 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkip-Connected Policy Optimization for Implicit Advantage
Apr 09, 2026Group Relative Policy Optimization (GRPO) has proven effective in RLVR by using outcome-based rewards. While fine-grained dense rewards can theoretically improve performance, we reveal that under practical sampling budgets, Monte Carlo estimation yields high-variance and sign-inconsistent advantages for early reasoning tokens, paradoxically underperforming outcome-only GRPO. We propose Skip-Connected Optimization (SKPO), which decomposes reasoning into upstream and downstream phases: upstream receives dense rewards from downstream Monte Carlo sampling with single-stream optimization; downstream maintains group-relative optimization, where a skip connection concatenates the upstream segment with the original problem, enabling the model to leverage helpful upstream reasoning while preserving the freedom to bypass flawed reasoning through direct problem access. Experiments demonstrate improvements of 3.91% and 6.17% relative gains over the strongest baselines on Qwen2.5-Math-7B and Llama-3.2-3B respectively across mathematical benchmarks and out-of-domain tasks including general reasoning and code generation. Further analysis reveals an implicit advantage: SKPO generates trajectories with higher intermediate-step quality even when matched for final correctness.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
Atom of Thoughts for Markov LLM Test-Time Scaling
Feb 17, 2025Large Language Models (LLMs) achieve superior performance through training-time scaling, and test-time scaling further enhances their capabilities by conducting effective reasoning during inference. However, as the scale of reasoning increases, existing test-time scaling methods suffer from accumulated historical information, which not only wastes computational resources but also interferes with effective reasoning. To address this issue, we observe that complex reasoning progress is often achieved by solving a sequence of independent subquestions, each being self-contained and verifiable. These subquestions are essentially atomic questions, relying primarily on their current state rather than accumulated history, similar to the memoryless transitions in a Markov process. Based on this observation, we propose Atom of Thoughts (AoT), where each state transition in the reasoning process consists of decomposing the current question into a dependency-based directed acyclic graph and contracting its subquestions, forming a new atomic question state. This iterative decomposition-contraction process continues until reaching directly solvable atomic questions, naturally realizing Markov transitions between question states. Furthermore, these atomic questions can be seamlessly integrated into existing test-time scaling methods, enabling AoT to serve as a plug-in enhancement for improving reasoning capabilities. Experiments across six benchmarks demonstrate the effectiveness of AoT both as a standalone framework and a plug-in enhancement. Notably, on HotpotQA, when applied to gpt-4o-mini, AoT achieves an 80.6% F1 score, surpassing o3-mini by 3.4% and DeepSeek-R1 by 10.6%. The code will be available at https://github.com/qixucen/atom.
Self-Supervised Prompt Optimization
Feb 07, 2025



Well-designed prompts are crucial for enhancing Large language models' (LLMs) reasoning capabilities while aligning their outputs with task requirements across diverse domains. However, manually designed prompts require expertise and iterative experimentation. While existing prompt optimization methods aim to automate this process, they rely heavily on external references such as ground truth or by humans, limiting their applicability in real-world scenarios where such data is unavailable or costly to obtain. To address this, we propose Self-Supervised Prompt Optimization (SPO), a cost-efficient framework that discovers effective prompts for both closed and open-ended tasks without requiring external reference. Motivated by the observations that prompt quality manifests directly in LLM outputs and LLMs can effectively assess adherence to task requirements, we derive evaluation and optimization signals purely from output comparisons. Specifically, SPO selects superior prompts through pairwise output comparisons evaluated by an LLM evaluator, followed by an LLM optimizer that aligns outputs with task requirements. Extensive experiments demonstrate that SPO outperforms state-of-the-art prompt optimization methods, achieving comparable or superior results with significantly lower costs (e.g., 1.1% to 5.6% of existing methods) and fewer samples (e.g., three samples). The code is available at https://github.com/geekan/MetaGPT.
AFlow: Automating Agentic Workflow Generation
Oct 14, 2024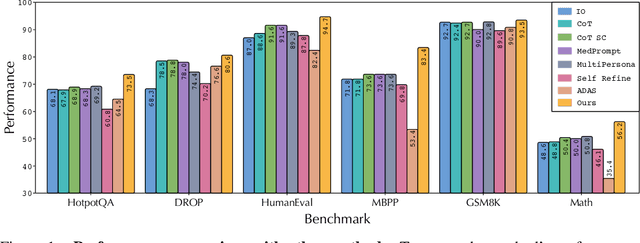

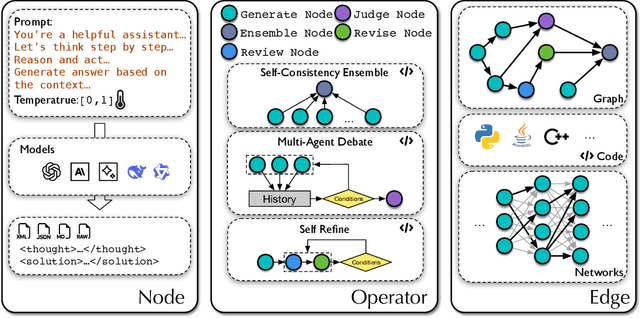
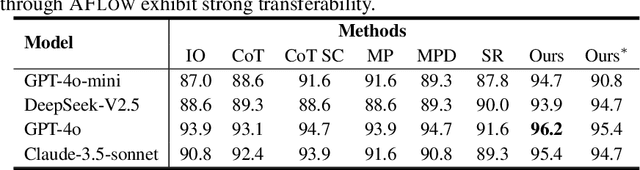
Large language models (LLMs) have demonstrated remarkable potential in solving complex tasks across diverse domains, typically by employing agentic workflows that follow detailed instructions and operational sequences. However, constructing these workflows requires significant human effort, limiting scalability and generalizability. Recent research has sought to automate the generation and optimization of these workflows, but existing methods still rely on initial manual setup and fall short of achieving fully automated and effective workflow generation. To address this challenge, we reformulate workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. We introduce AFlow, an automated framework that efficiently explores this space using Monte Carlo Tree Search, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Empirical evaluations across six benchmark datasets demonstrate AFlow's efficacy, yielding a 5.7% average improvement over state-of-the-art baselines. Furthermore, AFlow enables smaller models to outperform GPT-4o on specific tasks at 4.55% of its inference cost in dollars. The code will be available at https://github.com/geekan/MetaGPT.