 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleash the Power of Local Representations for Few-Shot Classification
Jul 02, 2024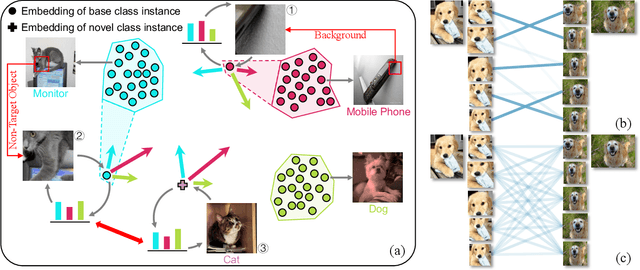
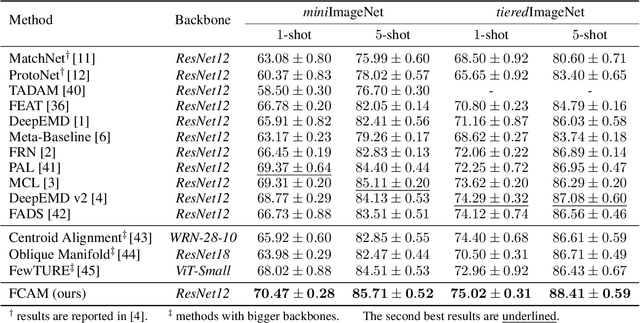
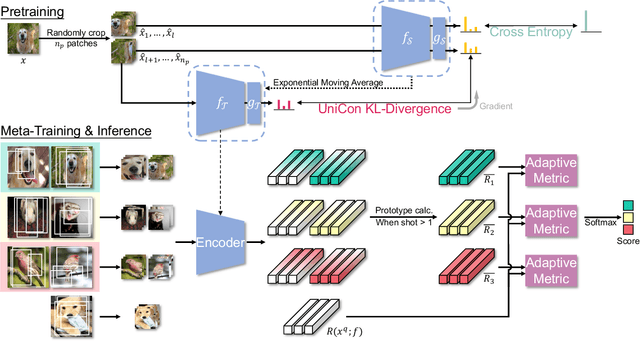
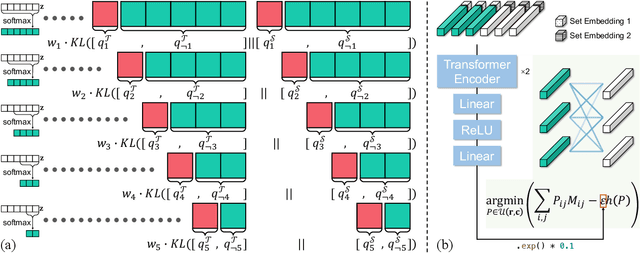
Generalizing to novel classes unseen during training is a key challenge of few-shot classification. Recent metric-based methods try to address this by local representations. However, they are unable to take full advantage of them due to (i) improper supervision for pretraining the feature extractor, and (ii) lack of adaptability in the metric for handling various possible compositions of local feature sets. In this work, we unleash the power of local representations in improving novel-class generalization. For the feature extractor, we design a novel pretraining paradigm that learns randomly cropped patches by soft labels. It utilizes the class-level diversity of patches while diminishing the impact of their semantic misalignments to hard labels. To align network output with soft labels, we also propose a UniCon KL-Divergence that emphasizes the equal contribution of each base class in describing "non-base" patches. For the metric, we formulate measuring local feature sets as an entropy-regularized optimal transport problem to introduce the ability to handle sets consisting of homogeneous elements. Furthermore, we design a Modulate Module to endow the metric with the necessary adaptability. Our method achieves new state-of-the-art performance on three popular benchmarks. Moreover, it exceeds state-of-the-art transductive and cross-modal methods in the fine-grained scenario.
RealFlow: EM-based Realistic Optical Flow Dataset Generation from Videos
Jul 22, 2022
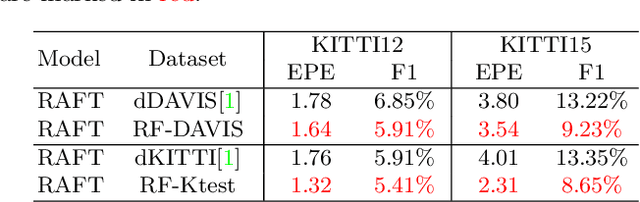
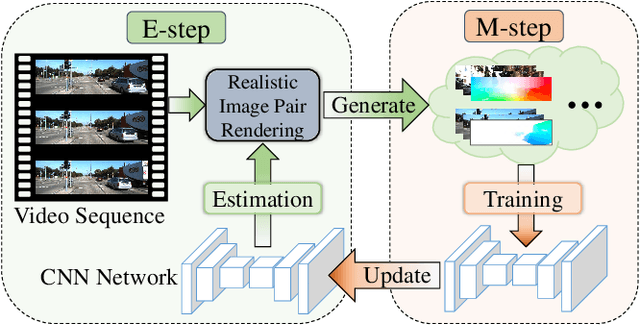
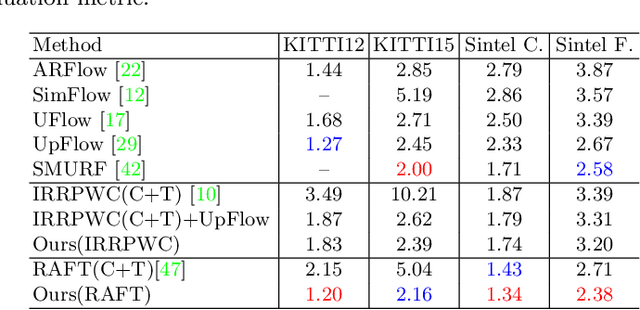
Obtaining the ground truth labels from a video is challenging since the manual annotation of pixel-wise flow labels is prohibitively expensive and laborious. Besides, existing approaches try to adapt the trained model on synthetic datasets to authentic videos, which inevitably suffers from domain discrepancy and hinders the performance for real-world applications. To solve these problems, we propose RealFlow, an Expectation-Maximization based framework that can create large-scale optical flow datasets directly from any unlabeled realistic videos. Specifically, we first estimate optical flow between a pair of video frames, and then synthesize a new image from this pair based on the predicted flow. Thus the new image pairs and their corresponding flows can be regarded as a new training set. Besides, we design a Realistic Image Pair Rendering (RIPR) module that adopts softmax splatting and bi-directional hole filling techniques to alleviate the artifacts of the image synthesis. In the E-step, RIPR renders new images to create a large quantity of training data. In the M-step, we utilize the generated training data to train an optical flow network, which can be used to estimate optical flows in the next E-step. During the iterative learning steps, the capability of the flow network is gradually improved, so is the accuracy of the flow, as well as the quality of the synthesized dataset. Experimental results show that RealFlow outperforms previous dataset generation methods by a considerably large margin. Moreover, based on the generated dataset, our approach achieves state-of-the-art performance on two standard benchmarks compared with both supervised and unsupervised optical flow methods. Our code and dataset are available at https://github.com/megvii-research/RealFlow
Parallel ensemble methods for causal direction inference
Jun 05, 2020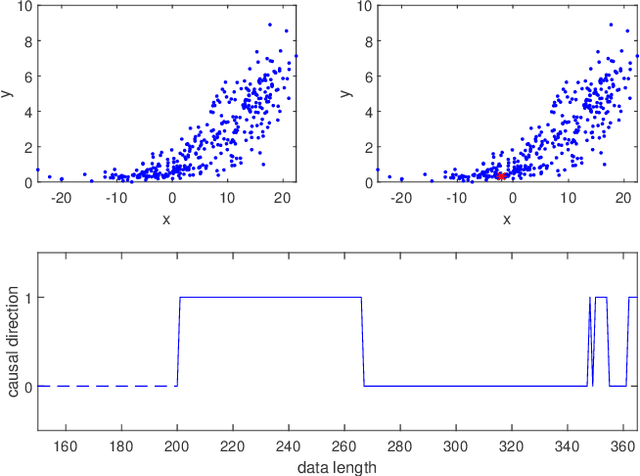
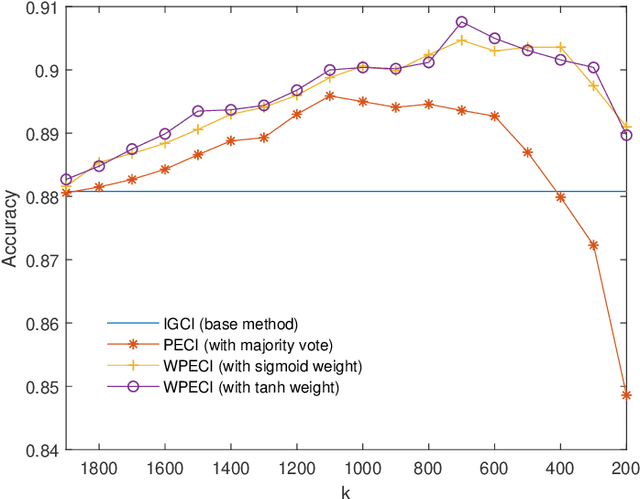
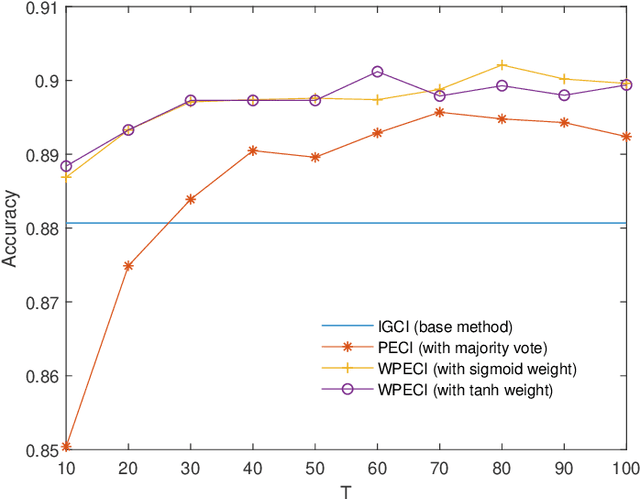
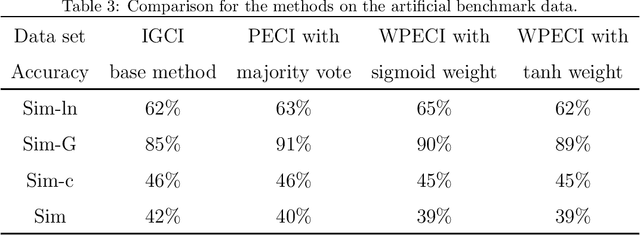
Inferring the causal direction between two variables from their observation data is one of the most fundamental and challenging topics in data science. A causal direction inference algorithm maps the observation data into a binary value which represents either x causes y or y causes x. The nature of these algorithms makes the results unstable with the change of data points. Therefore the accuracy of the causal direction inference can be improved significantly by using parallel ensemble frameworks. In this paper, new causal direction inference algorithms based on several ways of parallel ensemble are proposed. Theoretical analyses on accuracy rates are given. Experiments are done on both of the artificial data sets and the real world data sets. The accuracy performances of the methods and their computational efficiencies in parallel computing environment are demonstrated.
Large Kernel Matters -- Improve Semantic Segmentation by Global Convolutional Network
Mar 08, 2017

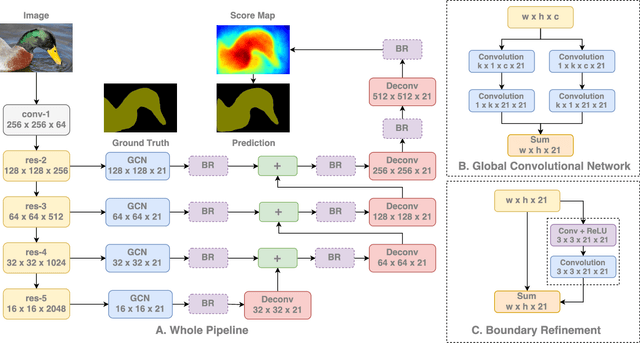
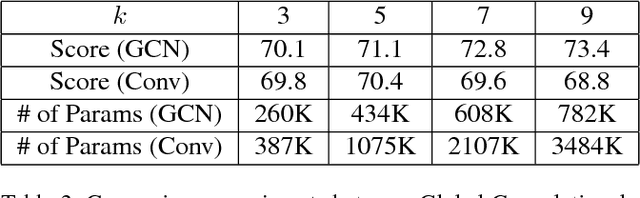
One of recent trends [30, 31, 14] in network architec- ture design is stacking small filters (e.g., 1x1 or 3x3) in the entire network because the stacked small filters is more ef- ficient than a large kernel, given the same computational complexity. However, in the field of semantic segmenta- tion, where we need to perform dense per-pixel prediction, we find that the large kernel (and effective receptive field) plays an important role when we have to perform the clas- sification and localization tasks simultaneously. Following our design principle, we propose a Global Convolutional Network to address both the classification and localization issues for the semantic segmentation. We also suggest a residual-based boundary refinement to further refine the ob- ject boundaries. Our approach achieves state-of-art perfor- mance on two public benchmarks and significantly outper- forms previous results, 82.2% (vs 80.2%) on PASCAL VOC 2012 dataset and 76.9% (vs 71.8%) on Cityscapes dataset.
Some Supplementaries to The Counting Semantics for Abstract Argumentation
Sep 11, 2015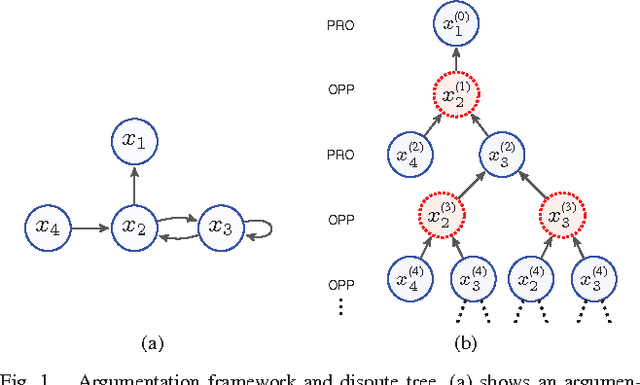
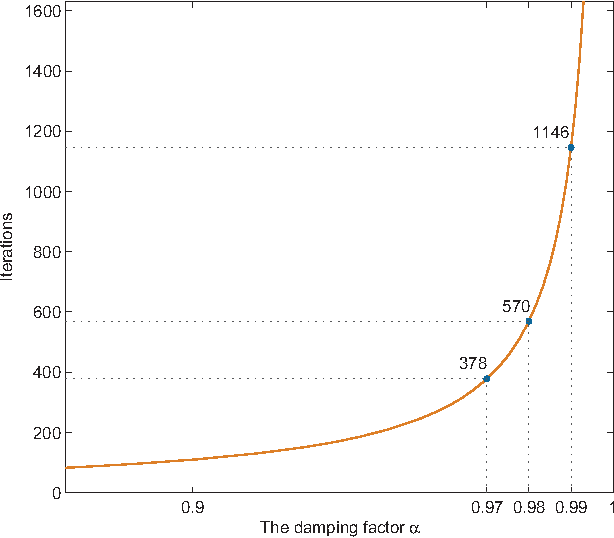
Dung's abstract argumentation framework consists of a set of interacting arguments and a series of semantics for evaluating them. Those semantics partition the powerset of the set of arguments into two classes: extensions and non-extensions. In order to reason with a specific semantics, one needs to take a credulous or skeptical approach, i.e. an argument is eventually accepted, if it is accepted in one or all extensions, respectively. In our previous work \cite{ref-pu2015counting}, we have proposed a novel semantics, called \emph{counting semantics}, which allows for a more fine-grained assessment to arguments by counting the number of their respective attackers and defenders based on argument graph and argument game. In this paper, we continue our previous work by presenting some supplementaries about how to choose the damaging factor for the counting semantics, and what relationships with some existing approaches, such as Dung's classical semantics, generic gradual valuations. Lastly, an axiomatic perspective on the ranking semantics induced by our counting semantics are presented.
Attacker and Defender Counting Approach for Abstract Argumentation
Jun 13, 2015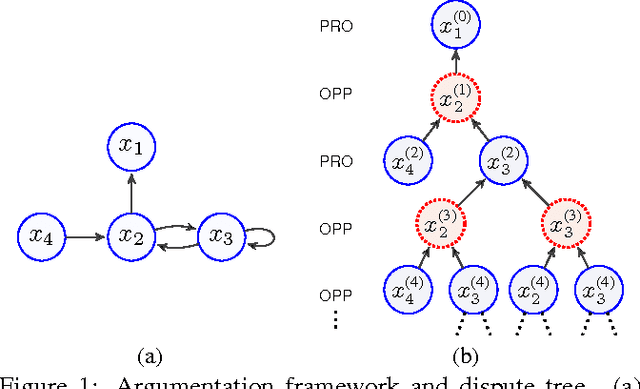
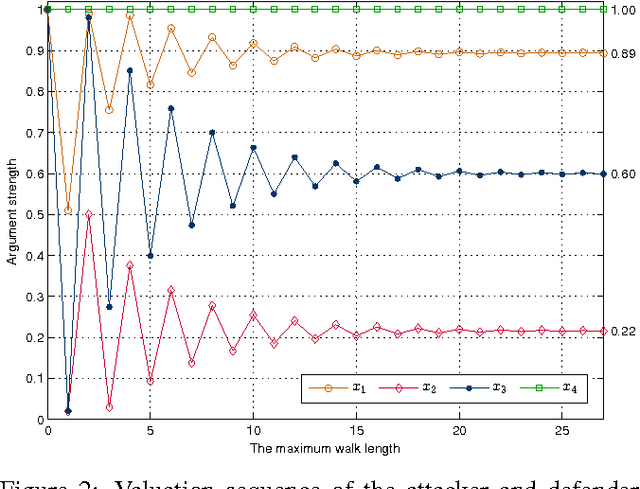
In Dung's abstract argumentation, arguments are either acceptable or unacceptable, given a chosen notion of acceptability. This gives a coarse way to compare arguments. In this paper, we propose a counting approach for a more fine-gained assessment to arguments by counting the number of their respective attackers and defenders based on argument graph and argument game. An argument is more acceptable if the proponent puts forward more number of defenders for it and the opponent puts forward less number of attackers against it. We show that our counting model has two well-behaved properties: normalization and convergence. Then, we define a counting semantics based on this model, and investigate some general properties of the semantics.
Argument Ranking with Categoriser Function
Jul 16, 2014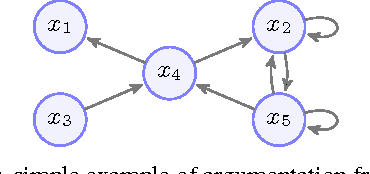
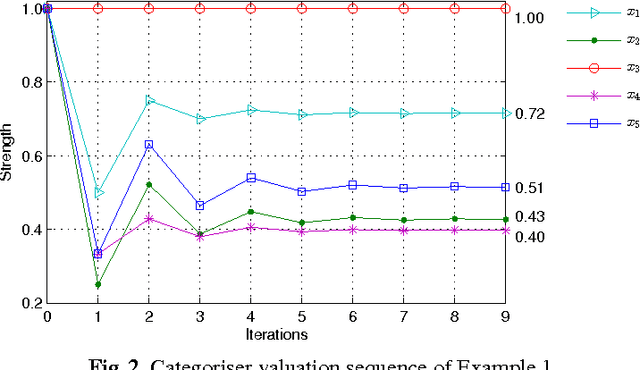
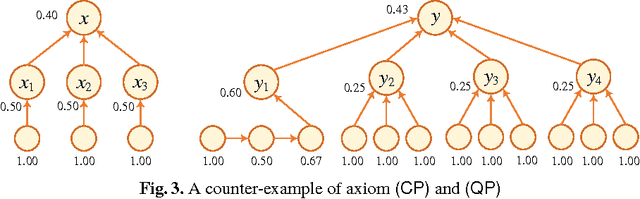
Recently, ranking-based semantics is proposed to rank-order arguments from the most acceptable to the weakest one(s), which provides a graded assessment to arguments. In general, the ranking on arguments is derived from the strength values of the arguments. Categoriser function is a common approach that assigns a strength value to a tree of arguments. When it encounters an argument system with cycles, then the categoriser strength is the solution of the non-linear equations. However, there is no detail about the existence and uniqueness of the solution, and how to find the solution (if exists). In this paper, we will cope with these issues via fixed point technique. In addition, we define the categoriser-based ranking semantics in light of categoriser strength, and investigate some general properties of it. Finally, the semantics is shown to satisfy some of the axioms that a ranking-based semantics should satisfy.