 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuRes: Learning Proofs of Propositional Satisfiability
Feb 13, 2024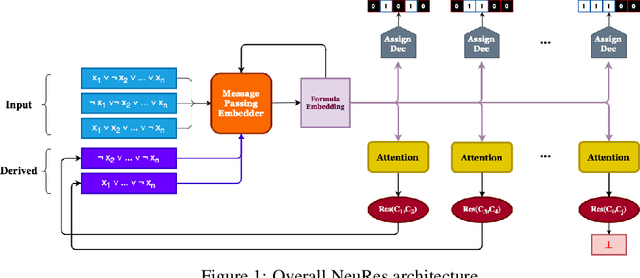
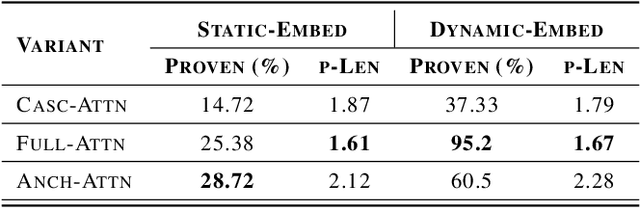
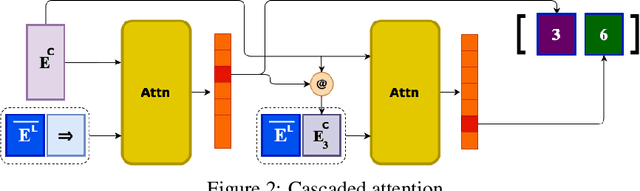
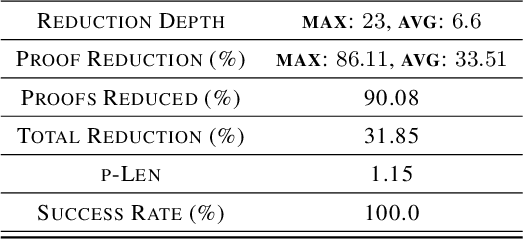
We introduce NeuRes, a neuro-symbolic proof-based SAT solver. Unlike other neural SAT solving methods, NeuRes is capable of proving unsatisfiability as opposed to merely predicting it. By design, NeuRes operates in a certificate-driven fashion by employing propositional resolution to prove unsatisfiability and to accelerate the process of finding satisfying truth assignments in case of unsat and sat formulas, respectively. To realize this, we propose a novel architecture that adapts elements from Graph Neural Networks and Pointer Networks to autoregressively select pairs of nodes from a dynamic graph structure, which is essential to the generation of resolution proofs. Our model is trained and evaluated on a dataset of teacher proofs and truth assignments that we compiled with the same random formula distribution used by NeuroSAT. In our experiments, we show that NeuRes solves more test formulas than NeuroSAT by a rather wide margin on different distributions while being much more data-efficient. Furthermore, we show that NeuRes is capable of largely shortening teacher proofs by notable proportions. We use this feature to devise a bootstrapped training procedure that manages to reduce a dataset of proofs generated by an advanced solver by ~23% after training on it with no extra guidance.
NeuroSynt: A Neuro-symbolic Portfolio Solver for Reactive Synthesis
Jan 29, 2024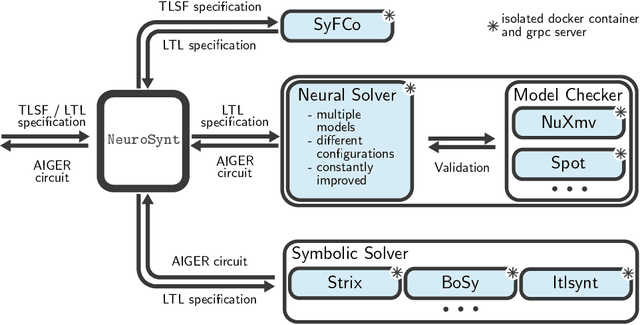

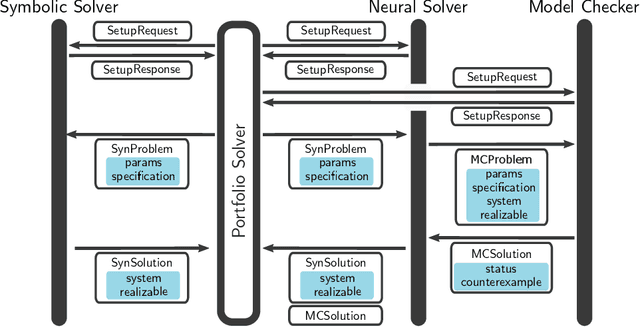
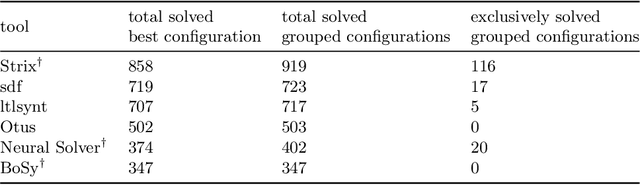
We introduce NeuroSynt, a neuro-symbolic portfolio solver framework for reactive synthesis. At the core of the solver lies a seamless integration of neural and symbolic approaches to solving the reactive synthesis problem. To ensure soundness, the neural engine is coupled with model checkers verifying the predictions of the underlying neural models. The open-source implementation of NeuroSynt provides an integration framework for reactive synthesis in which new neural and state-of-the-art symbolic approaches can be seamlessly integrated. Extensive experiments demonstrate its efficacy in handling challenging specifications, enhancing the state-of-the-art reactive synthesis solvers, with NeuroSynt contributing novel solves in the current SYNTCOMP benchmarks.
nl2spec: Interactively Translating Unstructured Natural Language to Temporal Logics with Large Language Models
Mar 08, 2023



A rigorous formalization of desired system requirements is indispensable when performing any verification task. This often limits the application of verification techniques, as writing formal specifications is an error-prone and time-consuming manual task. To facilitate this, we present nl2spec, a framework for applying Large Language Models (LLMs) to derive formal specifications (in temporal logics) from unstructured natural language. In particular, we introduce a new methodology to detect and resolve the inherent ambiguity of system requirements in natural language: we utilize LLMs to map subformulas of the formalization back to the corresponding natural language fragments of the input. Users iteratively add, delete, and edit these sub-translations to amend erroneous formalizations, which is easier than manually redrafting the entire formalization. The framework is agnostic to specific application domains and can be extended to similar specification languages and new neural models. We perform a user study to obtain a challenging dataset, which we use to run experiments on the quality of translations. We provide an open-source implementation, including a web-based frontend.
Iterative Circuit Repair Against Formal Specifications
Mar 02, 2023



We present a deep learning approach for repairing sequential circuits against formal specifications given in linear-time temporal logic (LTL). Given a defective circuit and its formal specification, we train Transformer models to output circuits that satisfy the corresponding specification. We propose a separated hierarchical Transformer for multimodal representation learning of the formal specification and the circuit. We introduce a data generation algorithm that enables generalization to more complex specifications and out-of-distribution datasets. In addition, our proposed repair mechanism significantly improves the automated synthesis of circuits from LTL specifications with Transformers. It improves the state-of-the-art by $6.8$ percentage points on held-out instances and $11.8$ percentage points on an out-of-distribution dataset from the annual reactive synthesis competition.
Formal Specifications from Natural Language
Jun 04, 2022


We study the ability of language models to translate natural language into formal specifications with complex semantics. In particular, we fine-tune off-the-shelf language models on three datasets consisting of structured English sentences and their corresponding formal representation: 1) First-order logic (FOL), commonly used in software verification and theorem proving; 2) linear-time temporal logic (LTL), which forms the basis for industrial hardware specification languages; and 3) regular expressions (regex), frequently used in programming and search. Our experiments show that, in these diverse domains, the language models achieve competitive performance to the respective state-of-the-art with the benefits of being easy to access, cheap to fine-tune, and without a particular need for domain-specific reasoning. Additionally, we show that the language models have a unique selling point: they benefit from their generalization capabilities from pre-trained knowledge on natural language, e.g., to generalize to unseen variable names.
Attention Flows for General Transformers
May 30, 2022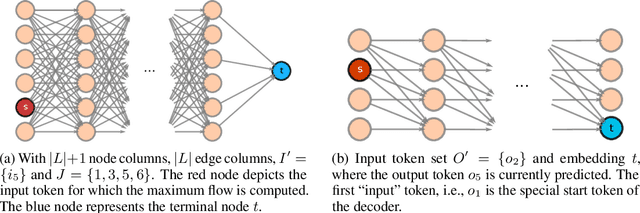

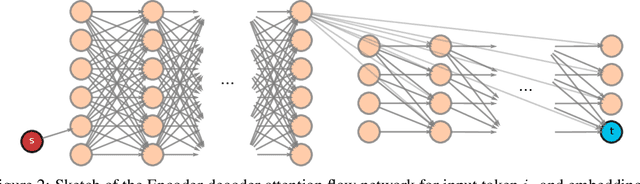
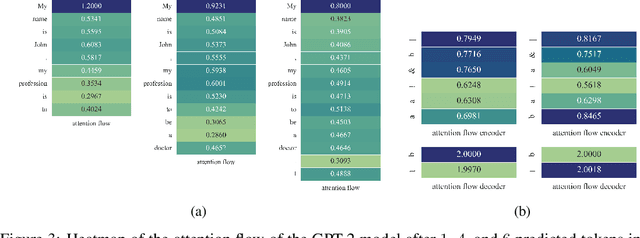
In this paper, we study the computation of how much an input token in a Transformer model influences its prediction. We formalize a method to construct a flow network out of the attention values of encoder-only Transformer models and extend it to general Transformer architectures including an auto-regressive decoder. We show that running a maxflow algorithm on the flow network construction yields Shapley values, which determine the impact of a player in cooperative game theory. By interpreting the input tokens in the flow network as players, we can compute their influence on the total attention flow leading to the decoder's decision. Additionally, we provide a library that computes and visualizes the attention flow of arbitrary Transformer models. We show the usefulness of our implementation on various models trained on natural language processing and reasoning tasks.
Neural Circuit Synthesis from Specification Patterns
Jul 25, 2021


We train hierarchical Transformers on the task of synthesizing hardware circuits directly out of high-level logical specifications in linear-time temporal logic (LTL). The LTL synthesis problem is a well-known algorithmic challenge with a long history and an annual competition is organized to track the improvement of algorithms and tooling over time. New approaches using machine learning might open a lot of possibilities in this area, but suffer from the lack of sufficient amounts of training data. In this paper, we consider a method to generate large amounts of additional training data, i.e., pairs of specifications and circuits implementing them. We ensure that this synthetic data is sufficiently close to human-written specifications by mining common patterns from the specifications used in the synthesis competitions. We show that hierarchical Transformers trained on this synthetic data solve a significant portion of problems from the synthesis competitions, and even out-of-distribution examples from a recent case study.
Teaching Temporal Logics to Neural Networks
Mar 06, 2020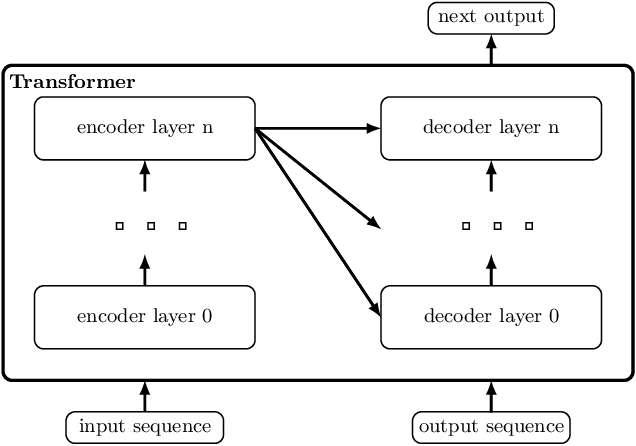
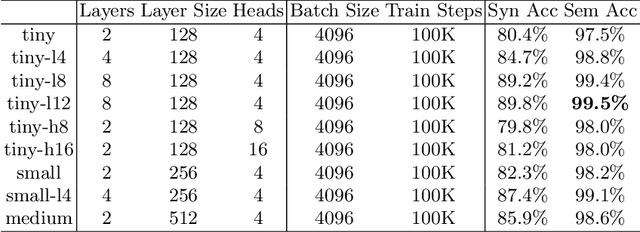
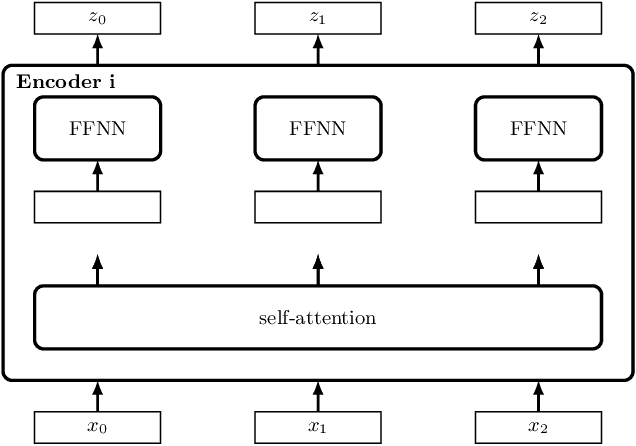
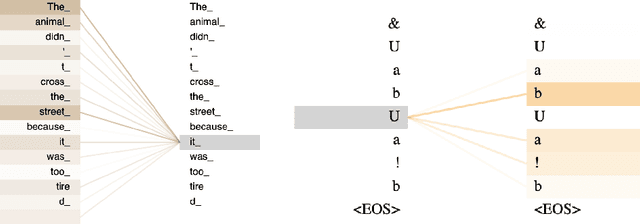
We show that a deep neural network can learn the semantics of linear-time temporal logic (LTL). As a challenging task that requires deep understanding of the LTL semantics, we show that our network can solve the trace generation problem for LTL: given a satisfiable LTL formula, find a trace that satisfies the formula. We frame the trace generation problem for LTL as a translation task, i.e., to translate from formulas to satisfying traces, and train an off-the-shelf implementation of the Transformer, a recently introduced deep learning architecture proposed for solving natural language processing tasks. We provide a detailed analysis of our experimental results, comparing multiple hyperparameter settings and formula representations. After training for several hours on a single GPU the results were surprising: the Transformer returns the syntactically equivalent trace in 89% of the cases on a held-out test set. Most of the "mispredictions", however, (and overall more than 99% of the predicted traces) still satisfy the given LTL formula. In other words, the Transformer generalized from imperfect training data to the semantics of LTL.