 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation
Apr 22, 2025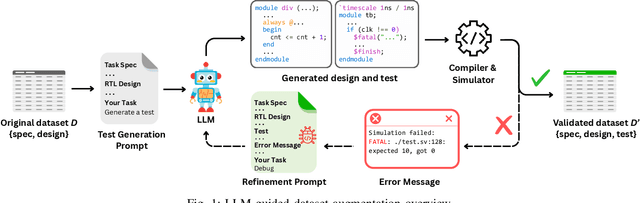

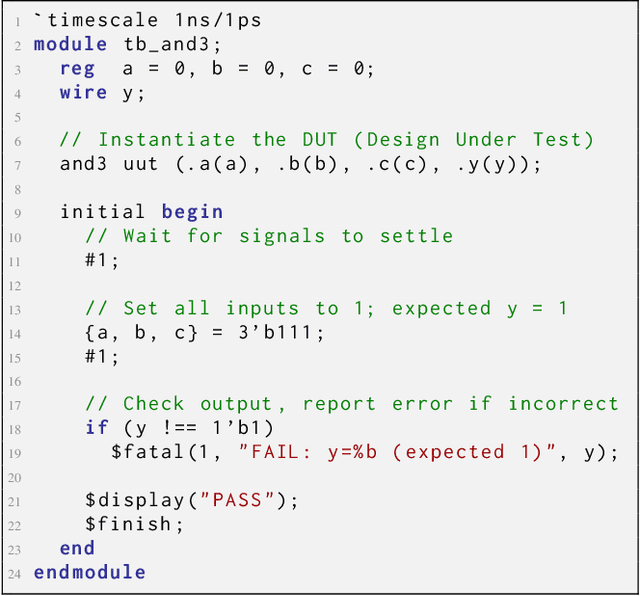
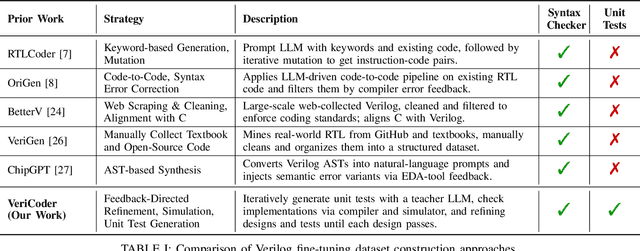
Recent advances in Large Language Models (LLMs) have sparked growing interest in applying them to Electronic Design Automation (EDA) tasks, particularly Register Transfer Level (RTL) code generation. While several RTL datasets have been introduced, most focus on syntactic validity rather than functional validation with tests, leading to training examples that compile but may not implement the intended behavior. We present VERICODER, a model for RTL code generation fine-tuned on a dataset validated for functional correctness. This fine-tuning dataset is constructed using a novel methodology that combines unit test generation with feedback-directed refinement. Given a natural language specification and an initial RTL design, we prompt a teacher model (GPT-4o-mini) to generate unit tests and iteratively revise the RTL design based on its simulation results using the generated tests. If necessary, the teacher model also updates the tests to ensure they comply with the natural language specification. As a result of this process, every example in our dataset is functionally validated, consisting of a natural language description, an RTL implementation, and passing tests. Fine-tuned on this dataset of over 125,000 examples, VERICODER achieves state-of-the-art metrics in functional correctness on VerilogEval and RTLLM, with relative gains of up to 71.7% and 27.4% respectively. An ablation study further shows that models trained on our functionally validated dataset outperform those trained on functionally non-validated datasets, underscoring the importance of high-quality datasets in RTL code generation.
MGit: A Model Versioning and Management System
Jul 14, 2023Models derived from other models are extremely common in machine learning (ML) today. For example, transfer learning is used to create task-specific models from "pre-trained" models through finetuning. This has led to an ecosystem where models are related to each other, sharing structure and often even parameter values. However, it is hard to manage these model derivatives: the storage overhead of storing all derived models quickly becomes onerous, prompting users to get rid of intermediate models that might be useful for further analysis. Additionally, undesired behaviors in models are hard to track down (e.g., is a bug inherited from an upstream model?). In this paper, we propose a model versioning and management system called MGit that makes it easier to store, test, update, and collaborate on model derivatives. MGit introduces a lineage graph that records provenance and versioning information between models, optimizations to efficiently store model parameters, as well as abstractions over this lineage graph that facilitate relevant testing, updating and collaboration functionality. MGit is able to reduce the lineage graph's storage footprint by up to 7x and automatically update downstream models in response to updates to upstream models.
nl2spec: Interactively Translating Unstructured Natural Language to Temporal Logics with Large Language Models
Mar 08, 2023



A rigorous formalization of desired system requirements is indispensable when performing any verification task. This often limits the application of verification techniques, as writing formal specifications is an error-prone and time-consuming manual task. To facilitate this, we present nl2spec, a framework for applying Large Language Models (LLMs) to derive formal specifications (in temporal logics) from unstructured natural language. In particular, we introduce a new methodology to detect and resolve the inherent ambiguity of system requirements in natural language: we utilize LLMs to map subformulas of the formalization back to the corresponding natural language fragments of the input. Users iteratively add, delete, and edit these sub-translations to amend erroneous formalizations, which is easier than manually redrafting the entire formalization. The framework is agnostic to specific application domains and can be extended to similar specification languages and new neural models. We perform a user study to obtain a challenging dataset, which we use to run experiments on the quality of translations. We provide an open-source implementation, including a web-based frontend.
Dynamic Network Adaptation at Inference
Apr 18, 2022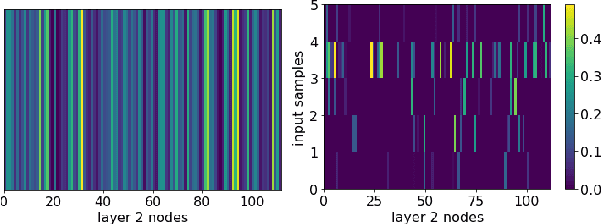
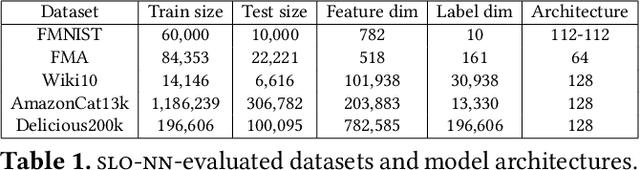
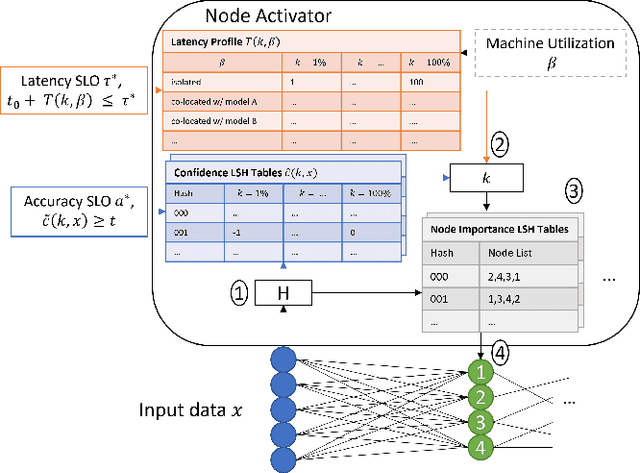

Machine learning (ML) inference is a real-time workload that must comply with strict Service Level Objectives (SLOs), including latency and accuracy targets. Unfortunately, ensuring that SLOs are not violated in inference-serving systems is challenging due to inherent model accuracy-latency tradeoffs, SLO diversity across and within application domains, evolution of SLOs over time, unpredictable query patterns, and co-location interference. In this paper, we observe that neural networks exhibit high degrees of per-input activation sparsity during inference. . Thus, we propose SLO-Aware Neural Networks which dynamically drop out nodes per-inference query, thereby tuning the amount of computation performed, according to specified SLO optimization targets and machine utilization. SLO-Aware Neural Networks achieve average speedups of $1.3-56.7\times$ with little to no accuracy loss (less than 0.3%). When accuracy constrained, SLO-Aware Neural Networks are able to serve a range of accuracy targets at low latency with the same trained model. When latency constrained, SLO-Aware Neural Networks can proactively alleviate latency degradation from co-location interference while maintaining high accuracy to meet latency constraints.