 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightenDiffusion: Unsupervised Low-Light Image Enhancement with Latent-Retinex Diffusion Models
Jul 12, 2024



In this paper, we propose a diffusion-based unsupervised framework that incorporates physically explainable Retinex theory with diffusion models for low-light image enhancement, named LightenDiffusion. Specifically, we present a content-transfer decomposition network that performs Retinex decomposition within the latent space instead of image space as in previous approaches, enabling the encoded features of unpaired low-light and normal-light images to be decomposed into content-rich reflectance maps and content-free illumination maps. Subsequently, the reflectance map of the low-light image and the illumination map of the normal-light image are taken as input to the diffusion model for unsupervised restoration with the guidance of the low-light feature, where a self-constrained consistency loss is further proposed to eliminate the interference of normal-light content on the restored results to improve overall visual quality. Extensive experiments on publicly available real-world benchmarks show that the proposed LightenDiffusion outperforms state-of-the-art unsupervised competitors and is comparable to supervised methods while being more generalizable to various scenes. Our code is available at https://github.com/JianghaiSCU/LightenDiffusion.
Supervised Homography Learning with Realistic Dataset Generation
Aug 15, 2023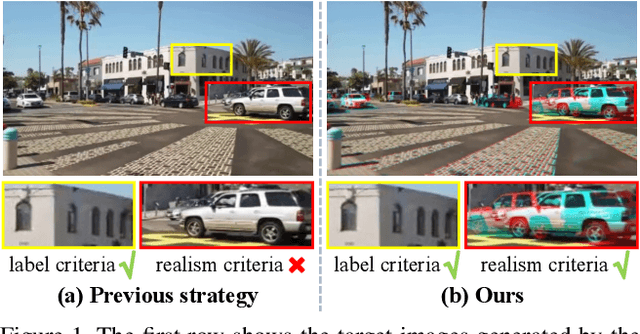
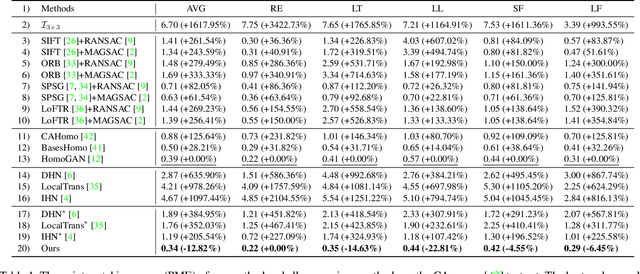
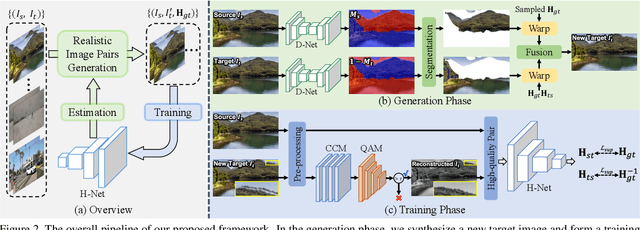
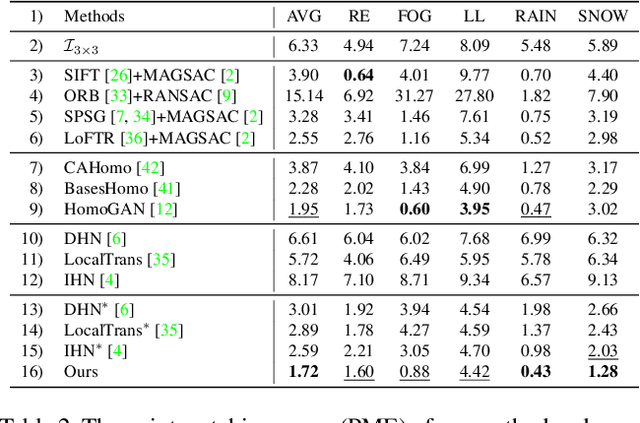
In this paper, we propose an iterative framework, which consists of two phases: a generation phase and a training phase, to generate realistic training data and yield a supervised homography network. In the generation phase, given an unlabeled image pair, we utilize the pre-estimated dominant plane masks and homography of the pair, along with another sampled homography that serves as ground truth to generate a new labeled training pair with realistic motion. In the training phase, the generated data is used to train the supervised homography network, in which the training data is refined via a content consistency module and a quality assessment module. Once an iteration is finished, the trained network is used in the next data generation phase to update the pre-estimated homography. Through such an iterative strategy, the quality of the dataset and the performance of the network can be gradually and simultaneously improved. Experimental results show that our method achieves state-of-the-art performance and existing supervised methods can be also improved based on the generated dataset. Code and dataset are available at https://github.com/JianghaiSCU/RealSH.
Low-Light Image Enhancement with Wavelet-based Diffusion Models
Jun 01, 2023Diffusion models have achieved promising results in image restoration tasks, yet suffer from time-consuming, excessive computational resource consumption, and unstable restoration. To address these issues, we propose a robust and efficient Diffusion-based Low-Light image enhancement approach, dubbed DiffLL. Specifically, we present a wavelet-based conditional diffusion model (WCDM) that leverages the generative power of diffusion models to produce results with satisfactory perceptual fidelity. Additionally, it also takes advantage of the strengths of wavelet transformation to greatly accelerate inference and reduce computational resource usage without sacrificing information. To avoid chaotic content and diversity, we perform both forward diffusion and reverse denoising in the training phase of WCDM, enabling the model to achieve stable denoising and reduce randomness during inference. Moreover, we further design a high-frequency restoration module (HFRM) that utilizes the vertical and horizontal details of the image to complement the diagonal information for better fine-grained restoration. Extensive experiments on publicly available real-world benchmarks demonstrate that our method outperforms the existing state-of-the-art methods both quantitatively and visually, and it achieves remarkable improvements in efficiency compared to previous diffusion-based methods. In addition, we empirically show that the application for low-light face detection also reveals the latent practical values of our method.
Semi-supervised Deep Large-baseline Homography Estimation with Progressive Equivalence Constraint
Dec 06, 2022Homography estimation is erroneous in the case of large-baseline due to the low image overlay and limited receptive field. To address it, we propose a progressive estimation strategy by converting large-baseline homography into multiple intermediate ones, cumulatively multiplying these intermediate items can reconstruct the initial homography. Meanwhile, a semi-supervised homography identity loss, which consists of two components: a supervised objective and an unsupervised objective, is introduced. The first supervised loss is acting to optimize intermediate homographies, while the second unsupervised one helps to estimate a large-baseline homography without photometric losses. To validate our method, we propose a large-scale dataset that covers regular and challenging scenes. Experiments show that our method achieves state-of-the-art performance in large-baseline scenes while keeping competitive performance in small-baseline scenes. Code and dataset are available at https://github.com/megvii-research/LBHomo.
R2RNet: Low-light Image Enhancement via Real-low to Real-normal Network
Jun 28, 2021

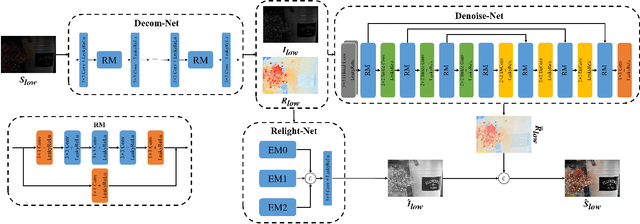

Images captured in weak illumination conditions will seriously degrade the image quality. Solving a series of degradation of low-light images can effectively improve the visual quality of the image and the performance of high-level visual tasks. In this paper, we propose a novel Real-low to Real-normal Network for low-light image enhancement, dubbed R2RNet, based on the Retinex theory, which includes three subnets: a Decom-Net, a Denoise-Net, and a Relight-Net. These three subnets are used for decomposing, denoising, and contrast enhancement, respectively. Unlike most previous methods trained on synthetic images, we collect the first Large-Scale Real-World paired low/normal-light images dataset (LSRW dataset) for training. Our method can properly improve the contrast and suppress noise simultaneously. Extensive experiments on publicly available datasets demonstrate that our method outperforms the existing state-of-the-art methods by a large margin both quantitatively and visually. And we also show that the performance of the high-level visual task (\emph{i.e.} face detection) can be effectively improved by using the enhanced results obtained by our method in low-light conditions. Our codes and the LSRW dataset are available at: https://github.com/abcdef2000/R2RNet.