 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry Preservation in Swarms of Oblivious Robots with Limited Visibility
Sep 28, 2024In the general pattern formation (GPF) problem, a swarm of simple autonomous, disoriented robots must form a given pattern. The robots' simplicity imply a strong limitation: When the initial configuration is rotationally symmetric, only patterns with a similar symmetry can be formed [Yamashita, Suzyuki; TCS 2010]. The only known algorithm to form large patterns with limited visibility and without memory requires the robots to start in a near-gathering (a swarm of constant diameter) [Hahn et al.; SAND 2024]. However, not only do we not know any near-gathering algorithm guaranteed to preserve symmetry but most natural gathering strategies trivially increase symmetries [Castenow et al.; OPODIS 2022]. Thus, we study near-gathering without changing the swarm's rotational symmetry for disoriented, oblivious robots with limited visibility (the OBLOT-model, see [Flocchini et al.; 2019]). We introduce a technique based on the theory of dynamical systems to analyze how a given algorithm affects symmetry and provide sufficient conditions for symmetry preservation. Until now, it was unknown whether the considered OBLOT-model allows for any non-trivial algorithm that always preserves symmetry. Our first result shows that a variant of Go-to-the-Average always preserves symmetry but may sometimes lead to multiple, unconnected near-gathering clusters. Our second result is a symmetry-preserving near-gathering algorithm that works on swarms with a convex boundary (the outer boundary of the unit disc graph) and without holes (circles of diameter 1 inside the boundary without any robots).
Forming Large Patterns with Local Robots in the OBLOT Model
Apr 04, 2024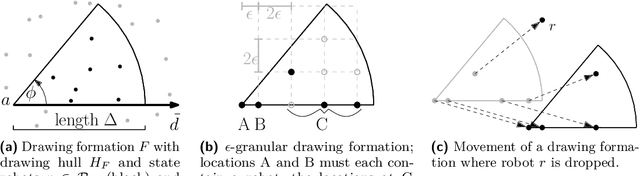
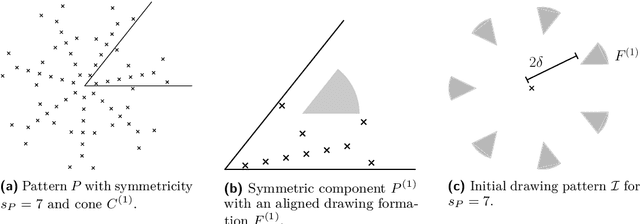
In the arbitrary pattern formation problem, $n$ autonomous, mobile robots must form an arbitrary pattern $P \subseteq \mathbb{R}^2$. The (deterministic) robots are typically assumed to be indistinguishable, disoriented, and unable to communicate. An important distinction is whether robots have memory and/or a limited viewing range. Previous work managed to form $P$ under a natural symmetry condition if robots have no memory but an unlimited viewing range [22] or if robots have a limited viewing range but memory [25]. In the latter case, $P$ is only formed in a shrunk version that has constant diameter. Without memory and with limited viewing range, forming arbitrary patterns remains an open problem. We provide a partial solution by showing that $P$ can be formed under the same symmetry condition if the robots' initial diameter is $\leq 1$. Our protocol partitions $P$ into rotation-symmetric components and exploits the initial mutual visibility to form one cluster per component. Using a careful placement of the clusters and their robots, we show that a cluster can move in a coordinated way through its component while drawing $P$ by dropping one robot per pattern coordinate.
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
Apr 02, 2024Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16\% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
NeuroSynt: A Neuro-symbolic Portfolio Solver for Reactive Synthesis
Jan 29, 2024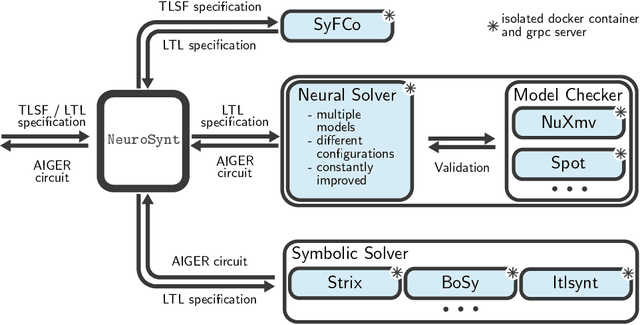

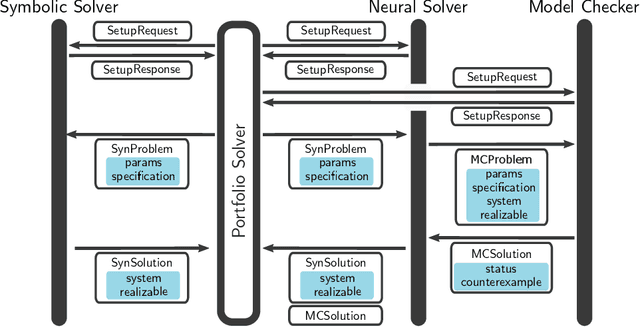
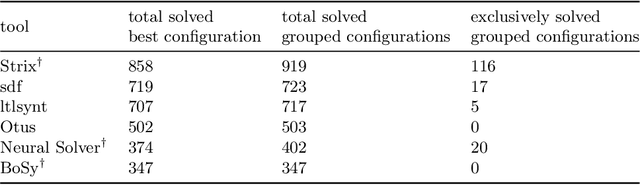
We introduce NeuroSynt, a neuro-symbolic portfolio solver framework for reactive synthesis. At the core of the solver lies a seamless integration of neural and symbolic approaches to solving the reactive synthesis problem. To ensure soundness, the neural engine is coupled with model checkers verifying the predictions of the underlying neural models. The open-source implementation of NeuroSynt provides an integration framework for reactive synthesis in which new neural and state-of-the-art symbolic approaches can be seamlessly integrated. Extensive experiments demonstrate its efficacy in handling challenging specifications, enhancing the state-of-the-art reactive synthesis solvers, with NeuroSynt contributing novel solves in the current SYNTCOMP benchmarks.
Lightweight Online Learning for Sets of Related Problems in Automated Reasoning
May 22, 2023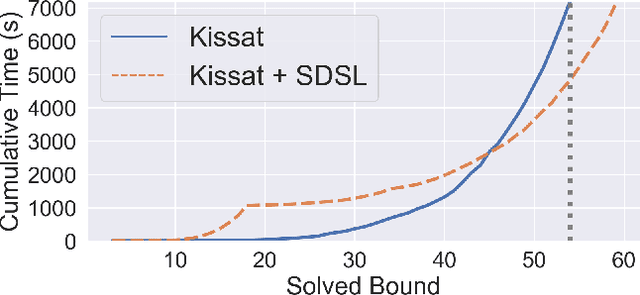
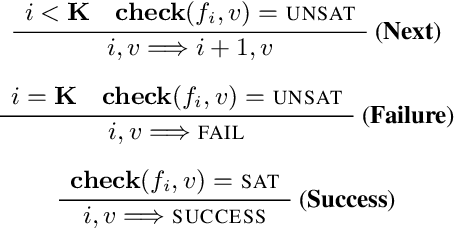
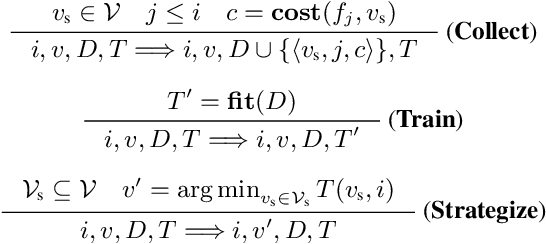
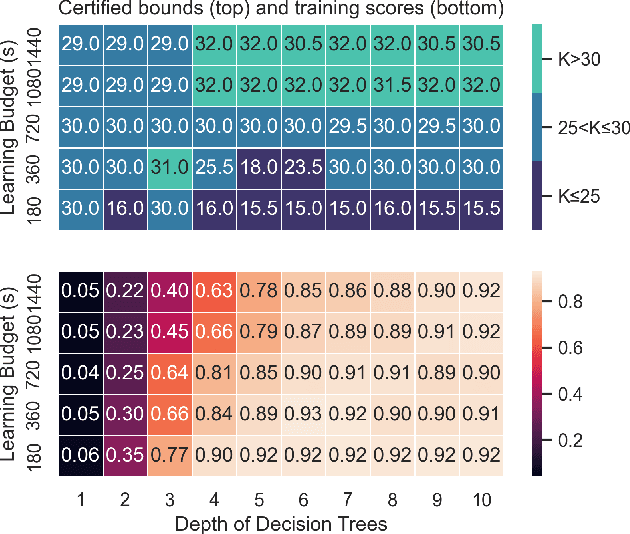
We present Self-Driven Strategy Learning ($\textit{sdsl}$), a lightweight online learning methodology for automated reasoning tasks that involve solving a set of related problems. $\textit{sdsl}$ does not require offline training, but instead automatically constructs a dataset while solving earlier problems. It fits a machine learning model to this data which is then used to adjust the solving strategy for later problems. We formally define the approach as a set of abstract transition rules. We describe a concrete instance of the sdsl calculus which uses conditional sampling for generating data and random forests as the underlying machine learning model. We implement the approach on top of the Kissat solver and show that the combination of Kissat+$\textit{sdsl}$ certifies larger bounds and finds more counter-examples than other state-of-the-art bounded model checking approaches on benchmarks obtained from the latest Hardware Model Checking Competition.
nl2spec: Interactively Translating Unstructured Natural Language to Temporal Logics with Large Language Models
Mar 08, 2023



A rigorous formalization of desired system requirements is indispensable when performing any verification task. This often limits the application of verification techniques, as writing formal specifications is an error-prone and time-consuming manual task. To facilitate this, we present nl2spec, a framework for applying Large Language Models (LLMs) to derive formal specifications (in temporal logics) from unstructured natural language. In particular, we introduce a new methodology to detect and resolve the inherent ambiguity of system requirements in natural language: we utilize LLMs to map subformulas of the formalization back to the corresponding natural language fragments of the input. Users iteratively add, delete, and edit these sub-translations to amend erroneous formalizations, which is easier than manually redrafting the entire formalization. The framework is agnostic to specific application domains and can be extended to similar specification languages and new neural models. We perform a user study to obtain a challenging dataset, which we use to run experiments on the quality of translations. We provide an open-source implementation, including a web-based frontend.
Iterative Circuit Repair Against Formal Specifications
Mar 02, 2023



We present a deep learning approach for repairing sequential circuits against formal specifications given in linear-time temporal logic (LTL). Given a defective circuit and its formal specification, we train Transformer models to output circuits that satisfy the corresponding specification. We propose a separated hierarchical Transformer for multimodal representation learning of the formal specification and the circuit. We introduce a data generation algorithm that enables generalization to more complex specifications and out-of-distribution datasets. In addition, our proposed repair mechanism significantly improves the automated synthesis of circuits from LTL specifications with Transformers. It improves the state-of-the-art by $6.8$ percentage points on held-out instances and $11.8$ percentage points on an out-of-distribution dataset from the annual reactive synthesis competition.
Formal Specifications from Natural Language
Jun 04, 2022


We study the ability of language models to translate natural language into formal specifications with complex semantics. In particular, we fine-tune off-the-shelf language models on three datasets consisting of structured English sentences and their corresponding formal representation: 1) First-order logic (FOL), commonly used in software verification and theorem proving; 2) linear-time temporal logic (LTL), which forms the basis for industrial hardware specification languages; and 3) regular expressions (regex), frequently used in programming and search. Our experiments show that, in these diverse domains, the language models achieve competitive performance to the respective state-of-the-art with the benefits of being easy to access, cheap to fine-tune, and without a particular need for domain-specific reasoning. Additionally, we show that the language models have a unique selling point: they benefit from their generalization capabilities from pre-trained knowledge on natural language, e.g., to generalize to unseen variable names.
Attention Flows for General Transformers
May 30, 2022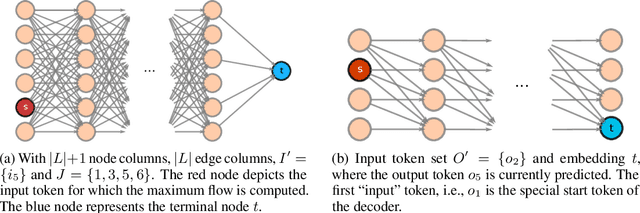

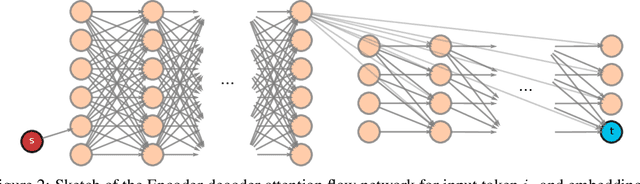
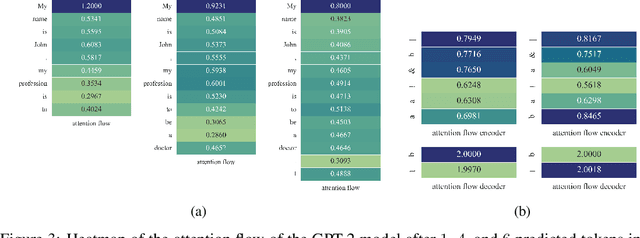
In this paper, we study the computation of how much an input token in a Transformer model influences its prediction. We formalize a method to construct a flow network out of the attention values of encoder-only Transformer models and extend it to general Transformer architectures including an auto-regressive decoder. We show that running a maxflow algorithm on the flow network construction yields Shapley values, which determine the impact of a player in cooperative game theory. By interpreting the input tokens in the flow network as players, we can compute their influence on the total attention flow leading to the decoder's decision. Additionally, we provide a library that computes and visualizes the attention flow of arbitrary Transformer models. We show the usefulness of our implementation on various models trained on natural language processing and reasoning tasks.
Generating Symbolic Reasoning Problems with Transformer GANs
Oct 19, 2021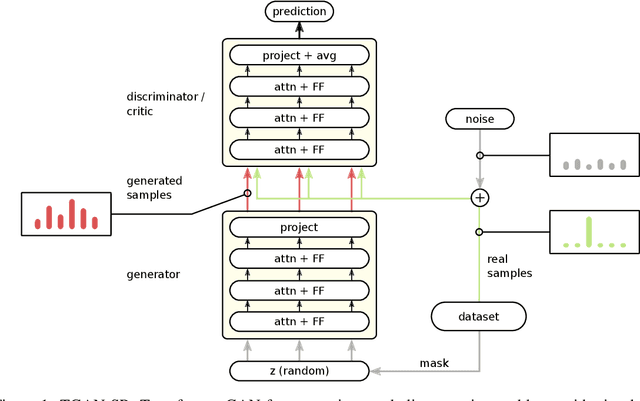
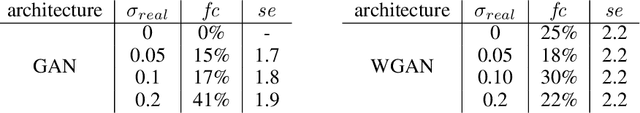
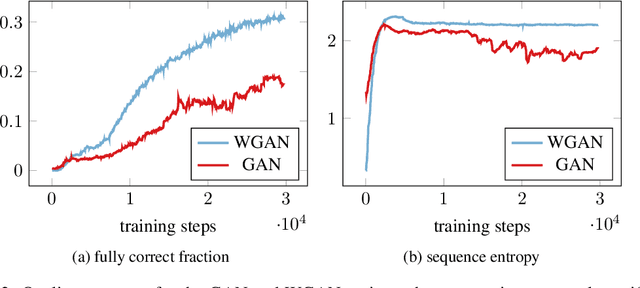

Constructing training data for symbolic reasoning domains is challenging: Existing instances are typically hand-crafted and too few to be trained on directly and synthetically generated instances are often hard to evaluate in terms of their meaningfulness. We study the capabilities of GANs and Wasserstein GANs equipped with Transformer encoders to generate sensible and challenging training data for symbolic reasoning domains. We conduct experiments on two problem domains where Transformers have been successfully applied recently: symbolic mathematics and temporal specifications in verification. Even without autoregression, our GAN models produce syntactically correct instances. We show that the generated data can be used as a substitute for real training data when training a classifier, and, especially, that training data can be generated from a real dataset that is too small to be trained on directly. Using a GAN setting also allows us to alter the target distribution: We show that by adding a classifier uncertainty part to the generator objective, we obtain a dataset that is even harder to solve for a classifier than our original dataset.