 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl Barrier Functions via Minkowski Operations for Safe Navigation among Polytopic Sets
Apr 01, 2025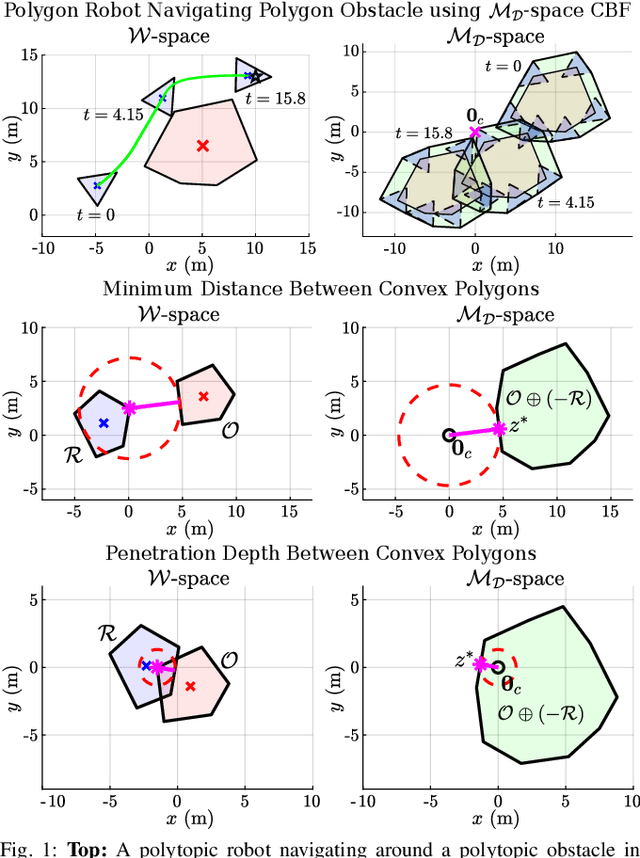
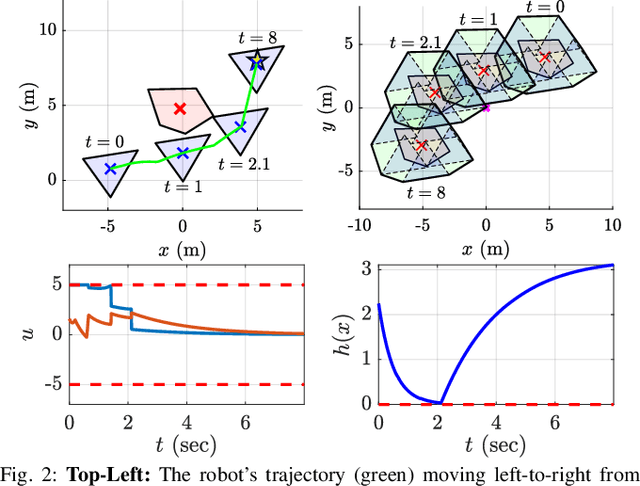
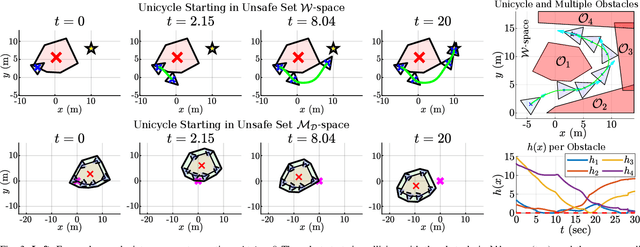

Safely navigating around obstacles while respecting the dynamics, control, and geometry of the underlying system is a key challenge in robotics. Control Barrier Functions (CBFs) generate safe control policies by considering system dynamics and geometry when calculating safe forward-invariant sets. Existing CBF-based methods often rely on conservative shape approximations, like spheres or ellipsoids, which have explicit and differentiable distance functions. In this paper, we propose an optimization-defined CBF that directly considers the exact Signed Distance Function (SDF) between a polytopic robot and polytopic obstacles. Inspired by the Gilbert-Johnson-Keerthi (GJK) algorithm, we formulate both (i) minimum distance and (ii) penetration depth between polytopic sets as convex optimization problems in the space of Minkowski difference operations (the MD-space). Convenient geometric properties of the MD-space enable the derivatives of implicit SDF between two polytopes to be computed via differentiable optimization. We demonstrate the proposed framework in three scenarios including pure translation, initialization inside an unsafe set, and multi-obstacle avoidance. These three scenarios highlight the generation of a non-conservative maneuver, a recovery after starting in collision, and the consideration of multiple obstacles via pairwise CBF constraint, respectively.
Accelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Games with Delayed Rewards
Nov 26, 2024
In this paper, we tackle the challenging problem of delayed rewards in reinforcement learning (RL). While Proximal Policy Optimization (PPO) has emerged as a leading Policy Gradient method, its performance can degrade under delayed rewards. We introduce two key enhancements to PPO: a hybrid policy architecture that combines an offline policy (trained on expert demonstrations) with an online PPO policy, and a reward shaping mechanism using Time Window Temporal Logic (TWTL). The hybrid architecture leverages offline data throughout training while maintaining PPO's theoretical guarantees. Building on the monotonic improvement framework of Trust Region Policy Optimization (TRPO), we prove that our approach ensures improvement over both the offline policy and previous iterations, with a bounded performance gap of $(2\varsigma\gamma\alpha^2)/(1-\gamma)^2$, where $\alpha$ is the mixing parameter, $\gamma$ is the discount factor, and $\varsigma$ bounds the expected advantage. Additionally, we prove that our TWTL-based reward shaping preserves the optimal policy of the original problem. TWTL enables formal translation of temporal objectives into immediate feedback signals that guide learning. We demonstrate the effectiveness of our approach through extensive experiments on an inverted pendulum and a lunar lander environments, showing improvements in both learning speed and final performance compared to standard PPO and offline-only approaches.
Control of Microrobots Using Model Predictive Control and Gaussian Processes for Disturbance Estimation
Jun 04, 2024



This paper presents a control framework for magnetically actuated micron-scale robots ($\mu$bots) designed to mitigate disturbances and improve trajectory tracking. To address the challenges posed by unmodeled dynamics and environmental variability, we combine data-driven modeling with model-based control to accurately track desired trajectories using a relatively small amount of data. The system is represented with a simple linear model, and Gaussian Processes (GP) are employed to capture and estimate disturbances. This disturbance-enhanced model is then integrated into a Model Predictive Controller (MPC). Our approach demonstrates promising performance in both simulation and experimental setups, showcasing its potential for precise and reliable microrobot control in complex environments.
Interpretable Generative Adversarial Imitation Learning
Feb 15, 2024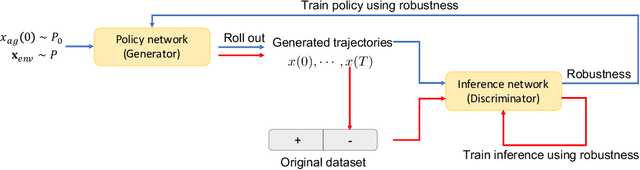
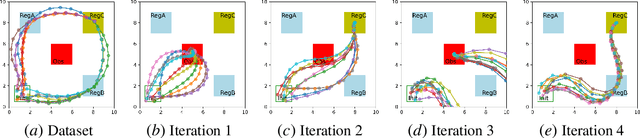
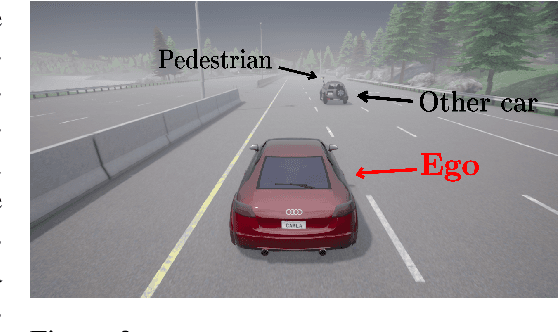
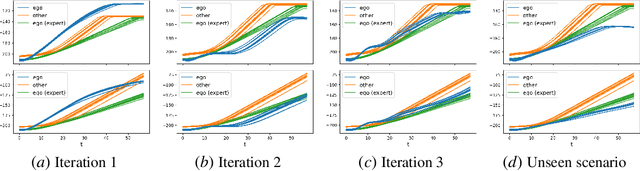
Imitation learning methods have demonstrated considerable success in teaching autonomous systems complex tasks through expert demonstrations. However, a limitation of these methods is their lack of interpretability, particularly in understanding the specific task the learning agent aims to accomplish. In this paper, we propose a novel imitation learning method that combines Signal Temporal Logic (STL) inference and control synthesis, enabling the explicit representation of the task as an STL formula. This approach not only provides a clear understanding of the task but also allows for the incorporation of human knowledge and adaptation to new scenarios through manual adjustments of the STL formulae. Additionally, we employ a Generative Adversarial Network (GAN)-inspired training approach for both the inference and the control policy, effectively narrowing the gap between the expert and learned policies. The effectiveness of our algorithm is demonstrated through two case studies, showcasing its practical applicability and adaptability.
Learning Robust and Correct Controllers from Signal Temporal Logic Specifications Using BarrierNet
Apr 12, 2023


In this paper, we consider the problem of learning a neural network controller for a system required to satisfy a Signal Temporal Logic (STL) specification. We exploit STL quantitative semantics to define a notion of robust satisfaction. Guaranteeing the correctness of a neural network controller, i.e., ensuring the satisfaction of the specification by the controlled system, is a difficult problem that received a lot of attention recently. We provide a general procedure to construct a set of trainable High Order Control Barrier Functions (HOCBFs) enforcing the satisfaction of formulas in a fragment of STL. We use the BarrierNet, implemented by a differentiable Quadratic Program (dQP) with HOCBF constraints, as the last layer of the neural network controller, to guarantee the satisfaction of the STL formulas. We train the HOCBFs together with other neural network parameters to further improve the robustness of the controller. Simulation results demonstrate that our approach ensures satisfaction and outperforms existing algorithms.
Efficient LQR-CBF-RRT*: Safe and Optimal Motion Planning
Apr 04, 2023



Control Barrier Functions (CBF) are a powerful tool for designing safety-critical controllers and motion planners. The safety requirements are encoded as a continuously differentiable function that maps from state variables to a real value, in which the sign of its output determines whether safety is violated. In practice, the CBFs can be used to enforce safety by imposing itself as a constraint in a Quadratic Program (QP) solved point-wise in time. However, this approach costs computational resources and could lead to infeasibility in solving the QP. In this paper, we propose a novel motion planning framework that combines sampling-based methods with Linear Quadratic Regulator (LQR) and CBFs. Our approach does not require solving the QPs for control synthesis and avoids explicit collision checking during samplings. Instead, it uses LQR to generate optimal controls and CBF to reject unsafe trajectories. To improve sampling efficiency, we employ the Cross-Entropy Method (CEM) for importance sampling (IS) to sample configurations that will enhance the path with higher probability and store computed optimal gain matrices in a hash table to avoid re-computation during rewiring procedure. We demonstrate the effectiveness of our method on nonlinear control affine systems in simulation.
Learning for Control of Rolling ubots
Dec 01, 2022



Micron-scale robots (ubots) have recently shown great promise for emerging medical applications, and accurate control of ubots is a critical next step to deploying them in real systems. In this work, we develop the idea of a nonlinear mismatch controller to compensate for the mismatch between the disturbed unicycle model of a rolling ubot and trajectory data collected during an experiment. We exploit the differential flatness property of the rolling ubot model to generate a mapping from the desired state trajectory to nominal control actions. Due to model mismatch and parameter estimation error, the nominal control actions will not exactly reproduce the desired state trajectory. We employ a Gaussian Process (GP) to learn the model mismatch as a function of the desired control actions, and correct the nominal control actions using a least-squares optimization. We demonstrate the performance of our online learning algorithm in simulation, where we show that the model mismatch makes some desired states unreachable. Finally, we validate our approach in an experiment and show that the error metrics are reduced by up to 40%.
CatlNet: Learning Communication and Coordination Policies from CaTL+ Specifications
Nov 30, 2022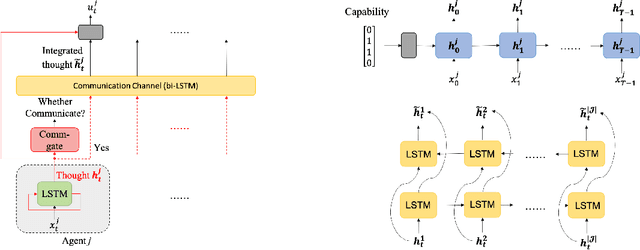
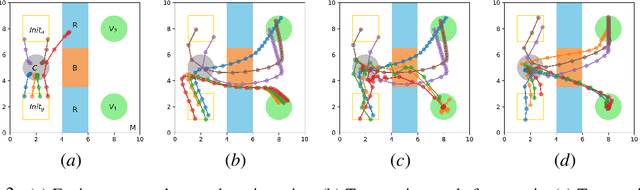
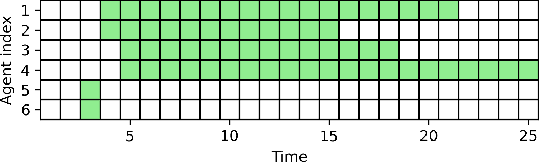
In this paper, we propose a learning-based framework to simultaneously learn the communication and distributed control policies for a heterogeneous multi-agent system (MAS) under complex mission requirements from Capability Temporal Logic plus (CaTL+) specifications. Both policies are trained, implemented, and deployed using a novel neural network model called CatlNet. Taking advantage of the robustness measure of CaTL+, we train CatlNet centrally to maximize it where network parameters are shared among all agents, allowing CatlNet to scale to large teams easily. CatlNet can then be deployed distributedly. A plan repair algorithm is also introduced to guide CatlNet's training and improve both training efficiency and the overall performance of CatlNet. The CatlNet approach is tested in simulation and results show that, after training, CatlNet can steer the decentralized MAS system online to satisfy a CaTL+ specification with a high success rate.
Adaptive Sampling-based Motion Planning with Control Barrier Functions
Jun 01, 2022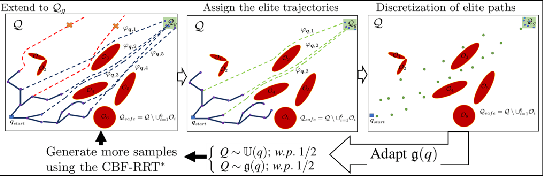
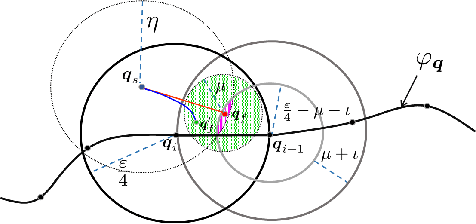
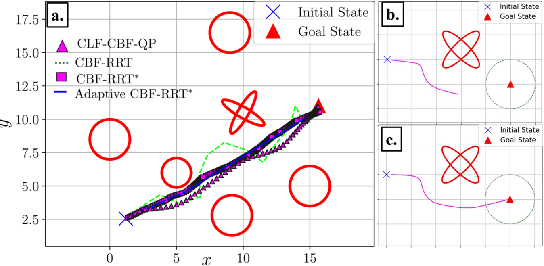
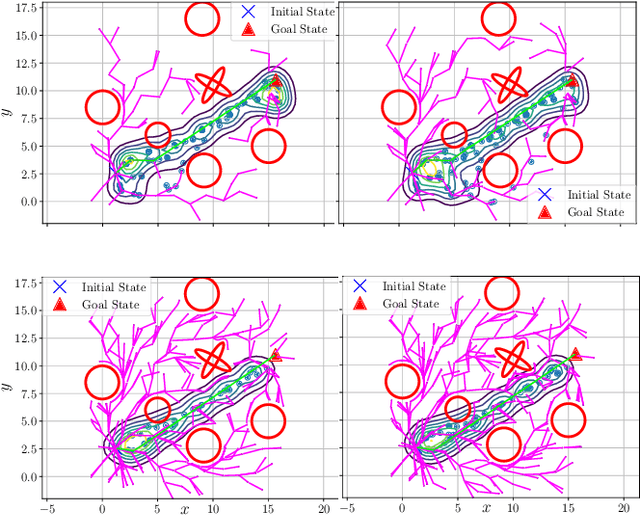
Sampling-based algorithms, such as Rapidly Exploring Random Trees (RRT) and its variants, have been used extensively for motion planning. Control barrier functions (CBFs) have been recently proposed to synthesize controllers for safety-critical systems. In this paper, we combine the effectiveness of RRT-based algorithms with the safety guarantees provided by CBFs in a method called CBF-RRT$^\ast$. CBFs are used for local trajectory planning for RRT$^\ast$, avoiding explicit collision checking of the extended paths. We prove that CBF-RRT$^\ast$ preserves the probabilistic completeness of RRT$^\ast$. Furthermore, in order to improve the sampling efficiency of the algorithm, we equip the algorithm with an adaptive sampling procedure, which is based on the cross-entropy method (CEM) for importance sampling (IS). The procedure exploits the tree of samples to focus the sampling in promising regions of the configuration space. We demonstrate the efficacy of the proposed algorithms through simulation examples.
Distributed Control using Reinforcement Learning with Temporal-Logic-Based Reward Shaping
Apr 06, 2022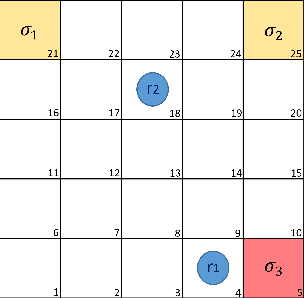


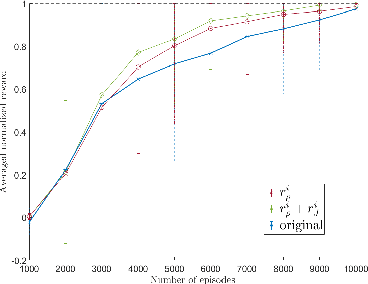
We present a computational framework for synthesis of distributed control strategies for a heterogeneous team of robots in a partially observable environment. The goal is to cooperatively satisfy specifications given as Truncated Linear Temporal Logic (TLTL) formulas. Our approach formulates the synthesis problem as a stochastic game and employs a policy graph method to find a control strategy with memory for each agent. We construct the stochastic game on the product between the team transition system and a finite state automaton (FSA) that tracks the satisfaction of the TLTL formula. We use the quantitative semantics of TLTL as the reward of the game, and further reshape it using the FSA to guide and accelerate the learning process. Simulation results demonstrate the efficacy of the proposed solution under demanding task specifications and the effectiveness of reward shaping in significantly accelerating the speed of learning.