 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Guided Coevolution: Improved Team Formation in Multiagent Adversarial Games
Oct 17, 2024



We consider the problem of team formation within multiagent adversarial games. We propose BERTeam, a novel algorithm that uses a transformer-based deep neural network with Masked Language Model training to select the best team of players from a trained population. We integrate this with coevolutionary deep reinforcement learning, which trains a diverse set of individual players to choose teams from. We test our algorithm in the multiagent adversarial game Marine Capture-The-Flag, and we find that BERTeam learns non-trivial team compositions that perform well against unseen opponents. For this game, we find that BERTeam outperforms MCAA, an algorithm that similarly optimizes team formation.
Evaluating Collaborative Autonomy in Opposed Environments using Maritime Capture-the-Flag Competitions
Apr 25, 2024



The objective of this work is to evaluate multi-agent artificial intelligence methods when deployed on teams of unmanned surface vehicles (USV) in an adversarial environment. Autonomous agents were evaluated in real-world scenarios using the Aquaticus test-bed, which is a Capture-the-Flag (CTF) style competition involving teams of USV systems. Cooperative teaming algorithms of various foundations in behavior-based optimization and deep reinforcement learning (RL) were deployed on these USV systems in two versus two teams and tested against each other during a competition period in the fall of 2023. Deep reinforcement learning applied to USV agents was achieved via the Pyquaticus test bed, a lightweight gymnasium environment that allows simulated CTF training in a low-level environment. The results of the experiment demonstrate that rule-based cooperation for behavior-based agents outperformed those trained in Deep-reinforcement learning paradigms as implemented in these competitions. Further integration of the Pyquaticus gymnasium environment for RL with MOOS-IvP in terms of configuration and control schema will allow for more competitive CTF games in future studies. As the development of experimental deep RL methods continues, the authors expect that the competitive gap between behavior-based autonomy and deep RL will be reduced. As such, this report outlines the overall competition, methods, and results with an emphasis on future works such as reward shaping and sim-to-real methodologies and extending rule-based cooperation among agents to react to safety and security events in accordance with human experts intent/rules for executing safety and security processes.
Reward Shaping for Improved Learning in Real-time Strategy Game Play
Nov 27, 2023We investigate the effect of reward shaping in improving the performance of reinforcement learning in the context of the real-time strategy, capture-the-flag game. The game is characterized by sparse rewards that are associated with infrequently occurring events such as grabbing or capturing the flag, or tagging the opposing player. We show that appropriately designed reward shaping functions applied to different game events can significantly improve the player's performance and training times of the player's learning algorithm. We have validated our reward shaping functions within a simulated environment for playing a marine capture-the-flag game between two players. Our experimental results demonstrate that reward shaping can be used as an effective means to understand the importance of different sub-tasks during game-play towards winning the game, to encode a secondary objective functions such as energy efficiency into a player's game-playing behavior, and, to improve learning generalizable policies that can perform well against different skill levels of the opponent.
Divide and Repair: Using Options to Improve Performance of Imitation Learning Against Adversarial Demonstrations
Jun 09, 2023We consider the problem of learning to perform a task from demonstrations given by teachers or experts, when some of the experts' demonstrations might be adversarial and demonstrate an incorrect way to perform the task. We propose a novel technique that can identify parts of demonstrated trajectories that have not been significantly modified by the adversary and utilize them for learning, using temporally extended policies or options. We first define a trajectory divergence measure based on the spatial and temporal features of demonstrated trajectories to detect and discard parts of the trajectories that have been significantly modified by an adversarial expert, and, could degrade the learner's performance, if used for learning, We then use an options-based algorithm that partitions trajectories and learns only from the parts of trajectories that have been determined as admissible. We provide theoretical results of our technique to show that repairing partial trajectories improves the sample efficiency of the demonstrations without degrading the learner's performance. We then evaluate the proposed algorithm for learning to play an Atari-like, computer-based game called LunarLander in the presence of different types and degrees of adversarial attacks of demonstrated trajectories. Our experimental results show that our technique can identify adversarially modified parts of the demonstrated trajectories and successfully prevent the learning performance from degrading due to adversarial demonstrations.
Synthetically Generating Human-like Data for Sequential Decision Making Tasks via Reward-Shaped Imitation Learning
Apr 14, 2023We consider the problem of synthetically generating data that can closely resemble human decisions made in the context of an interactive human-AI system like a computer game. We propose a novel algorithm that can generate synthetic, human-like, decision making data while starting from a very small set of decision making data collected from humans. Our proposed algorithm integrates the concept of reward shaping with an imitation learning algorithm to generate the synthetic data. We have validated our synthetic data generation technique by using the synthetically generated data as a surrogate for human interaction data to solve three sequential decision making tasks of increasing complexity within a small computer game-like setup. Different empirical and statistical analyses of our results show that the synthetically generated data can substitute the human data and perform the game-playing tasks almost indistinguishably, with very low divergence, from a human performing the same tasks.
A Comparison of State-of-the-Art Techniques for Generating Adversarial Malware Binaries
Nov 22, 2021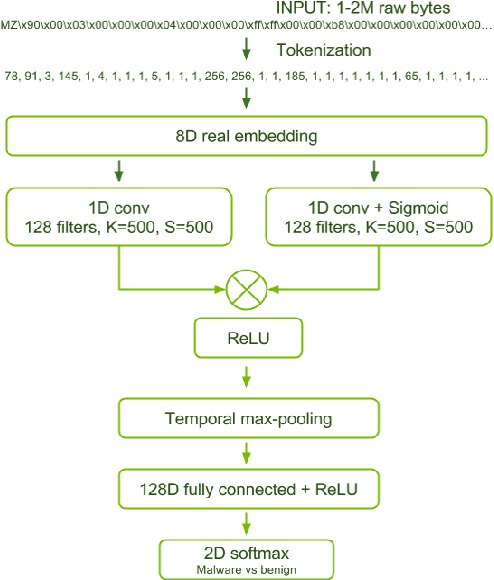
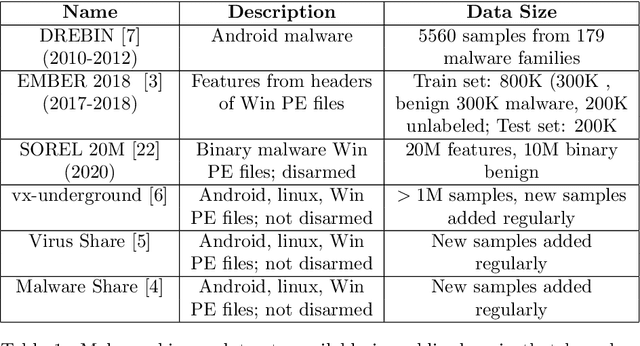
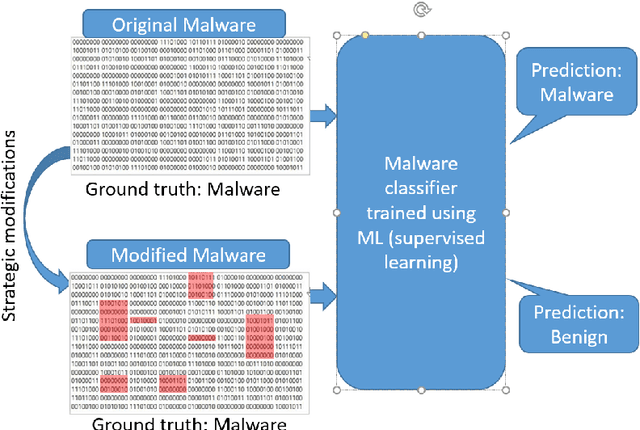

We consider the problem of generating adversarial malware by a cyber-attacker where the attacker's task is to strategically modify certain bytes within existing binary malware files, so that the modified files are able to evade a malware detector such as machine learning-based malware classifier. We have evaluated three recent adversarial malware generation techniques using binary malware samples drawn from a single, publicly available malware data set and compared their performances for evading a machine-learning based malware classifier called MalConv. Our results show that among the compared techniques, the most effective technique is the one that strategically modifies bytes in a binary's header. We conclude by discussing the lessons learned and future research directions on the topic of adversarial malware generation.
Playing to Learn Better: Repeated Games for Adversarial Learning with Multiple Classifiers
Feb 10, 2020



We consider the problem of prediction by a machine learning algorithm, called learner, within an adversarial learning setting. The learner's task is to correctly predict the class of data passed to it as a query. However, along with queries containing clean data, the learner could also receive malicious or adversarial queries from an adversary. The objective of the adversary is to evade the learner's prediction mechanism by sending adversarial queries that result in erroneous class prediction by the learner, while the learner's objective is to reduce the incorrect prediction of these adversarial queries without degrading the prediction quality of clean queries. We propose a game theory-based technique called a Repeated Bayesian Sequential Game where the learner interacts repeatedly with a model of the adversary using self play to determine the distribution of adversarial versus clean queries. It then strategically selects a classifier from a set of pre-trained classifiers that balances the likelihood of correct prediction for the query along with reducing the costs to use the classifier. We have evaluated our proposed technique using clean and adversarial text data with deep neural network-based classifiers and shown that the learner can select an appropriate classifier that is commensurate with the query type (clean or adversarial) while remaining aware of the cost to use the classifier.
A Survey of Game Theoretic Approaches for Adversarial Machine Learning in Cybersecurity Tasks
Dec 04, 2019


Machine learning techniques are currently used extensively for automating various cybersecurity tasks. Most of these techniques utilize supervised learning algorithms that rely on training the algorithm to classify incoming data into different categories, using data encountered in the relevant domain. A critical vulnerability of these algorithms is that they are susceptible to adversarial attacks where a malicious entity called an adversary deliberately alters the training data to misguide the learning algorithm into making classification errors. Adversarial attacks could render the learning algorithm unsuitable to use and leave critical systems vulnerable to cybersecurity attacks. Our paper provides a detailed survey of the state-of-the-art techniques that are used to make a machine learning algorithm robust against adversarial attacks using the computational framework of game theory. We also discuss open problems and challenges and possible directions for further research that would make deep machine learning-based systems more robust and reliable for cybersecurity tasks.
* 13 pages, 2 figures, 1 table
Simultaneous Configuration Formation and Information Collection by Modular Robotic Systems
Oct 18, 2016


We consider the configuration formation problem in modular robotic systems where a set of singleton modules that are spatially distributed in an environment are required to assume appropriate positions so that they can configure into a new, user-specified target configuration, while simultaneously maximizing the amount of information collected while navigating from their initial to final positions. Each module has a limited energy budget to expend while moving from its initial to goal location. To solve this problem, we propose a budget-limited, heuristic search-based algorithm that finds a path that maximizes the entropy of the expected information along the path. We have analytically proved that our proposed approach converges within finite time. Experimental results show that our planning approach has lower run-time than an auction-based allocation algorithm for selecting modules' spots.
Integrated Task and Motion Planning for Multiple Robots under Path and Communication Uncertainties
Jul 02, 2016



We consider a problem called task ordering with path uncertainty (TOP-U) where multiple robots are provided with a set of task locations to visit in a bounded environment, but the length of the path between a pair of task locations is initially known only coarsely by the robots. The objective of the robots is to find the order of tasks that reduces the path length (or, energy expended) to visit the task locations in such a scenario. To solve this problem, we propose an abstraction called a task reachability graph (TRG) that integrates the task ordering with the path planning by the robots. The TRG is updated dynamically based on inter-task path costs calculated using a sampling-based motion planner, and, a Hidden Markov Model (HMM)-based technique that calculates the belief in the current path costs based on the environment perceived by the robot's sensors and task completion information received from other robots. We then describe a Markov Decision Process (MDP)-based algorithm that can select the paths that reduce the overall path length to visit the task locations and a coordination algorithm that resolves path conflicts between robots. We have shown analytically that our task selection algorithm finds the lowest cost path returned by the motion planner, and, that our proposed coordination algorithm is deadlock free. We have also evaluated our algorithm on simulated Corobot robots within different environments while varying the number of task locations, obstacle geometries and number of robots, as well as on physical Corobot robots. Our results show that the TRG-based approach can perform considerably better in planning and locomotion times, and number of re-plans, while traveling almost-similar distances as compared to a closest first, no uncertainty (CFNU) task selection algorithm.