, methods, and results with an emphasis on future works such as reward shaping and sim-to-real methodologies and extending rule-based cooperation among agents to react to safety and security events in accordance with human experts intent/rules for executing safety and security processes.
How to Train Your Neural Control Barrier Function: Learning Safety Filters for Complex Input-Constrained Systems
Oct 27, 2023Control barrier functions (CBF) have become popular as a safety filter to guarantee the safety of nonlinear dynamical systems for arbitrary inputs. However, it is difficult to construct functions that satisfy the CBF constraints for high relative degree systems with input constraints. To address these challenges, recent work has explored learning CBFs using neural networks via neural CBF (NCBF). However, such methods face difficulties when scaling to higher dimensional systems under input constraints. In this work, we first identify challenges that NCBFs face during training. Next, to address these challenges, we propose policy neural CBF (PNCBF), a method of constructing CBFs by learning the value function of a nominal policy, and show that the value function of the maximum-over-time cost is a CBF. We demonstrate the effectiveness of our method in simulation on a variety of systems ranging from toy linear systems to an F-16 jet with a 16-dimensional state space. Finally, we validate our approach on a two-agent quadcopter system on hardware under tight input constraints.
Safety-Aware Task Composition for Discrete and Continuous Reinforcement Learning
Jun 29, 2023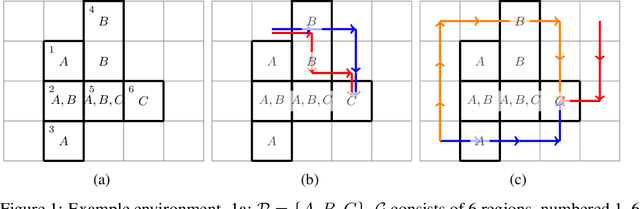

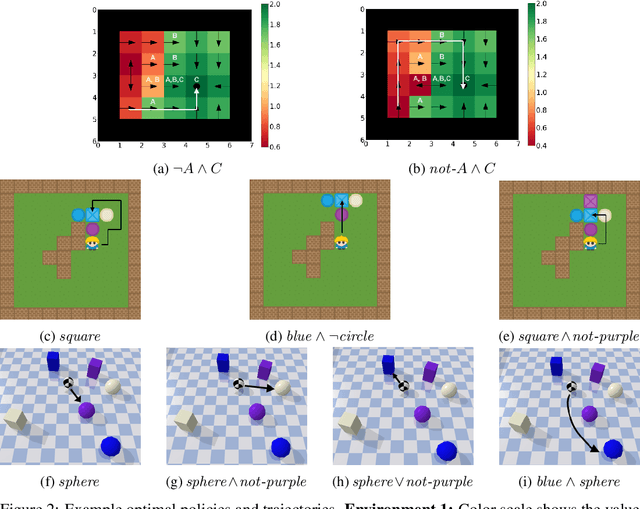
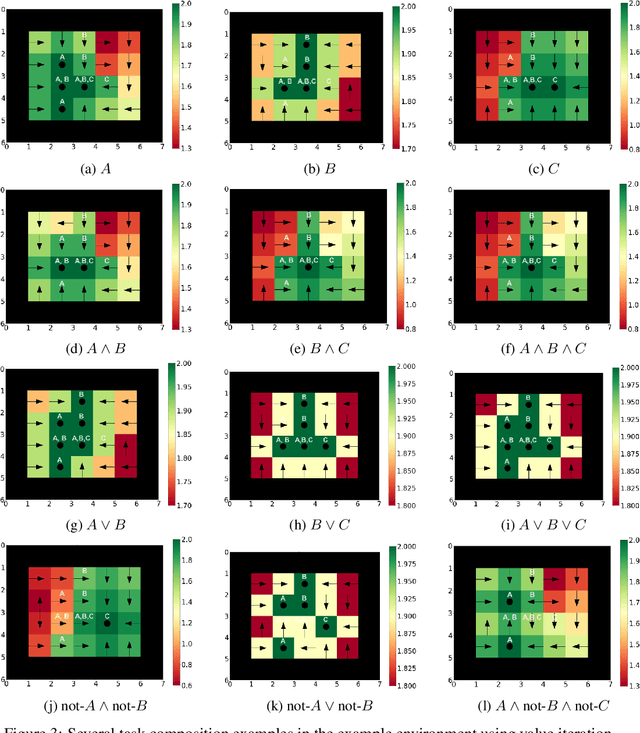
Compositionality is a critical aspect of scalable system design. Reinforcement learning (RL) has recently shown substantial success in task learning, but has only recently begun to truly leverage composition. In this paper, we focus on Boolean composition of learned tasks as opposed to functional or sequential composition. Existing Boolean composition for RL focuses on reaching a satisfying absorbing state in environments with discrete action spaces, but does not support composable safety (i.e., avoidance) constraints. We advance the state of the art in Boolean composition of learned tasks with three contributions: i) introduce two distinct notions of safety in this framework; ii) show how to enforce either safety semantics, prove correctness (under some assumptions), and analyze the trade-offs between the two safety notions; and iii) extend Boolean composition from discrete action spaces to continuous action spaces. We demonstrate these techniques using modified versions of value iteration in a grid world, Deep Q-Network (DQN) in a grid world with image observations, and Twin Delayed DDPG (TD3) in a continuous-observation and continuous-action Bullet physics environment. We believe that these contributions advance the theory of safe reinforcement learning by allowing zero-shot composition of policies satisfying safety properties.
CatlNet: Learning Communication and Coordination Policies from CaTL+ Specifications
Nov 30, 2022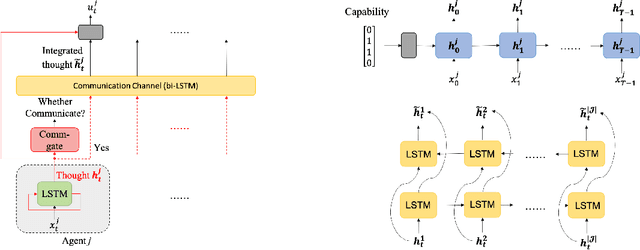
In this paper, we propose a learning-based framework to simultaneously learn the communication and distributed control policies for a heterogeneous multi-agent system (MAS) under complex mission requirements from Capability Temporal Logic plus (CaTL+) specifications. Both policies are trained, implemented, and deployed using a novel neural network model called CatlNet. Taking advantage of the robustness measure of CaTL+, we train CatlNet centrally to maximize it where network parameters are shared among all agents, allowing CatlNet to scale to large teams easily. CatlNet can then be deployed distributedly. A plan repair algorithm is also introduced to guide CatlNet's training and improve both training efficiency and the overall performance of CatlNet. The CatlNet approach is tested in simulation and results show that, after training, CatlNet can steer the decentralized MAS system online to satisfy a CaTL+ specification with a high success rate.