 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMExD: An Expert-Infused Diffusion Model for Whole-Slide Image Classification
Mar 16, 2025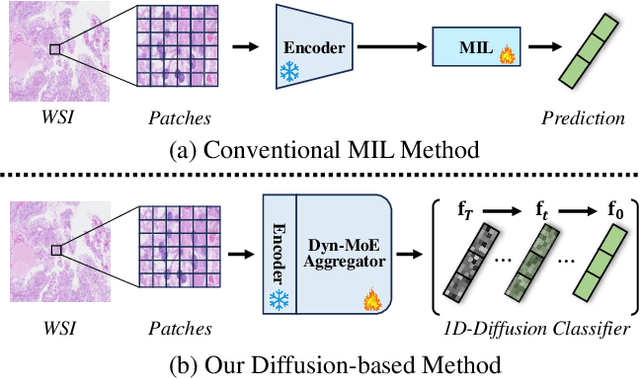
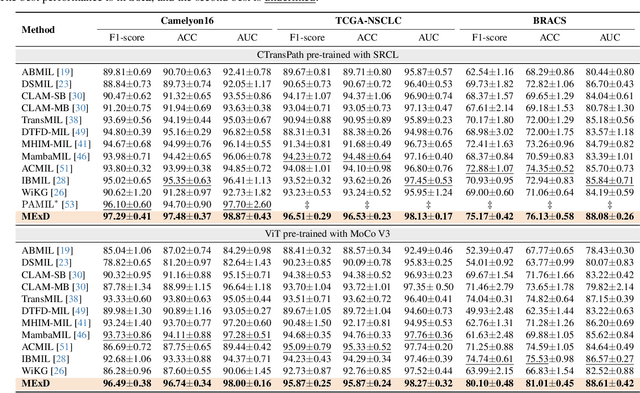
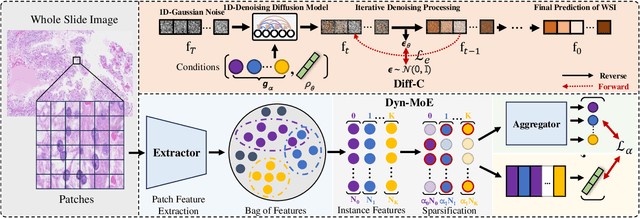
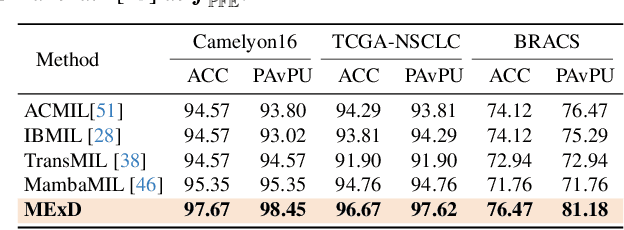
Whole Slide Image (WSI) classification poses unique challenges due to the vast image size and numerous non-informative regions, which introduce noise and cause data imbalance during feature aggregation. To address these issues, we propose MExD, an Expert-Infused Diffusion Model that combines the strengths of a Mixture-of-Experts (MoE) mechanism with a diffusion model for enhanced classification. MExD balances patch feature distribution through a novel MoE-based aggregator that selectively emphasizes relevant information, effectively filtering noise, addressing data imbalance, and extracting essential features. These features are then integrated via a diffusion-based generative process to directly yield the class distribution for the WSI. Moving beyond conventional discriminative approaches, MExD represents the first generative strategy in WSI classification, capturing fine-grained details for robust and precise results. Our MExD is validated on three widely-used benchmarks-Camelyon16, TCGA-NSCLC, and BRACS consistently achieving state-of-the-art performance in both binary and multi-class tasks.
Template Matters: Understanding the Role of Instruction Templates in Multimodal Language Model Evaluation and Training
Dec 11, 2024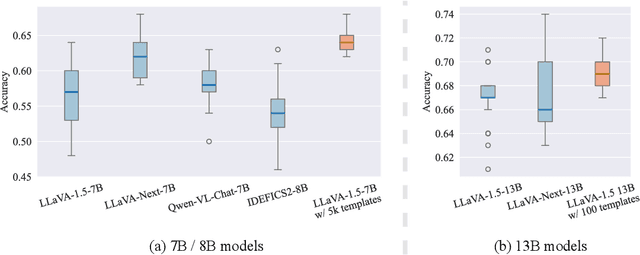
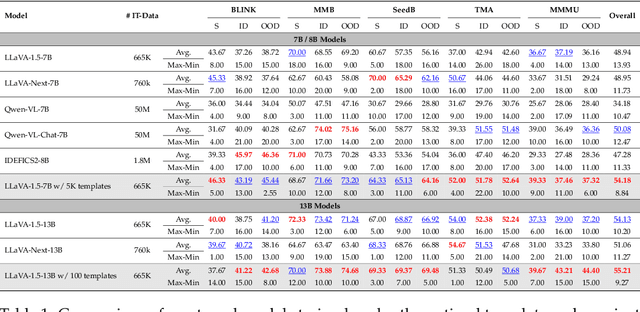

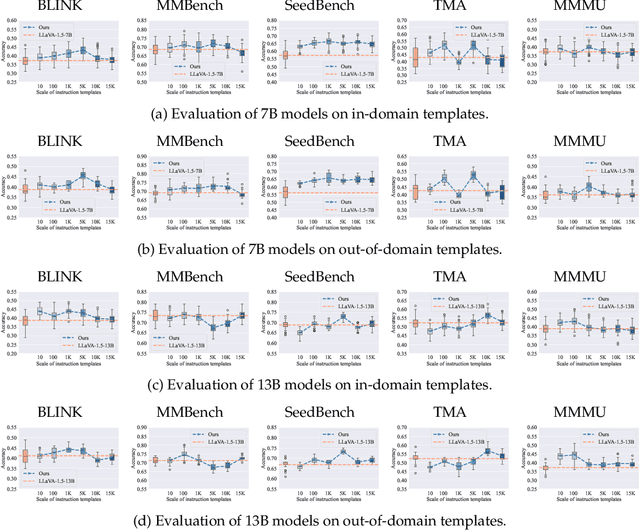
Current multimodal language models (MLMs) evaluation and training approaches overlook the influence of instruction format, presenting an elephant-in-the-room problem. Previous research deals with this problem by manually crafting instructions, failing to yield significant insights due to limitations in diversity and scalability. In this work, we propose a programmatic instruction template generator capable of producing over 39B unique template combinations by filling randomly sampled positional synonyms into weighted sampled meta templates, enabling us to comprehensively examine the MLM's performance across diverse instruction templates. Our experiments across eight common MLMs on five benchmark datasets reveal that MLMs have high template sensitivities with at most 29% performance gaps between different templates. We further augment the instruction tuning dataset of LLaVA-1.5 with our template generator and perform instruction tuning on LLaVA-1.5-7B and LLaVA-1.5-13B. Models tuned on our augmented dataset achieve the best overall performance when compared with the same scale MLMs tuned on at most 75 times the scale of our augmented dataset, highlighting the importance of instruction templates in MLM training. The code is available at https://github.com/shijian2001/TemplateMatters .
Forensics Adapter: Adapting CLIP for Generalizable Face Forgery Detection
Nov 29, 2024We describe the Forensics Adapter, an adapter network designed to transform CLIP into an effective and generalizable face forgery detector. Although CLIP is highly versatile, adapting it for face forgery detection is non-trivial as forgery-related knowledge is entangled with a wide range of unrelated knowledge. Existing methods treat CLIP merely as a feature extractor, lacking task-specific adaptation, which limits their effectiveness. To address this, we introduce an adapter to learn face forgery traces -- the blending boundaries unique to forged faces, guided by task-specific objectives. Then we enhance the CLIP visual tokens with a dedicated interaction strategy that communicates knowledge across CLIP and the adapter. Since the adapter is alongside CLIP, its versatility is highly retained, naturally ensuring strong generalizability in face forgery detection. With only $\bm{5.7M}$ trainable parameters, our method achieves a significant performance boost, improving by approximately $\bm{7\%}$ on average across five standard datasets. We believe the proposed method can serve as a baseline for future CLIP-based face forgery detection methods.
Advancing Open-Set Domain Generalization Using Evidential Bi-Level Hardest Domain Scheduler
Sep 26, 2024



In Open-Set Domain Generalization (OSDG), the model is exposed to both new variations of data appearance (domains) and open-set conditions, where both known and novel categories are present at test time. The challenges of this task arise from the dual need to generalize across diverse domains and accurately quantify category novelty, which is critical for applications in dynamic environments. Recently, meta-learning techniques have demonstrated superior results in OSDG, effectively orchestrating the meta-train and -test tasks by employing varied random categories and predefined domain partition strategies. These approaches prioritize a well-designed training schedule over traditional methods that focus primarily on data augmentation and the enhancement of discriminative feature learning. The prevailing meta-learning models in OSDG typically utilize a predefined sequential domain scheduler to structure data partitions. However, a crucial aspect that remains inadequately explored is the influence brought by strategies of domain schedulers during training. In this paper, we observe that an adaptive domain scheduler benefits more in OSDG compared with prefixed sequential and random domain schedulers. We propose the Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) to achieve an adaptive domain scheduler. This method strategically sequences domains by assessing their reliabilities in utilizing a follower network, trained with confidence scores learned in an evidential manner, regularized by max rebiasing discrepancy, and optimized in a bi-level manner. The results show that our method substantially improves OSDG performance and achieves more discriminative embeddings for both the seen and unseen categories. The source code will be available at https://github.com/KPeng9510/EBiL-HaDS.
FastForensics: Efficient Two-Stream Design for Real-Time Image Manipulation Detection
Aug 29, 2024With the rise in popularity of portable devices, the spread of falsified media on social platforms has become rampant. This necessitates the timely identification of authentic content. However, most advanced detection methods are computationally heavy, hindering their real-time application. In this paper, we describe an efficient two-stream architecture for real-time image manipulation detection. Our method consists of two-stream branches targeting the cognitive and inspective perspectives. In the cognitive branch, we propose efficient wavelet-guided Transformer blocks to capture the global manipulation traces related to frequency. This block contains an interactive wavelet-guided self-attention module that integrates wavelet transformation with efficient attention design, interacting with the knowledge from the inspective branch. The inspective branch consists of simple convolutions that capture fine-grained traces and interact bidirectionally with Transformer blocks to provide mutual support. Our method is lightweight ($\sim$ 8M) but achieves competitive performance compared to many other counterparts, demonstrating its efficacy in image manipulation detection and its potential for portable integration.
FocusDiffuser: Perceiving Local Disparities for Camouflaged Object Detection
Jul 18, 2024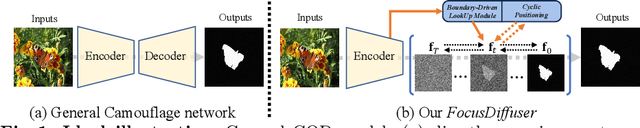
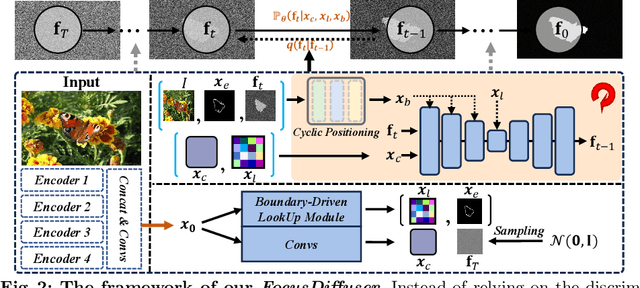

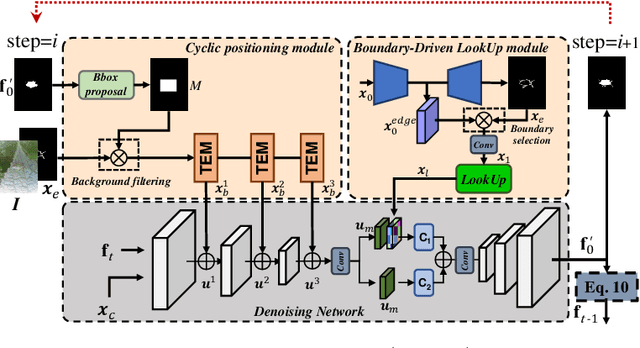
Detecting objects seamlessly blended into their surroundings represents a complex task for both human cognitive capabilities and advanced artificial intelligence algorithms. Currently, the majority of methodologies for detecting camouflaged objects mainly focus on utilizing discriminative models with various unique designs. However, it has been observed that generative models, such as Stable Diffusion, possess stronger capabilities for understanding various objects in complex environments; Yet their potential for the cognition and detection of camouflaged objects has not been extensively explored. In this study, we present a novel denoising diffusion model, namely FocusDiffuser, to investigate how generative models can enhance the detection and interpretation of camouflaged objects. We believe that the secret to spotting camouflaged objects lies in catching the subtle nuances in details. Consequently, our FocusDiffuser innovatively integrates specialized enhancements, notably the Boundary-Driven LookUp (BDLU) module and Cyclic Positioning (CP) module, to elevate standard diffusion models, significantly boosting the detail-oriented analytical capabilities. Our experiments demonstrate that FocusDiffuser, from a generative perspective, effectively addresses the challenge of camouflaged object detection, surpassing leading models on benchmarks like CAMO, COD10K and NC4K.
LightenDiffusion: Unsupervised Low-Light Image Enhancement with Latent-Retinex Diffusion Models
Jul 12, 2024



In this paper, we propose a diffusion-based unsupervised framework that incorporates physically explainable Retinex theory with diffusion models for low-light image enhancement, named LightenDiffusion. Specifically, we present a content-transfer decomposition network that performs Retinex decomposition within the latent space instead of image space as in previous approaches, enabling the encoded features of unpaired low-light and normal-light images to be decomposed into content-rich reflectance maps and content-free illumination maps. Subsequently, the reflectance map of the low-light image and the illumination map of the normal-light image are taken as input to the diffusion model for unsupervised restoration with the guidance of the low-light feature, where a self-constrained consistency loss is further proposed to eliminate the interference of normal-light content on the restored results to improve overall visual quality. Extensive experiments on publicly available real-world benchmarks show that the proposed LightenDiffusion outperforms state-of-the-art unsupervised competitors and is comparable to supervised methods while being more generalizable to various scenes. Our code is available at https://github.com/JianghaiSCU/LightenDiffusion.
Adaptive In-conversation Team Building for Language Model Agents
May 29, 2024
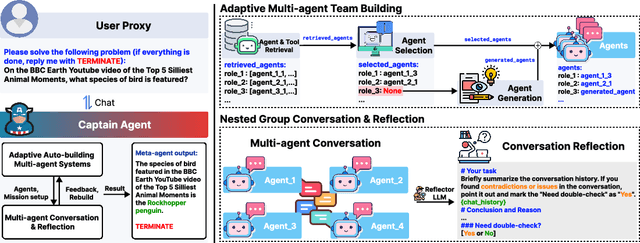

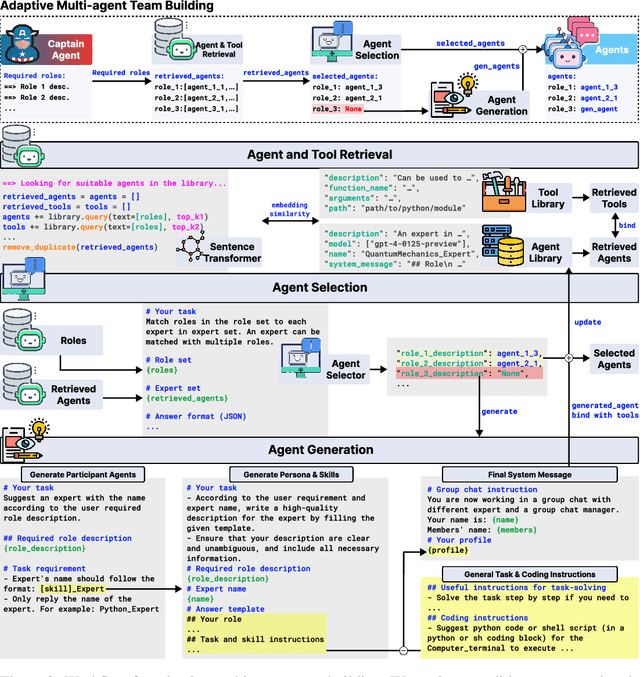
Leveraging multiple large language model (LLM) agents has shown to be a promising approach for tackling complex tasks, while the effective design of multiple agents for a particular application remains an art. It is thus intriguing to answer a critical question: Given a task, how can we build a team of LLM agents to solve it effectively? Our new adaptive team-building paradigm offers a flexible solution, realized through a novel agent design named Captain Agent. It dynamically forms and manages teams for each step of a task-solving process, utilizing nested group conversations and reflection to ensure diverse expertise and prevent stereotypical outputs. It allows for a flexible yet structured approach to problem-solving and can help reduce redundancy and enhance output diversity. A comprehensive evaluation across six real-world scenarios demonstrates that Captain Agent significantly outperforms existing multi-agent methods with 21.94% improvement in average accuracy, providing outstanding performance without requiring task-specific prompt engineering.
RecDiffusion: Rectangling for Image Stitching with Diffusion Models
Mar 28, 2024



Image stitching from different captures often results in non-rectangular boundaries, which is often considered unappealing. To solve non-rectangular boundaries, current solutions involve cropping, which discards image content, inpainting, which can introduce unrelated content, or warping, which can distort non-linear features and introduce artifacts. To overcome these issues, we introduce a novel diffusion-based learning framework, \textbf{RecDiffusion}, for image stitching rectangling. This framework combines Motion Diffusion Models (MDM) to generate motion fields, effectively transitioning from the stitched image's irregular borders to a geometrically corrected intermediary. Followed by Content Diffusion Models (CDM) for image detail refinement. Notably, our sampling process utilizes a weighted map to identify regions needing correction during each iteration of CDM. Our RecDiffusion ensures geometric accuracy and overall visual appeal, surpassing all previous methods in both quantitative and qualitative measures when evaluated on public benchmarks. Code is released at https://github.com/lhaippp/RecDiffusion.
Better Explain Transformers by Illuminating Important Information
Jan 26, 2024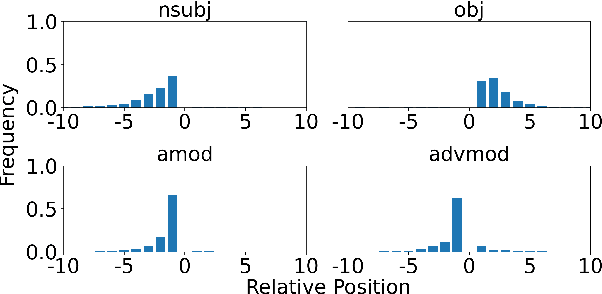
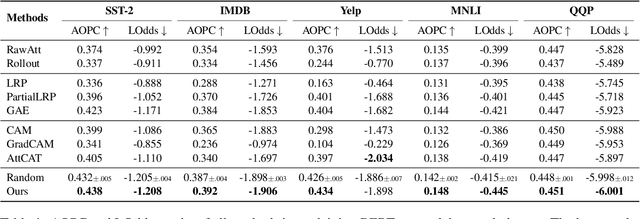
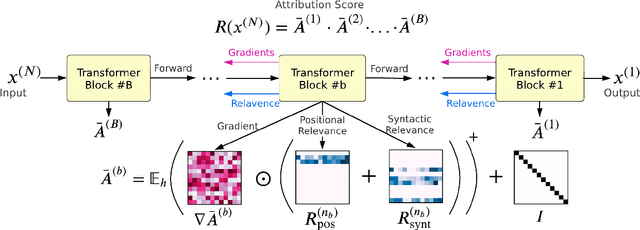
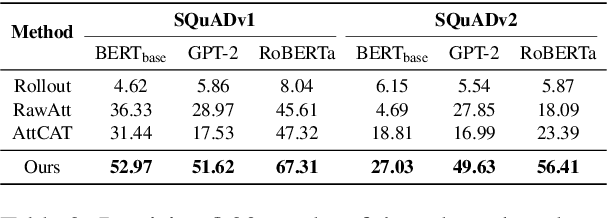
Transformer-based models excel in various natural language processing (NLP) tasks, attracting countless efforts to explain their inner workings. Prior methods explain Transformers by focusing on the raw gradient and attention as token attribution scores, where non-relevant information is often considered during explanation computation, resulting in confusing results. In this work, we propose highlighting the important information and eliminating irrelevant information by a refined information flow on top of the layer-wise relevance propagation (LRP) method. Specifically, we consider identifying syntactic and positional heads as important attention heads and focus on the relevance obtained from these important heads. Experimental results demonstrate that irrelevant information does distort output attribution scores and then should be masked during explanation computation. Compared to eight baselines on both classification and question-answering datasets, our method consistently outperforms with over 3\% to 33\% improvement on explanation metrics, providing superior explanation performance. Our anonymous code repository is available at: https://github.com/LinxinS97/Mask-LRP