 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Proximal Policy Optimization Learning Using Task Prediction for Solving Games with Delayed Rewards
Nov 26, 2024
In this paper, we tackle the challenging problem of delayed rewards in reinforcement learning (RL). While Proximal Policy Optimization (PPO) has emerged as a leading Policy Gradient method, its performance can degrade under delayed rewards. We introduce two key enhancements to PPO: a hybrid policy architecture that combines an offline policy (trained on expert demonstrations) with an online PPO policy, and a reward shaping mechanism using Time Window Temporal Logic (TWTL). The hybrid architecture leverages offline data throughout training while maintaining PPO's theoretical guarantees. Building on the monotonic improvement framework of Trust Region Policy Optimization (TRPO), we prove that our approach ensures improvement over both the offline policy and previous iterations, with a bounded performance gap of $(2\varsigma\gamma\alpha^2)/(1-\gamma)^2$, where $\alpha$ is the mixing parameter, $\gamma$ is the discount factor, and $\varsigma$ bounds the expected advantage. Additionally, we prove that our TWTL-based reward shaping preserves the optimal policy of the original problem. TWTL enables formal translation of temporal objectives into immediate feedback signals that guide learning. We demonstrate the effectiveness of our approach through extensive experiments on an inverted pendulum and a lunar lander environments, showing improvements in both learning speed and final performance compared to standard PPO and offline-only approaches.
How to Train Your Neural Control Barrier Function: Learning Safety Filters for Complex Input-Constrained Systems
Oct 27, 2023Control barrier functions (CBF) have become popular as a safety filter to guarantee the safety of nonlinear dynamical systems for arbitrary inputs. However, it is difficult to construct functions that satisfy the CBF constraints for high relative degree systems with input constraints. To address these challenges, recent work has explored learning CBFs using neural networks via neural CBF (NCBF). However, such methods face difficulties when scaling to higher dimensional systems under input constraints. In this work, we first identify challenges that NCBFs face during training. Next, to address these challenges, we propose policy neural CBF (PNCBF), a method of constructing CBFs by learning the value function of a nominal policy, and show that the value function of the maximum-over-time cost is a CBF. We demonstrate the effectiveness of our method in simulation on a variety of systems ranging from toy linear systems to an F-16 jet with a 16-dimensional state space. Finally, we validate our approach on a two-agent quadcopter system on hardware under tight input constraints.
A Flexible and Efficient Temporal Logic Tool for Python: PyTeLo
Oct 12, 2023



Temporal logic is an important tool for specifying complex behaviors of systems. It can be used to define properties for verification and monitoring, as well as goals for synthesis tools, allowing users to specify rich missions and tasks. Some of the most popular temporal logics include Metric Temporal Logic (MTL), Signal Temporal Logic (STL), and weighted STL (wSTL), which also allow the definition of timing constraints. In this work, we introduce PyTeLo, a modular and versatile Python-based software that facilitates working with temporal logic languages, specifically MTL, STL, and wSTL. Applying PyTeLo requires only a string representation of the temporal logic specification and, optionally, the dynamics of the system of interest. Next, PyTeLo reads the specification using an ANTLR-generated parser and generates an Abstract Syntax Tree (AST) that captures the structure of the formula. For synthesis, the AST serves to recursively encode the specification into a Mixed Integer Linear Program (MILP) that is solved using a commercial solver such as Gurobi. We describe the architecture and capabilities of PyTeLo and provide example applications highlighting its adaptability and extensibility for various research problems.
Safety-Aware Task Composition for Discrete and Continuous Reinforcement Learning
Jun 29, 2023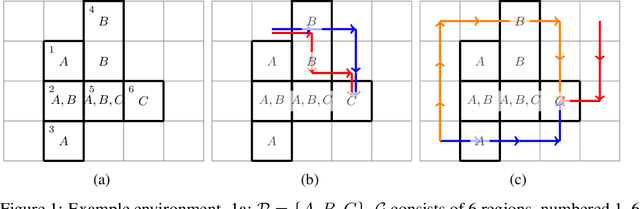

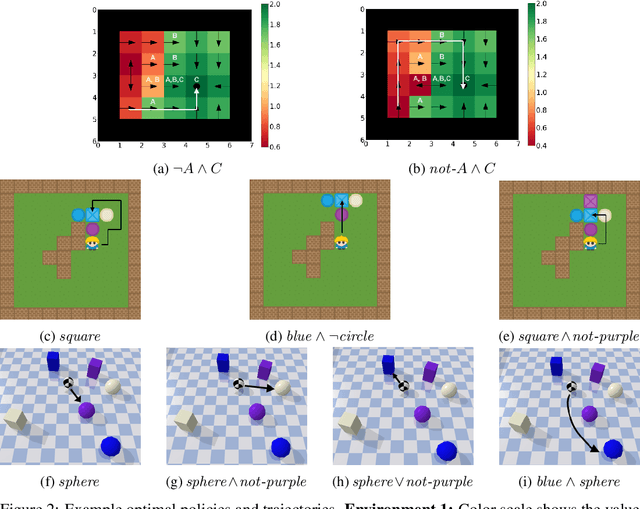
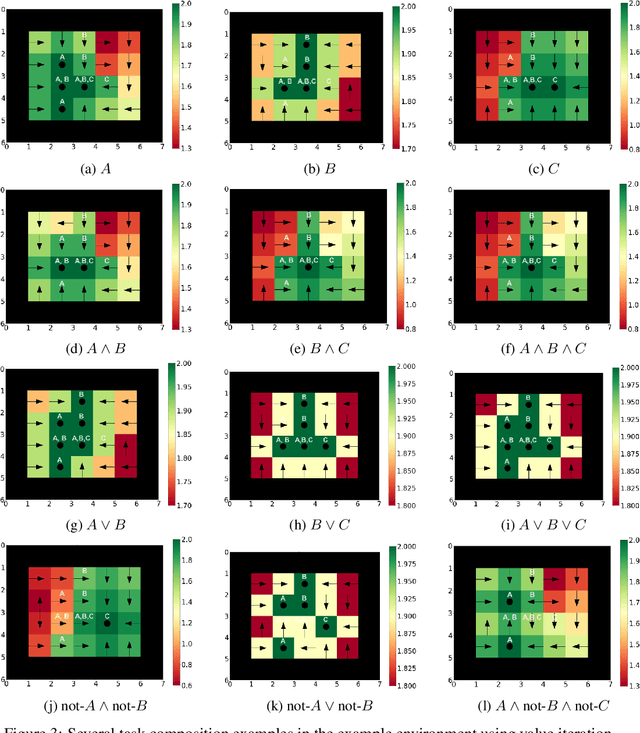
Compositionality is a critical aspect of scalable system design. Reinforcement learning (RL) has recently shown substantial success in task learning, but has only recently begun to truly leverage composition. In this paper, we focus on Boolean composition of learned tasks as opposed to functional or sequential composition. Existing Boolean composition for RL focuses on reaching a satisfying absorbing state in environments with discrete action spaces, but does not support composable safety (i.e., avoidance) constraints. We advance the state of the art in Boolean composition of learned tasks with three contributions: i) introduce two distinct notions of safety in this framework; ii) show how to enforce either safety semantics, prove correctness (under some assumptions), and analyze the trade-offs between the two safety notions; and iii) extend Boolean composition from discrete action spaces to continuous action spaces. We demonstrate these techniques using modified versions of value iteration in a grid world, Deep Q-Network (DQN) in a grid world with image observations, and Twin Delayed DDPG (TD3) in a continuous-observation and continuous-action Bullet physics environment. We believe that these contributions advance the theory of safe reinforcement learning by allowing zero-shot composition of policies satisfying safety properties.
STL: Surprisingly Tricky Logic (for System Validation)
May 26, 2023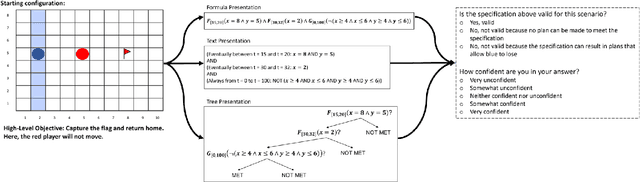
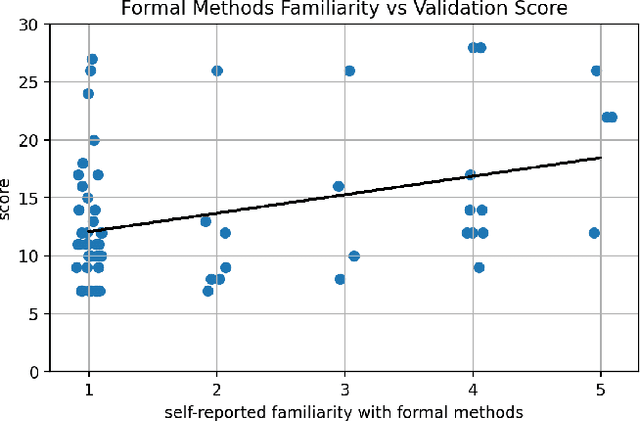
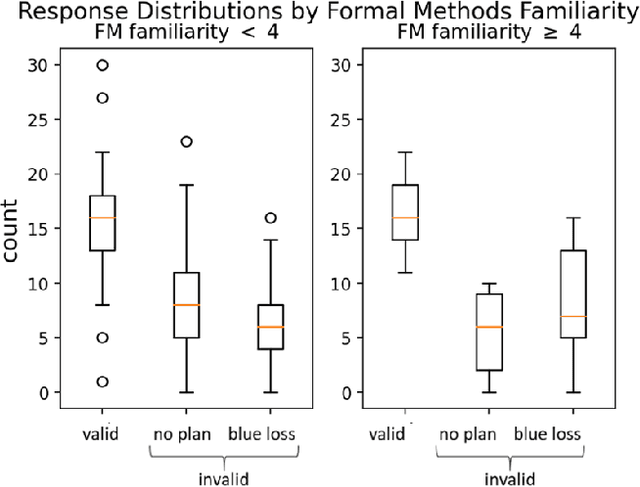
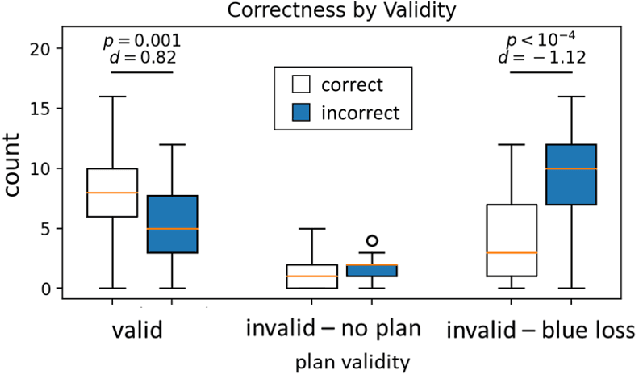
Much of the recent work developing formal methods techniques to specify or learn the behavior of autonomous systems is predicated on a belief that formal specifications are interpretable and useful for humans when checking systems. Though frequently asserted, this assumption is rarely tested. We performed a human experiment (N = 62) with a mix of people who were and were not familiar with formal methods beforehand, asking them to validate whether a set of signal temporal logic (STL) constraints would keep an agent out of harm and allow it to complete a task in a gridworld capture-the-flag setting. Validation accuracy was $45\% \pm 20\%$ (mean $\pm$ standard deviation). The ground-truth validity of a specification, subjects' familiarity with formal methods, and subjects' level of education were found to be significant factors in determining validation correctness. Participants exhibited an affirmation bias, causing significantly increased accuracy on valid specifications, but significantly decreased accuracy on invalid specifications. Additionally, participants, particularly those familiar with formal methods, tended to be overconfident in their answers, and be similarly confident regardless of actual correctness. Our data do not support the belief that formal specifications are inherently human-interpretable to a meaningful degree for system validation. We recommend ergonomic improvements to data presentation and validation training, which should be tested before claims of interpretability make their way back into the formal methods literature.
Lightweight Online Learning for Sets of Related Problems in Automated Reasoning
May 22, 2023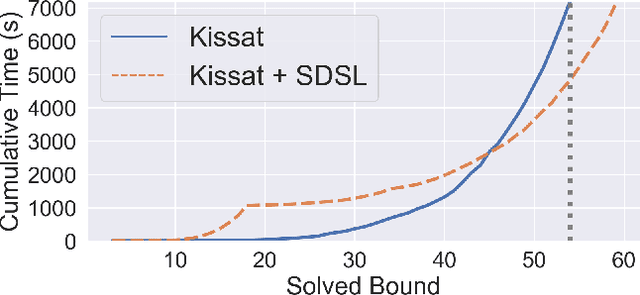
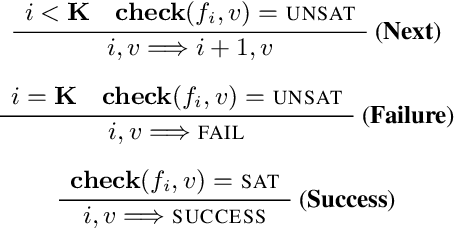
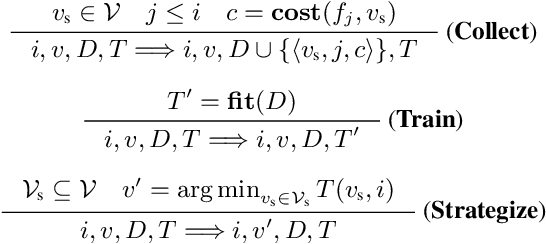
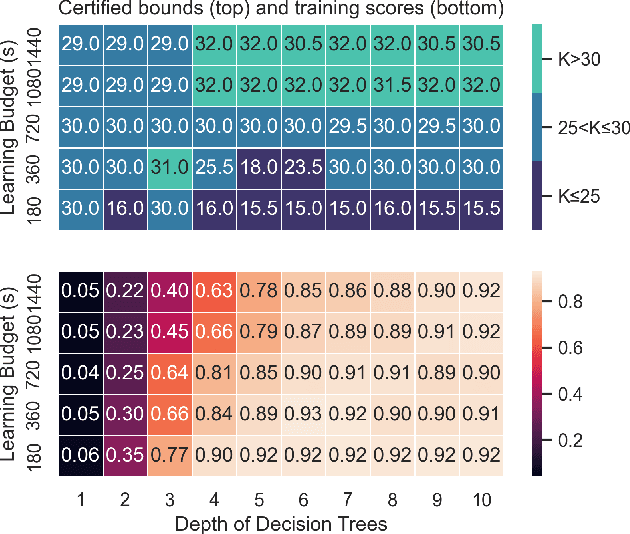
We present Self-Driven Strategy Learning ($\textit{sdsl}$), a lightweight online learning methodology for automated reasoning tasks that involve solving a set of related problems. $\textit{sdsl}$ does not require offline training, but instead automatically constructs a dataset while solving earlier problems. It fits a machine learning model to this data which is then used to adjust the solving strategy for later problems. We formally define the approach as a set of abstract transition rules. We describe a concrete instance of the sdsl calculus which uses conditional sampling for generating data and random forests as the underlying machine learning model. We implement the approach on top of the Kissat solver and show that the combination of Kissat+$\textit{sdsl}$ certifies larger bounds and finds more counter-examples than other state-of-the-art bounded model checking approaches on benchmarks obtained from the latest Hardware Model Checking Competition.
Learning Minimally-Violating Continuous Control for Infeasible Linear Temporal Logic Specifications
Oct 06, 2022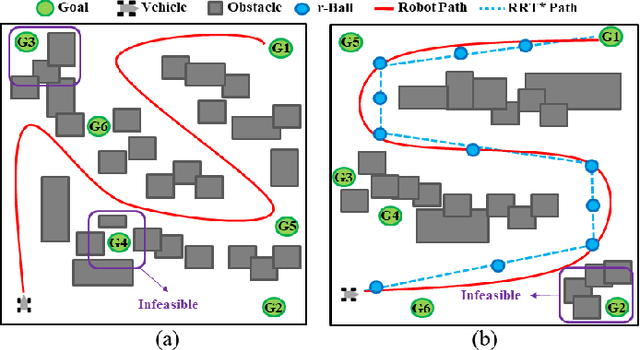
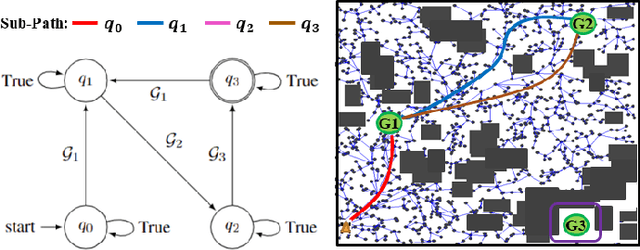
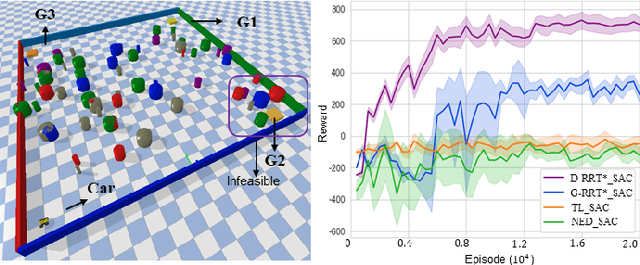
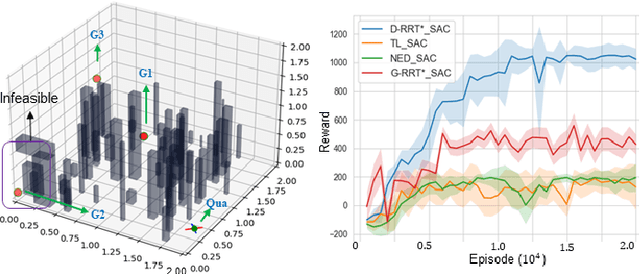
This paper explores continuous-time control synthesis for target-driven navigation to satisfy complex high-level tasks expressed as linear temporal logic (LTL). We propose a model-free framework using deep reinforcement learning (DRL) where the underlying dynamic system is unknown (an opaque box). Unlike prior work, this paper considers scenarios where the given LTL specification might be infeasible and therefore cannot be accomplished globally. Instead of modifying the given LTL formula, we provide a general DRL-based approach to satisfy it with minimal violation. %\mminline{Need to decide if we're comfortable calling these "guarantees" due to the stochastic policy. I'm not repeating this comment everywhere that says "guarantees" but there are multiple places.} To do this, we transform a previously multi-objective DRL problem, which requires simultaneous automata satisfaction and minimum violation cost, into a single objective. By guiding the DRL agent with a sampling-based path planning algorithm for the potentially infeasible LTL task, the proposed approach mitigates the myopic tendencies of DRL, which are often an issue when learning general LTL tasks that can have long or infinite horizons. This is achieved by decomposing an infeasible LTL formula into several reach-avoid sub-tasks with shorter horizons, which can be trained in a modular DRL architecture. Furthermore, we overcome the challenge of the exploration process for DRL in complex and cluttered environments by using path planners to design rewards that are dense in the configuration space. The benefits of the presented approach are demonstrated through testing on various complex nonlinear systems and compared with state-of-the-art baselines. The Video demonstration can be found on YouTube Channel:\url{https://youtu.be/jBhx6Nv224E}.