 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Control using Reinforcement Learning with Temporal-Logic-Based Reward Shaping
Paper and Code
Apr 06, 2022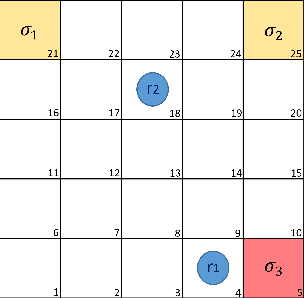


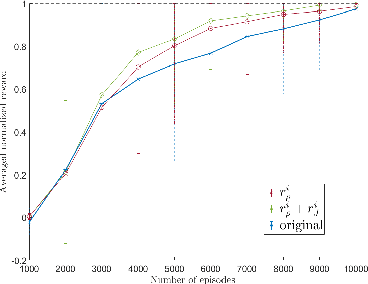
We present a computational framework for synthesis of distributed control strategies for a heterogeneous team of robots in a partially observable environment. The goal is to cooperatively satisfy specifications given as Truncated Linear Temporal Logic (TLTL) formulas. Our approach formulates the synthesis problem as a stochastic game and employs a policy graph method to find a control strategy with memory for each agent. We construct the stochastic game on the product between the team transition system and a finite state automaton (FSA) that tracks the satisfaction of the TLTL formula. We use the quantitative semantics of TLTL as the reward of the game, and further reshape it using the FSA to guide and accelerate the learning process. Simulation results demonstrate the efficacy of the proposed solution under demanding task specifications and the effectiveness of reward shaping in significantly accelerating the speed of learning.