 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleash the Power of Local Representations for Few-Shot Classification
Jul 02, 2024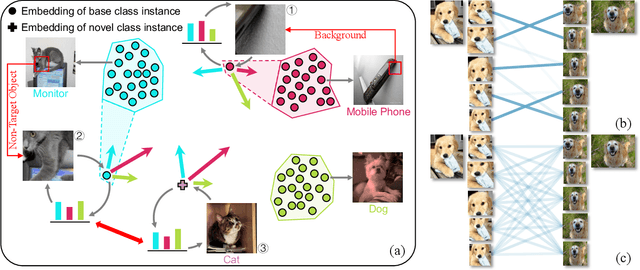
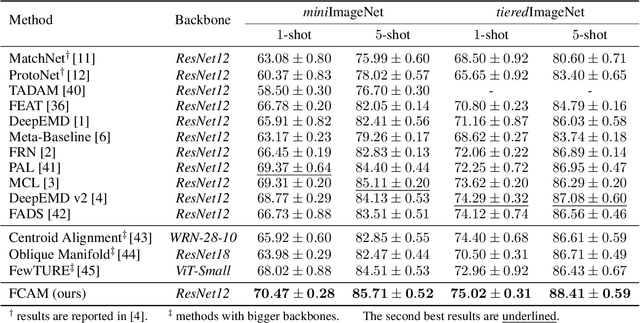
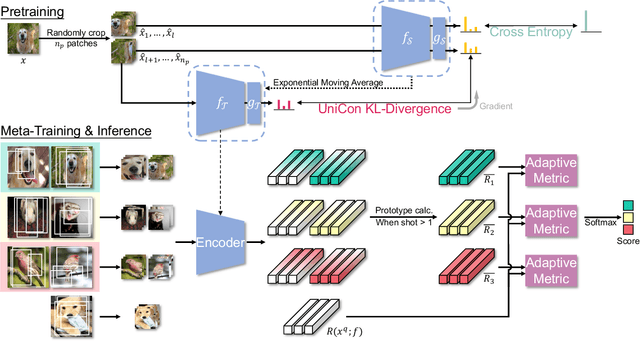
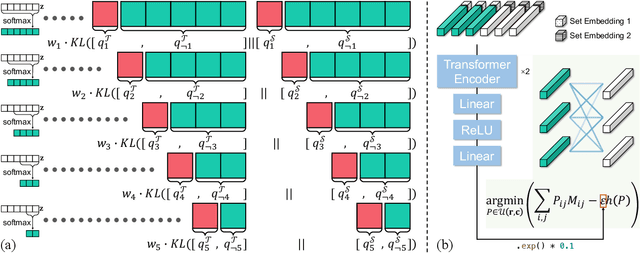
Generalizing to novel classes unseen during training is a key challenge of few-shot classification. Recent metric-based methods try to address this by local representations. However, they are unable to take full advantage of them due to (i) improper supervision for pretraining the feature extractor, and (ii) lack of adaptability in the metric for handling various possible compositions of local feature sets. In this work, we unleash the power of local representations in improving novel-class generalization. For the feature extractor, we design a novel pretraining paradigm that learns randomly cropped patches by soft labels. It utilizes the class-level diversity of patches while diminishing the impact of their semantic misalignments to hard labels. To align network output with soft labels, we also propose a UniCon KL-Divergence that emphasizes the equal contribution of each base class in describing "non-base" patches. For the metric, we formulate measuring local feature sets as an entropy-regularized optimal transport problem to introduce the ability to handle sets consisting of homogeneous elements. Furthermore, we design a Modulate Module to endow the metric with the necessary adaptability. Our method achieves new state-of-the-art performance on three popular benchmarks. Moreover, it exceeds state-of-the-art transductive and cross-modal methods in the fine-grained scenario.