 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-robot Path Planning and Scheduling via Model Predictive Optimal Transport (MPC-OT)
Aug 28, 2025In this paper, we propose a novel methodology for path planning and scheduling for multi-robot navigation that is based on optimal transport theory and model predictive control. We consider a setup where $N$ robots are tasked to navigate to $M$ targets in a common space with obstacles. Mapping robots to targets first and then planning paths can result in overlapping paths that lead to deadlocks. We derive a strategy based on optimal transport that not only provides minimum cost paths from robots to targets but also guarantees non-overlapping trajectories. We achieve this by discretizing the space of interest into $K$ cells and by imposing a ${K\times K}$ cost structure that describes the cost of transitioning from one cell to another. Optimal transport then provides \textit{optimal and non-overlapping} cell transitions for the robots to reach the targets that can be readily deployed without any scheduling considerations. The proposed solution requires $\unicode{x1D4AA}(K^3\log K)$ computations in the worst-case and $\unicode{x1D4AA}(K^2\log K)$ for well-behaved problems. To further accommodate potentially overlapping trajectories (unavoidable in certain situations) as well as robot dynamics, we show that a temporal structure can be integrated into optimal transport with the help of \textit{replans} and \textit{model predictive control}.
Scalable Multi-Robot Task Allocation and Coordination under Signal Temporal Logic Specifications
Mar 04, 2025Motion planning with simple objectives, such as collision-avoidance and goal-reaching, can be solved efficiently using modern planners. However, the complexity of the allowed tasks for these planners is limited. On the other hand, signal temporal logic (STL) can specify complex requirements, but STL-based motion planning and control algorithms often face scalability issues, especially in large multi-robot systems with complex dynamics. In this paper, we propose an algorithm that leverages the best of the two worlds. We first use a single-robot motion planner to efficiently generate a set of alternative reference paths for each robot. Then coordination requirements are specified using STL, which is defined over the assignment of paths and robots' progress along those paths. We use a Mixed Integer Linear Program (MILP) to compute task assignments and robot progress targets over time such that the STL specification is satisfied. Finally, a local controller is used to track the target progress. Simulations demonstrate that our method can handle tasks with complex constraints and scales to large multi-robot teams and intricate task allocation scenarios.
Reliable and Efficient Multi-Agent Coordination via Graph Neural Network Variational Autoencoders
Mar 04, 2025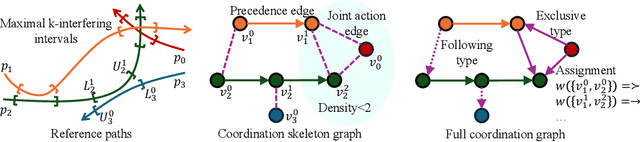
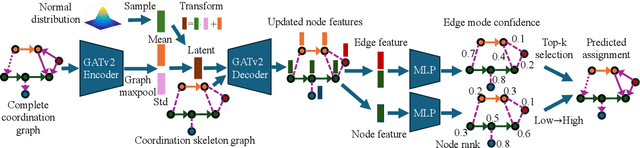
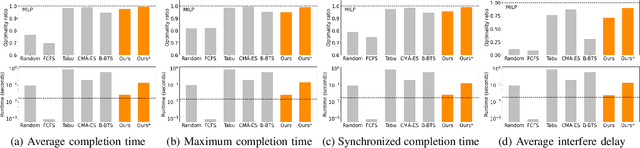
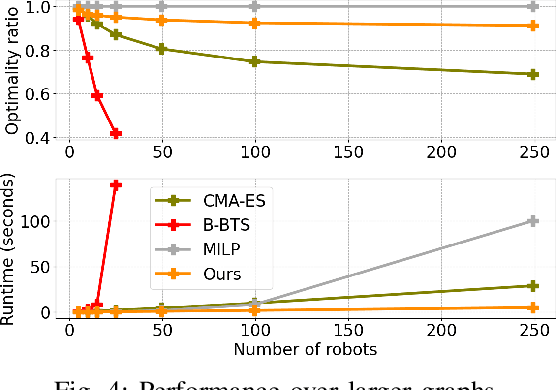
Multi-agent coordination is crucial for reliable multi-robot navigation in shared spaces such as automated warehouses. In regions of dense robot traffic, local coordination methods may fail to find a deadlock-free solution. In these scenarios, it is appropriate to let a central unit generate a global schedule that decides the passing order of robots. However, the runtime of such centralized coordination methods increases significantly with the problem scale. In this paper, we propose to leverage Graph Neural Network Variational Autoencoders (GNN-VAE) to solve the multi-agent coordination problem at scale faster than through centralized optimization. We formulate the coordination problem as a graph problem and collect ground truth data using a Mixed-Integer Linear Program (MILP) solver. During training, our learning framework encodes good quality solutions of the graph problem into a latent space. At inference time, solution samples are decoded from the sampled latent variables, and the lowest-cost sample is selected for coordination. Finally, the feasible proposal with the highest performance index is selected for the deployment. By construction, our GNN-VAE framework returns solutions that always respect the constraints of the considered coordination problem. Numerical results show that our approach trained on small-scale problems can achieve high-quality solutions even for large-scale problems with 250 robots, being much faster than other baselines. Project page: https://mengyuest.github.io/gnn-vae-coord
An Information-Theoretic Framework for Out-of-Distribution Generalization
Mar 29, 2024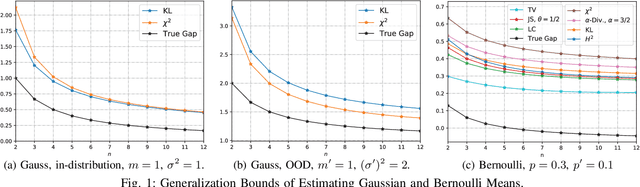
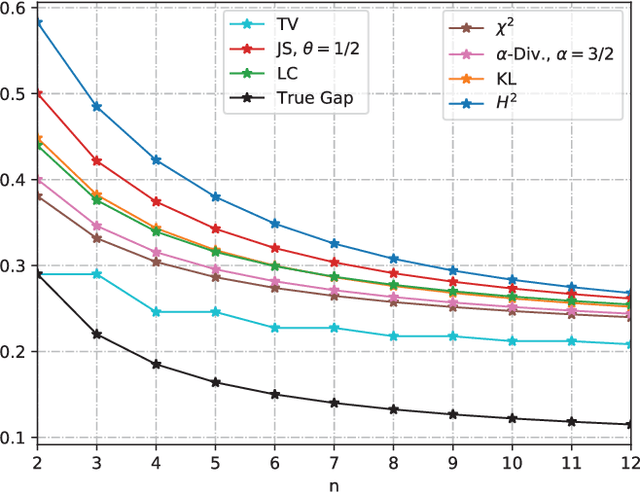
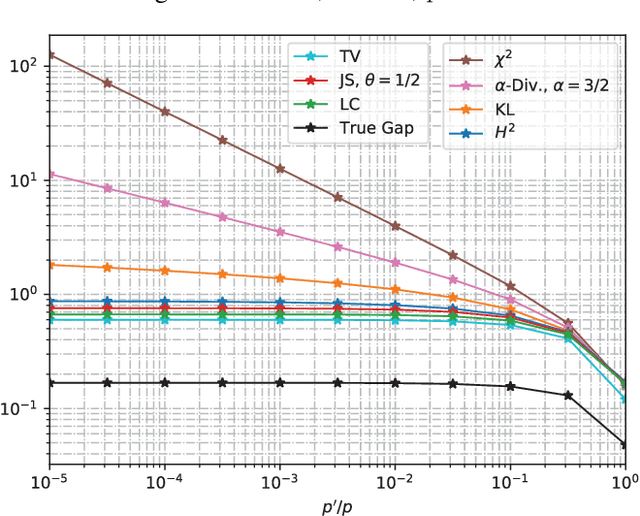

We study the Out-of-Distribution (OOD) generalization in machine learning and propose a general framework that provides information-theoretic generalization bounds. Our framework interpolates freely between Integral Probability Metric (IPM) and $f$-divergence, which naturally recovers some known results (including Wasserstein- and KL-bounds), as well as yields new generalization bounds. Moreover, we show that our framework admits an optimal transport interpretation. When evaluated in two concrete examples, the proposed bounds either strictly improve upon existing bounds in some cases or recover the best among existing OOD generalization bounds.
Interpretable Generative Adversarial Imitation Learning
Feb 15, 2024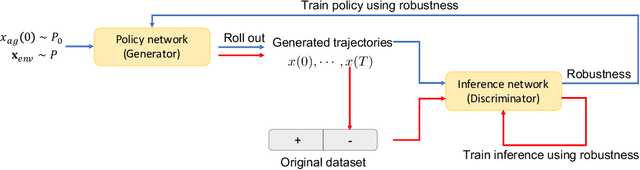
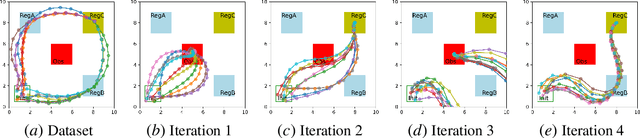
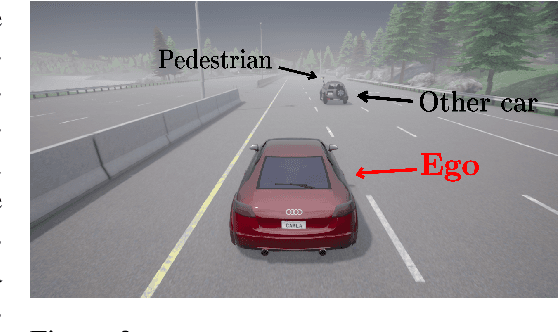
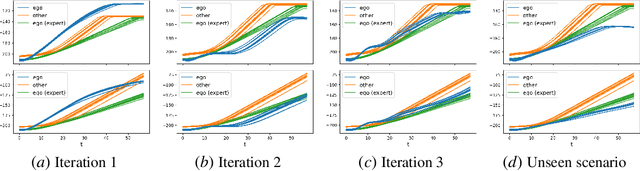
Imitation learning methods have demonstrated considerable success in teaching autonomous systems complex tasks through expert demonstrations. However, a limitation of these methods is their lack of interpretability, particularly in understanding the specific task the learning agent aims to accomplish. In this paper, we propose a novel imitation learning method that combines Signal Temporal Logic (STL) inference and control synthesis, enabling the explicit representation of the task as an STL formula. This approach not only provides a clear understanding of the task but also allows for the incorporation of human knowledge and adaptation to new scenarios through manual adjustments of the STL formulae. Additionally, we employ a Generative Adversarial Network (GAN)-inspired training approach for both the inference and the control policy, effectively narrowing the gap between the expert and learned policies. The effectiveness of our algorithm is demonstrated through two case studies, showcasing its practical applicability and adaptability.
Learning Robust and Correct Controllers from Signal Temporal Logic Specifications Using BarrierNet
Apr 12, 2023


In this paper, we consider the problem of learning a neural network controller for a system required to satisfy a Signal Temporal Logic (STL) specification. We exploit STL quantitative semantics to define a notion of robust satisfaction. Guaranteeing the correctness of a neural network controller, i.e., ensuring the satisfaction of the specification by the controlled system, is a difficult problem that received a lot of attention recently. We provide a general procedure to construct a set of trainable High Order Control Barrier Functions (HOCBFs) enforcing the satisfaction of formulas in a fragment of STL. We use the BarrierNet, implemented by a differentiable Quadratic Program (dQP) with HOCBF constraints, as the last layer of the neural network controller, to guarantee the satisfaction of the STL formulas. We train the HOCBFs together with other neural network parameters to further improve the robustness of the controller. Simulation results demonstrate that our approach ensures satisfaction and outperforms existing algorithms.
CatlNet: Learning Communication and Coordination Policies from CaTL+ Specifications
Nov 30, 2022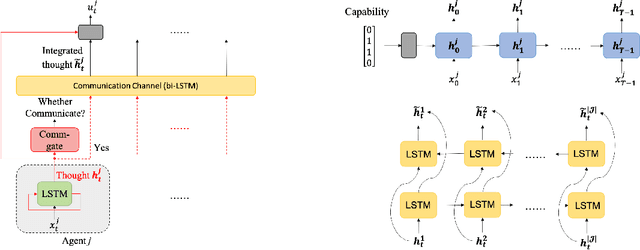
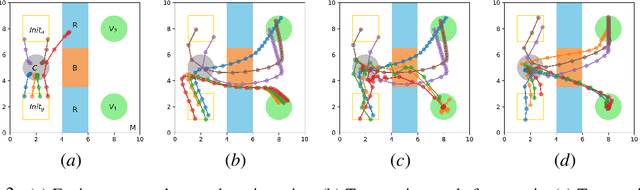
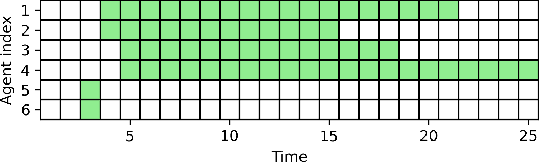
In this paper, we propose a learning-based framework to simultaneously learn the communication and distributed control policies for a heterogeneous multi-agent system (MAS) under complex mission requirements from Capability Temporal Logic plus (CaTL+) specifications. Both policies are trained, implemented, and deployed using a novel neural network model called CatlNet. Taking advantage of the robustness measure of CaTL+, we train CatlNet centrally to maximize it where network parameters are shared among all agents, allowing CatlNet to scale to large teams easily. CatlNet can then be deployed distributedly. A plan repair algorithm is also introduced to guide CatlNet's training and improve both training efficiency and the overall performance of CatlNet. The CatlNet approach is tested in simulation and results show that, after training, CatlNet can steer the decentralized MAS system online to satisfy a CaTL+ specification with a high success rate.
Distributed Control using Reinforcement Learning with Temporal-Logic-Based Reward Shaping
Apr 06, 2022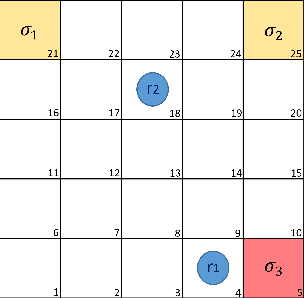


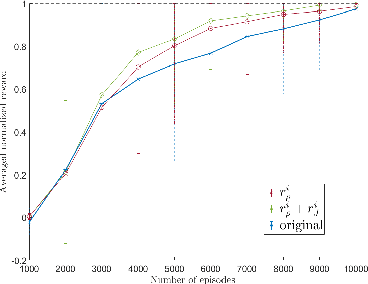
We present a computational framework for synthesis of distributed control strategies for a heterogeneous team of robots in a partially observable environment. The goal is to cooperatively satisfy specifications given as Truncated Linear Temporal Logic (TLTL) formulas. Our approach formulates the synthesis problem as a stochastic game and employs a policy graph method to find a control strategy with memory for each agent. We construct the stochastic game on the product between the team transition system and a finite state automaton (FSA) that tracks the satisfaction of the TLTL formula. We use the quantitative semantics of TLTL as the reward of the game, and further reshape it using the FSA to guide and accelerate the learning process. Simulation results demonstrate the efficacy of the proposed solution under demanding task specifications and the effectiveness of reward shaping in significantly accelerating the speed of learning.
Model-Based Safe Policy Search from Signal Temporal Logic Specifications Using Recurrent Neural Networks
Mar 29, 2021

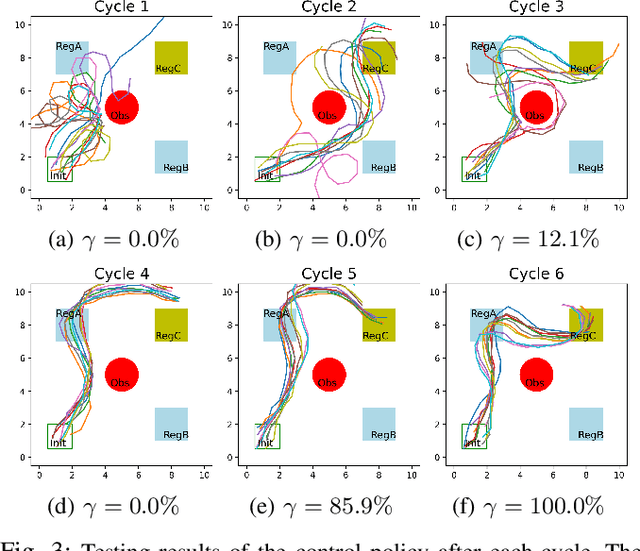

We propose a policy search approach to learn controllers from specifications given as Signal Temporal Logic (STL) formulae. The system model is unknown, and it is learned together with the control policy. The model is implemented as a feedforward neural network (FNN). To capture the history dependency of the STL specification, we use a recurrent neural network (RNN) to implement the control policy. In contrast to prevalent model-free methods, the learning approach proposed here takes advantage of the learned model and is more efficient. We use control barrier functions (CBFs) with the learned model to improve the safety of the system. We validate our algorithm via simulations. The results show that our approach can satisfy the given specification within very few system runs, and therefore it has the potential to be used for on-line control.
Recurrent Neural Network Controllers for Signal Temporal Logic Specifications Subject to Safety Constraints
Sep 24, 2020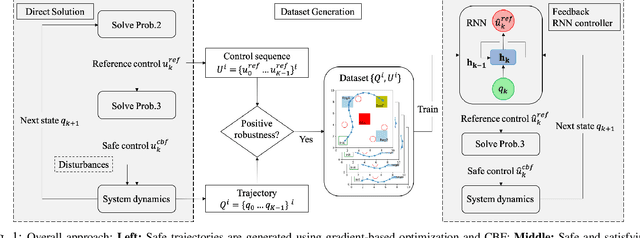
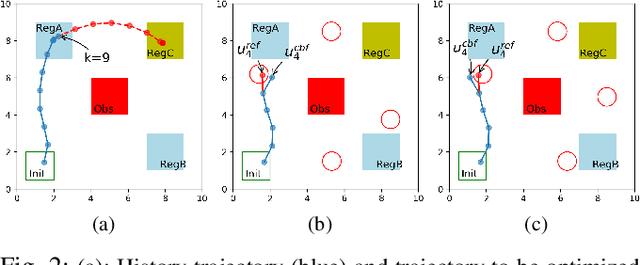
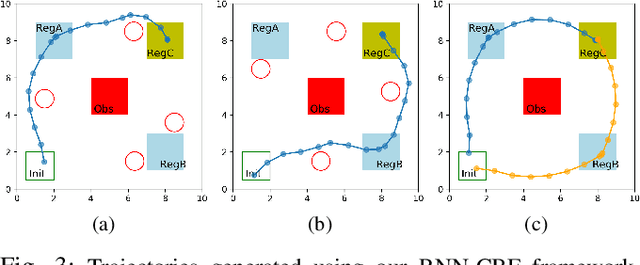
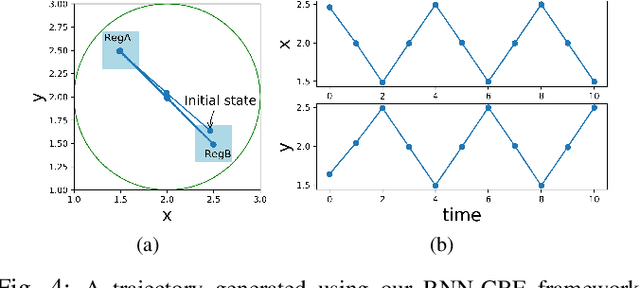
We propose a framework based on Recurrent Neural Networks (RNNs) to determine an optimal control strategy for a discrete-time system that is required to satisfy specifications given as Signal Temporal Logic (STL) formulae. RNNs can store information of a system over time, thus, enable us to determine satisfaction of the dynamic temporal requirements specified in STL formulae. Given a STL formula, a dataset of satisfying system executions and corresponding control policies, we can use RNNs to predict a control policy at each time based on the current and previous states of system. We use Control Barrier Functions (CBFs) to guarantee the safety of the predicted control policy. We validate our theoretical formulation and demonstrate its performance in an optimal control problem subject to partially unknown safety constraints through simulations.