 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-the-shelf Vision Models Benefit Image Manipulation Localization
Apr 10, 2026Image manipulation localization (IML) and general vision tasks are typically treated as two separate research directions due to the fundamental differences between manipulation-specific and semantic features. In this paper, however, we bridge this gap by introducing a fresh perspective: these two directions are intrinsically connected, and general semantic priors can benefit IML. Building on this insight, we propose a novel trainable adapter (named ReVi) that repurposes existing off-the-shelf general-purpose vision models (e.g., image generation and segmentation networks) for IML. Inspired by robust principal component analysis, the adapter disentangles semantic redundancy from manipulation-specific information embedded in these models and selectively enhances the latter. Unlike existing IML methods that require extensive model redesign and full retraining, our method relies on the off-the-shelf vision models with frozen parameters and only fine-tunes the proposed adapter. The experimental results demonstrate the superiority of our method, showing the potential for scalable IML frameworks.
Detecting Diffusion-generated Images via Dynamic Assembly ForestsDetecting Diffusion-generated Images via Dynamic Assembly Forests
Apr 10, 2026Diffusion models are known for generating high-quality images, causing serious security concerns. To combat this, most efforts rely on deep neural networks (e.g., CNNs and Transformers), while largely overlooking the potential of traditional machine learning models. In this paper, we freshly investigate such alternatives and proposes a novel Dynamic Assembly Forest model (DAF) to detect diffusion-generated images. Built upon the deep forest paradigm, DAF addresses the inherent limitations in feature learning and scalable training, making it an effective diffusion-generated image detector. Compared to existing DNN-based methods, DAF has significantly fewer parameters, much lower computational cost, and can be deployed without GPUs, while achieving competitive performance under standard evaluation protocols. These results highlight the strong potential of the proposed method as a practical substitute for heavyweight DNN models in resource-constrained scenarios. Our code and models are available at https://github.com/OUC-VAS/DAF.
Boosting Active Defense Persistence: A Two-Stage Defense Framework Combining Interruption and Poisoning Against Deepfake
Aug 11, 2025Active defense strategies have been developed to counter the threat of deepfake technology. However, a primary challenge is their lack of persistence, as their effectiveness is often short-lived. Attackers can bypass these defenses by simply collecting protected samples and retraining their models. This means that static defenses inevitably fail when attackers retrain their models, which severely limits practical use. We argue that an effective defense not only distorts forged content but also blocks the model's ability to adapt, which occurs when attackers retrain their models on protected images. To achieve this, we propose an innovative Two-Stage Defense Framework (TSDF). Benefiting from the intensity separation mechanism designed in this paper, the framework uses dual-function adversarial perturbations to perform two roles. First, it can directly distort the forged results. Second, it acts as a poisoning vehicle that disrupts the data preparation process essential for an attacker's retraining pipeline. By poisoning the data source, TSDF aims to prevent the attacker's model from adapting to the defensive perturbations, thus ensuring the defense remains effective long-term. Comprehensive experiments show that the performance of traditional interruption methods degrades sharply when it is subjected to adversarial retraining. However, our framework shows a strong dual defense capability, which can improve the persistence of active defense. Our code will be available at https://github.com/vpsg-research/TSDF.
Celeb-DF++: A Large-scale Challenging Video DeepFake Benchmark for Generalizable Forensics
Jul 24, 2025The rapid advancement of AI technologies has significantly increased the diversity of DeepFake videos circulating online, posing a pressing challenge for \textit{generalizable forensics}, \ie, detecting a wide range of unseen DeepFake types using a single model. Addressing this challenge requires datasets that are not only large-scale but also rich in forgery diversity. However, most existing datasets, despite their scale, include only a limited variety of forgery types, making them insufficient for developing generalizable detection methods. Therefore, we build upon our earlier Celeb-DF dataset and introduce {Celeb-DF++}, a new large-scale and challenging video DeepFake benchmark dedicated to the generalizable forensics challenge. Celeb-DF++ covers three commonly encountered forgery scenarios: Face-swap (FS), Face-reenactment (FR), and Talking-face (TF). Each scenario contains a substantial number of high-quality forged videos, generated using a total of 22 various recent DeepFake methods. These methods differ in terms of architectures, generation pipelines, and targeted facial regions, covering the most prevalent DeepFake cases witnessed in the wild. We also introduce evaluation protocols for measuring the generalizability of 24 recent detection methods, highlighting the limitations of existing detection methods and the difficulty of our new dataset.
Where the Devil Hides: Deepfake Detectors Can No Longer Be Trusted
May 13, 2025With the advancement of AI generative techniques, Deepfake faces have become incredibly realistic and nearly indistinguishable to the human eye. To counter this, Deepfake detectors have been developed as reliable tools for assessing face authenticity. These detectors are typically developed on Deep Neural Networks (DNNs) and trained using third-party datasets. However, this protocol raises a new security risk that can seriously undermine the trustfulness of Deepfake detectors: Once the third-party data providers insert poisoned (corrupted) data maliciously, Deepfake detectors trained on these datasets will be injected ``backdoors'' that cause abnormal behavior when presented with samples containing specific triggers. This is a practical concern, as third-party providers may distribute or sell these triggers to malicious users, allowing them to manipulate detector performance and escape accountability. This paper investigates this risk in depth and describes a solution to stealthily infect Deepfake detectors. Specifically, we develop a trigger generator, that can synthesize passcode-controlled, semantic-suppression, adaptive, and invisible trigger patterns, ensuring both the stealthiness and effectiveness of these triggers. Then we discuss two poisoning scenarios, dirty-label poisoning and clean-label poisoning, to accomplish the injection of backdoors. Extensive experiments demonstrate the effectiveness, stealthiness, and practicality of our method compared to several baselines.
Hiding Faces in Plain Sight: Defending DeepFakes by Disrupting Face Detection
Dec 02, 2024


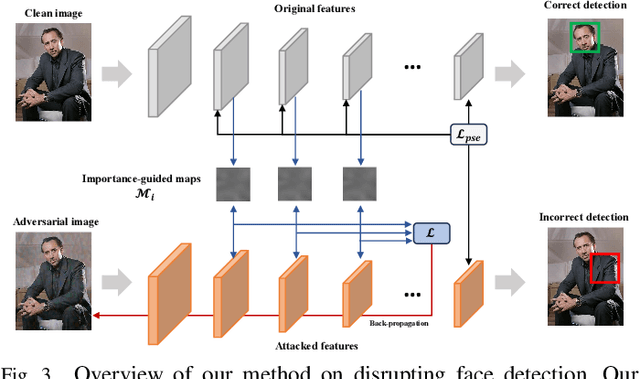
This paper investigates the feasibility of a proactive DeepFake defense framework, {\em FacePosion}, to prevent individuals from becoming victims of DeepFake videos by sabotaging face detection. The motivation stems from the reliance of most DeepFake methods on face detectors to automatically extract victim faces from videos for training or synthesis (testing). Once the face detectors malfunction, the extracted faces will be distorted or incorrect, subsequently disrupting the training or synthesis of the DeepFake model. To achieve this, we adapt various adversarial attacks with a dedicated design for this purpose and thoroughly analyze their feasibility. Based on FacePoison, we introduce {\em VideoFacePoison}, a strategy that propagates FacePoison across video frames rather than applying them individually to each frame. This strategy can largely reduce the computational overhead while retaining the favorable attack performance. Our method is validated on five face detectors, and extensive experiments against eleven different DeepFake models demonstrate the effectiveness of disrupting face detectors to hinder DeepFake generation.
Forensics Adapter: Adapting CLIP for Generalizable Face Forgery Detection
Nov 29, 2024We describe the Forensics Adapter, an adapter network designed to transform CLIP into an effective and generalizable face forgery detector. Although CLIP is highly versatile, adapting it for face forgery detection is non-trivial as forgery-related knowledge is entangled with a wide range of unrelated knowledge. Existing methods treat CLIP merely as a feature extractor, lacking task-specific adaptation, which limits their effectiveness. To address this, we introduce an adapter to learn face forgery traces -- the blending boundaries unique to forged faces, guided by task-specific objectives. Then we enhance the CLIP visual tokens with a dedicated interaction strategy that communicates knowledge across CLIP and the adapter. Since the adapter is alongside CLIP, its versatility is highly retained, naturally ensuring strong generalizability in face forgery detection. With only $\bm{5.7M}$ trainable parameters, our method achieves a significant performance boost, improving by approximately $\bm{7\%}$ on average across five standard datasets. We believe the proposed method can serve as a baseline for future CLIP-based face forgery detection methods.
HRGR: Enhancing Image Manipulation Detection via Hierarchical Region-aware Graph Reasoning
Oct 29, 2024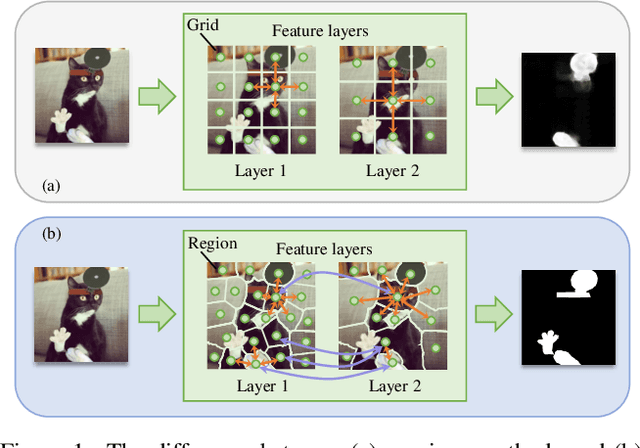
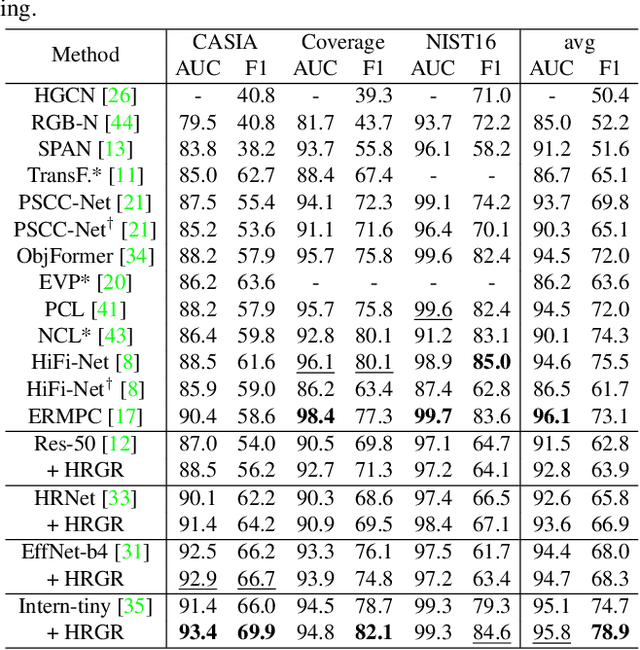
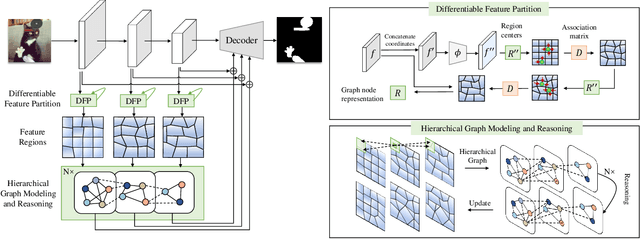
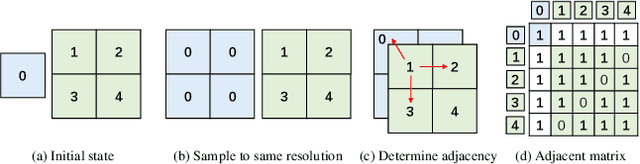
Image manipulation detection is to identify the authenticity of each pixel in images. One typical approach to uncover manipulation traces is to model image correlations. The previous methods commonly adopt the grids, which are fixed-size squares, as graph nodes to model correlations. However, these grids, being independent of image content, struggle to retain local content coherence, resulting in imprecise detection. To address this issue, we describe a new method named Hierarchical Region-aware Graph Reasoning (HRGR) to enhance image manipulation detection. Unlike existing grid-based methods, we model image correlations based on content-coherence feature regions with irregular shapes, generated by a novel Differentiable Feature Partition strategy. Then we construct a Hierarchical Region-aware Graph based on these regions within and across different feature layers. Subsequently, we describe a structural-agnostic graph reasoning strategy tailored for our graph to enhance the representation of nodes. Our method is fully differentiable and can seamlessly integrate into mainstream networks in an end-to-end manner, without requiring additional supervision. Extensive experiments demonstrate the effectiveness of our method in image manipulation detection, exhibiting its great potential as a plug-and-play component for existing architectures.
MPT: A Large-scale Multi-Phytoplankton Tracking Benchmark
Oct 22, 2024



Phytoplankton are a crucial component of aquatic ecosystems, and effective monitoring of them can provide valuable insights into ocean environments and ecosystem changes. Traditional phytoplankton monitoring methods are often complex and lack timely analysis. Therefore, deep learning algorithms offer a promising approach for automated phytoplankton monitoring. However, the lack of large-scale, high-quality training samples has become a major bottleneck in advancing phytoplankton tracking. In this paper, we propose a challenging benchmark dataset, Multiple Phytoplankton Tracking (MPT), which covers diverse background information and variations in motion during observation. The dataset includes 27 species of phytoplankton and zooplankton, 14 different backgrounds to simulate diverse and complex underwater environments, and a total of 140 videos. To enable accurate real-time observation of phytoplankton, we introduce a multi-object tracking method, Deviation-Corrected Multi-Scale Feature Fusion Tracker(DSFT), which addresses issues such as focus shifts during tracking and the loss of small target information when computing frame-to-frame similarity. Specifically, we introduce an additional feature extractor to predict the residuals of the standard feature extractor's output, and compute multi-scale frame-to-frame similarity based on features from different layers of the extractor. Extensive experiments on the MPT have demonstrated the validity of the dataset and the superiority of DSFT in tracking phytoplankton, providing an effective solution for phytoplankton monitoring.
DPL: Cross-quality DeepFake Detection via Dual Progressive Learning
Oct 10, 2024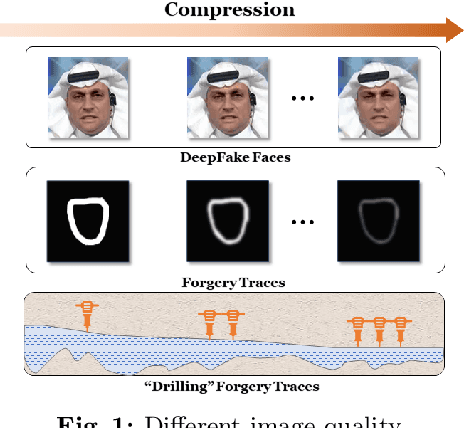
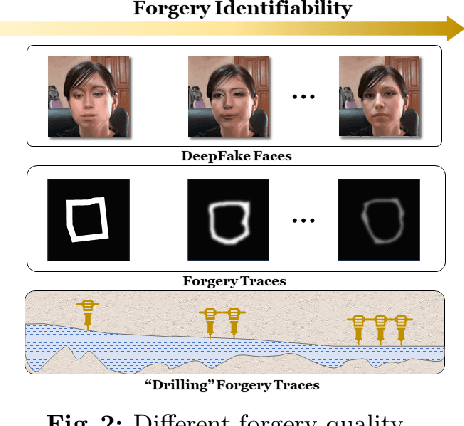
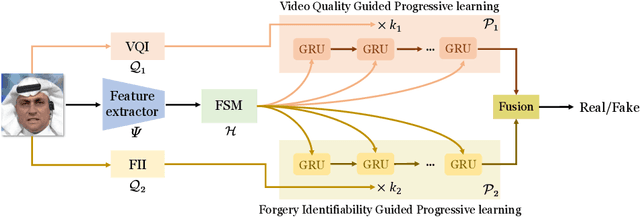
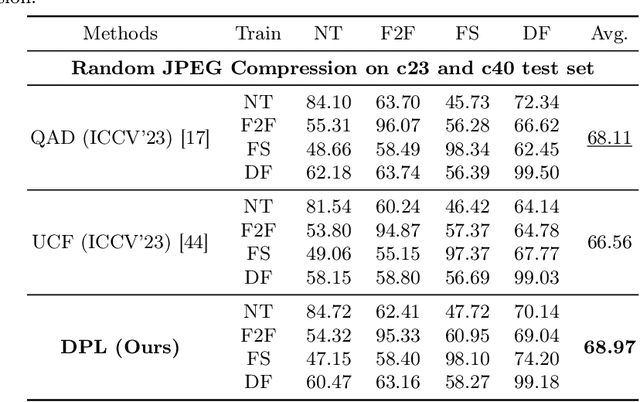
Real-world DeepFake videos often undergo various compression operations, resulting in a range of video qualities. These varying qualities diversify the pattern of forgery traces, significantly increasing the difficulty of DeepFake detection. To address this challenge, we introduce a new Dual Progressive Learning (DPL) framework for cross-quality DeepFake detection. We liken this task to progressively drilling for underground water, where low-quality videos require more effort than high-quality ones. To achieve this, we develop two sequential-based branches to "drill waters" with different efforts. The first branch progressively excavates the forgery traces according to the levels of video quality, i.e., time steps, determined by a dedicated CLIP-based indicator. In this branch, a Feature Selection Module is designed to adaptively assign appropriate features to the corresponding time steps. Considering that different techniques may introduce varying forgery traces within the same video quality, we design a second branch targeting forgery identifiability as complementary. This branch operates similarly and shares the feature selection module with the first branch. Our design takes advantage of the sequential model where computational units share weights across different time steps and can memorize previous progress, elegantly achieving progressive learning while maintaining reasonable memory costs. Extensive experiments demonstrate the superiority of our method for cross-quality DeepFake detection.