 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Logic Planning via Zero-Shot Policy Composition
Paper and Code
Aug 08, 2024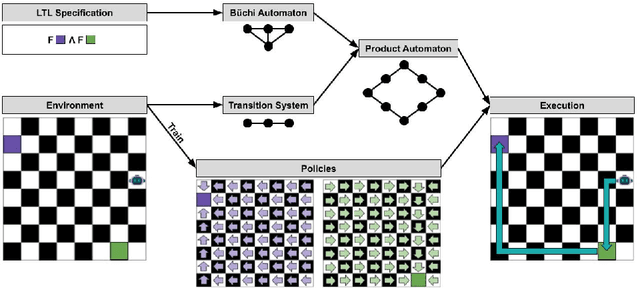
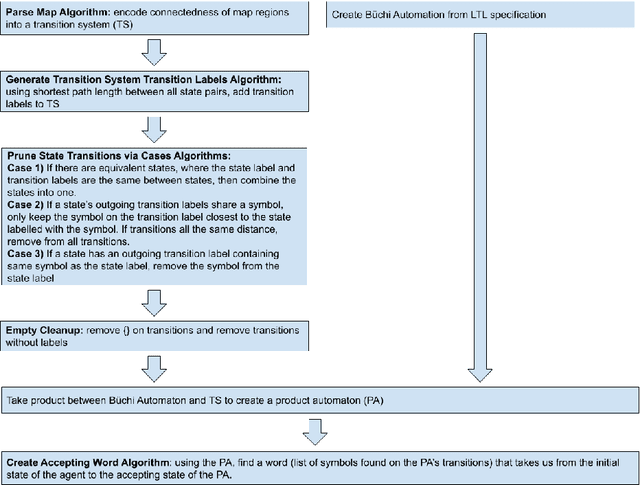
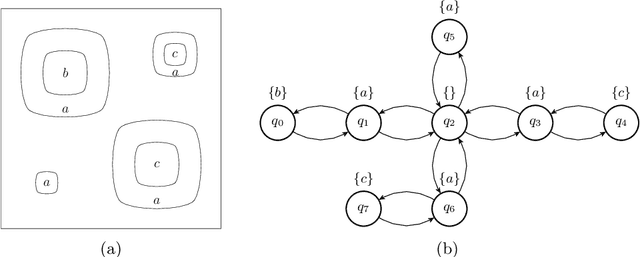
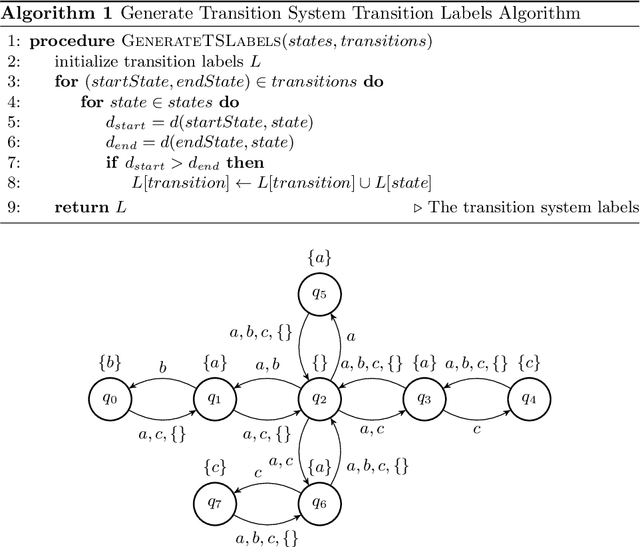
This work develops a zero-shot mechanism for an agent to satisfy a Linear Temporal Logic (LTL) specification given existing task primitives. Oftentimes, autonomous robots need to satisfy spatial and temporal goals that are unknown until run time. Prior research addresses the problem by learning policies that are capable of executing a high-level task specified using LTL, but they incorporate the specification into the learning process; therefore, any change to the specification requires retraining the policy. Other related research addresses the problem by creating skill-machines which, given a specification change, do not require full policy retraining but require fine-tuning on the skill-machine to guarantee satisfaction. We present a more a flexible approach -- to learn a set of minimum-violation (MV) task primitive policies that can be used to satisfy arbitrary LTL specifications without retraining or fine-tuning. Task primitives can be learned offline using reinforcement learning (RL) methods and combined using Boolean composition at deployment. This work focuses on creating and pruning a transition system (TS) representation of the environment in order to solve for deterministic, non-ambiguous, and feasible solutions to LTL specifications given an environment and a set of MV task primitive policies. We show that our pruned TS is deterministic, contains no unrealizable transitions, and is sound. Through simulation, we show that our approach is executable and we verify our MV policies produce the expected symbols.