 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Deployment of a Hierarchical Uncertainty-Aware Collaborative Multiagent Planning System
Apr 26, 2024



We would like to enable a collaborative multiagent team to navigate at long length scales and under uncertainty in real-world environments. In practice, planning complexity scales with the number of agents in the team, with the length scale of the environment, and with environmental uncertainty. Enabling tractable planning requires developing abstract models that can represent complex, high-quality plans. However, such models often abstract away information needed to generate directly-executable plans for real-world agents in real-world environments, as planning in such detail, especially in the presence of real-world uncertainty, would be computationally intractable. In this paper, we describe the deployment of a planning system that used a hierarchy of planners to execute collaborative multiagent navigation tasks in real-world, unknown environments. By developing a planning system that was robust to failures at every level of the planning hierarchy, we enabled the team to complete collaborative navigation tasks, even in the presence of imperfect planning abstractions and real-world uncertainty. We deployed our approach on a Clearpath Husky-Jackal team navigating in a structured outdoor environment, and demonstrated that the system enabled the agents to successfully execute collaborative plans.
Evaluating Collaborative Autonomy in Opposed Environments using Maritime Capture-the-Flag Competitions
Apr 25, 2024



The objective of this work is to evaluate multi-agent artificial intelligence methods when deployed on teams of unmanned surface vehicles (USV) in an adversarial environment. Autonomous agents were evaluated in real-world scenarios using the Aquaticus test-bed, which is a Capture-the-Flag (CTF) style competition involving teams of USV systems. Cooperative teaming algorithms of various foundations in behavior-based optimization and deep reinforcement learning (RL) were deployed on these USV systems in two versus two teams and tested against each other during a competition period in the fall of 2023. Deep reinforcement learning applied to USV agents was achieved via the Pyquaticus test bed, a lightweight gymnasium environment that allows simulated CTF training in a low-level environment. The results of the experiment demonstrate that rule-based cooperation for behavior-based agents outperformed those trained in Deep-reinforcement learning paradigms as implemented in these competitions. Further integration of the Pyquaticus gymnasium environment for RL with MOOS-IvP in terms of configuration and control schema will allow for more competitive CTF games in future studies. As the development of experimental deep RL methods continues, the authors expect that the competitive gap between behavior-based autonomy and deep RL will be reduced. As such, this report outlines the overall competition, methods, and results with an emphasis on future works such as reward shaping and sim-to-real methodologies and extending rule-based cooperation among agents to react to safety and security events in accordance with human experts intent/rules for executing safety and security processes.
A Monte Carlo Approach to Closing the Reality Gap
May 08, 2020
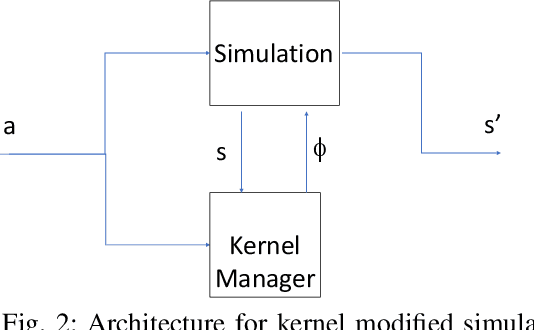
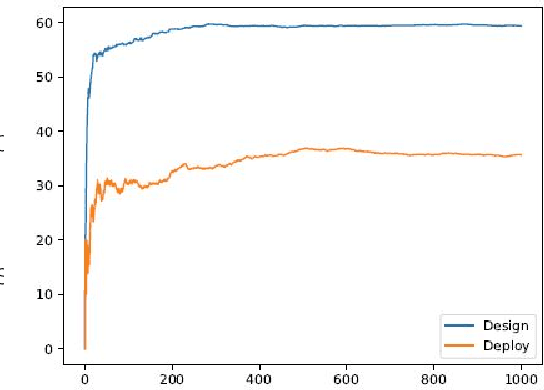
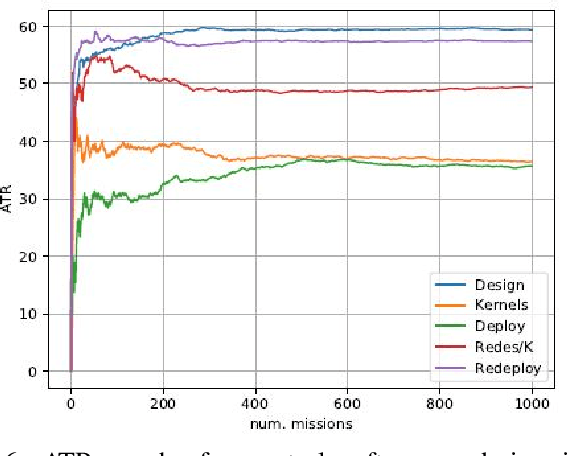
We propose a novel approach to the 'reality gap' problem, i.e., modifying a robot simulation so that its performance becomes more similar to observed real world phenomena. This problem arises whether the simulation is being used by human designers or in an automated policy development mechanism. We expect that the program/policy is developed using simulation, and subsequently deployed on a real system. We further assume that the program includes a monitor procedure with scalar output to determine when it is achieving its performance objectives. The proposed approach collects simulation and real world observations and builds conditional probability functions. These are used to generate paired roll-outs to identify points of divergence in behavior. These are used to generate {\it state-space kernels} that coerce the simulation into behaving more like observed reality. The method was evaluated using ROS/Gazebo for simulation and a heavily modified Traaxas platform in outdoor deployment. The results support not just that the kernel approach can force the simulation to behave more like reality, but that the modification is such that an improved control policy tested in the modified simulation also performs better in the real world.