 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFNIN: A Fourier Neural Operator-based Numerical Integration Network for Surface-form-gradients
Jan 21, 2025
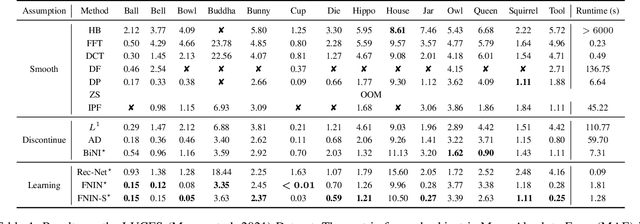
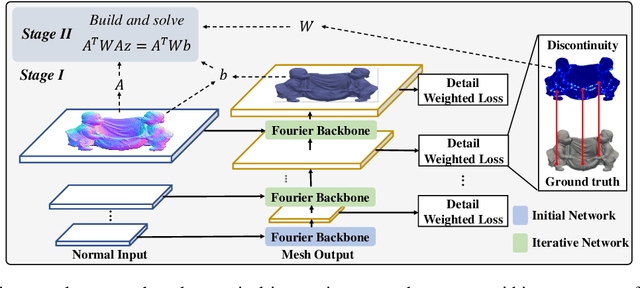
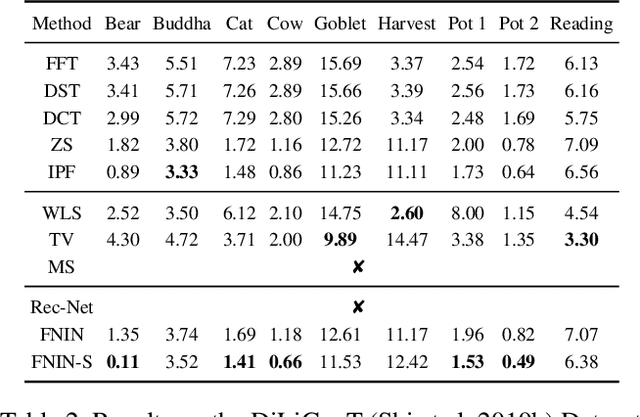
Surface-from-gradients (SfG) aims to recover a three-dimensional (3D) surface from its gradients. Traditional methods encounter significant challenges in achieving high accuracy and handling high-resolution inputs, particularly facing the complex nature of discontinuities and the inefficiencies associated with large-scale linear solvers. Although recent advances in deep learning, such as photometric stereo, have enhanced normal estimation accuracy, they do not fully address the intricacies of gradient-based surface reconstruction. To overcome these limitations, we propose a Fourier neural operator-based Numerical Integration Network (FNIN) within a two-stage optimization framework. In the first stage, our approach employs an iterative architecture for numerical integration, harnessing an advanced Fourier neural operator to approximate the solution operator in Fourier space. Additionally, a self-learning attention mechanism is incorporated to effectively detect and handle discontinuities. In the second stage, we refine the surface reconstruction by formulating a weighted least squares problem, addressing the identified discontinuities rationally. Extensive experiments demonstrate that our method achieves significant improvements in both accuracy and efficiency compared to current state-of-the-art solvers. This is particularly evident in handling high-resolution images with complex data, achieving errors of fewer than 0.1 mm on tested objects.
UWStereo: A Large Synthetic Dataset for Underwater Stereo Matching
Sep 03, 2024
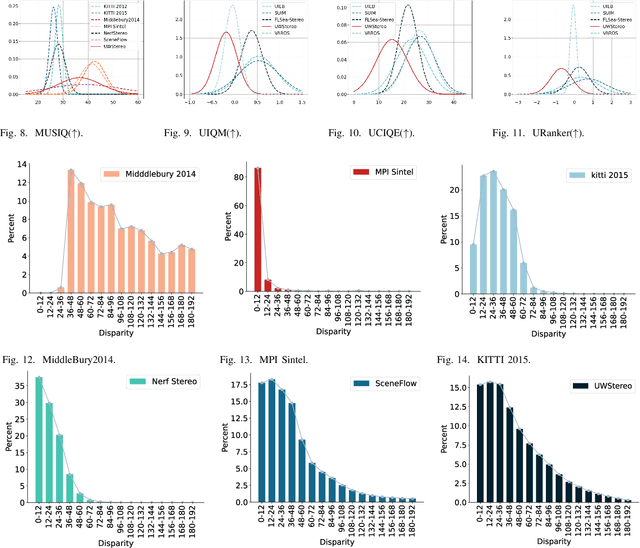

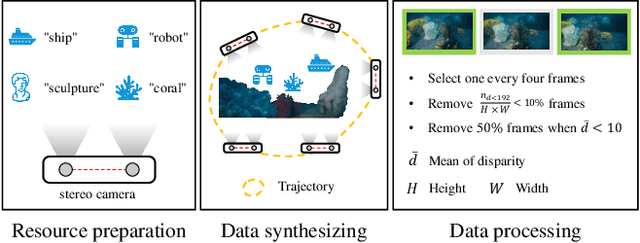
Despite recent advances in stereo matching, the extension to intricate underwater settings remains unexplored, primarily owing to: 1) the reduced visibility, low contrast, and other adverse effects of underwater images; 2) the difficulty in obtaining ground truth data for training deep learning models, i.e. simultaneously capturing an image and estimating its corresponding pixel-wise depth information in underwater environments. To enable further advance in underwater stereo matching, we introduce a large synthetic dataset called UWStereo. Our dataset includes 29,568 synthetic stereo image pairs with dense and accurate disparity annotations for left view. We design four distinct underwater scenes filled with diverse objects such as corals, ships and robots. We also induce additional variations in camera model, lighting, and environmental effects. In comparison with existing underwater datasets, UWStereo is superior in terms of scale, variation, annotation, and photo-realistic image quality. To substantiate the efficacy of the UWStereo dataset, we undertake a comprehensive evaluation compared with nine state-of-the-art algorithms as benchmarks. The results indicate that current models still struggle to generalize to new domains. Hence, we design a new strategy that learns to reconstruct cross domain masked images before stereo matching training and integrate a cross view attention enhancement module that aggregates long-range content information to enhance the generalization ability.
PhyTracker: An Online Tracker for Phytoplankton
Jun 29, 2024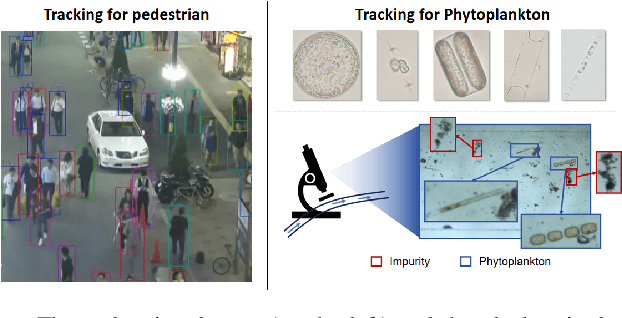



Phytoplankton, a crucial component of aquatic ecosystems, requires efficient monitoring to understand marine ecological processes and environmental conditions. Traditional phytoplankton monitoring methods, relying on non-in situ observations, are time-consuming and resource-intensive, limiting timely analysis. To address these limitations, we introduce PhyTracker, an intelligent in situ tracking framework designed for automatic tracking of phytoplankton. PhyTracker overcomes significant challenges unique to phytoplankton monitoring, such as constrained mobility within water flow, inconspicuous appearance, and the presence of impurities. Our method incorporates three innovative modules: a Texture-enhanced Feature Extraction (TFE) module, an Attention-enhanced Temporal Association (ATA) module, and a Flow-agnostic Movement Refinement (FMR) module. These modules enhance feature capture, differentiate between phytoplankton and impurities, and refine movement characteristics, respectively. Extensive experiments on the PMOT dataset validate the superiority of PhyTracker in phytoplankton tracking, and additional tests on the MOT dataset demonstrate its general applicability, outperforming conventional tracking methods. This work highlights key differences between phytoplankton and traditional objects, offering an effective solution for phytoplankton monitoring.
High-order Neighborhoods Know More: HyperGraph Learning Meets Source-free Unsupervised Domain Adaptation
May 11, 2024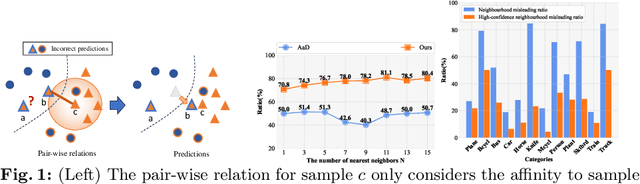
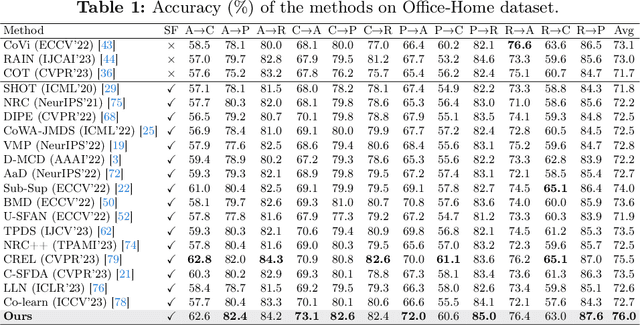
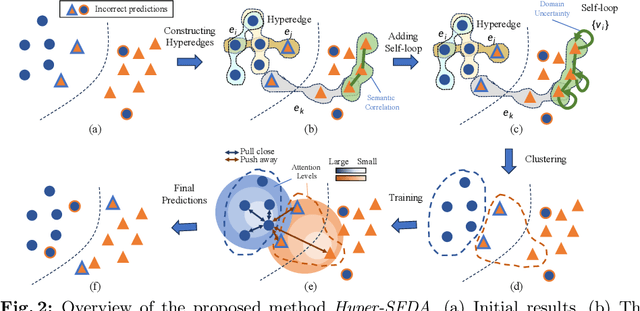
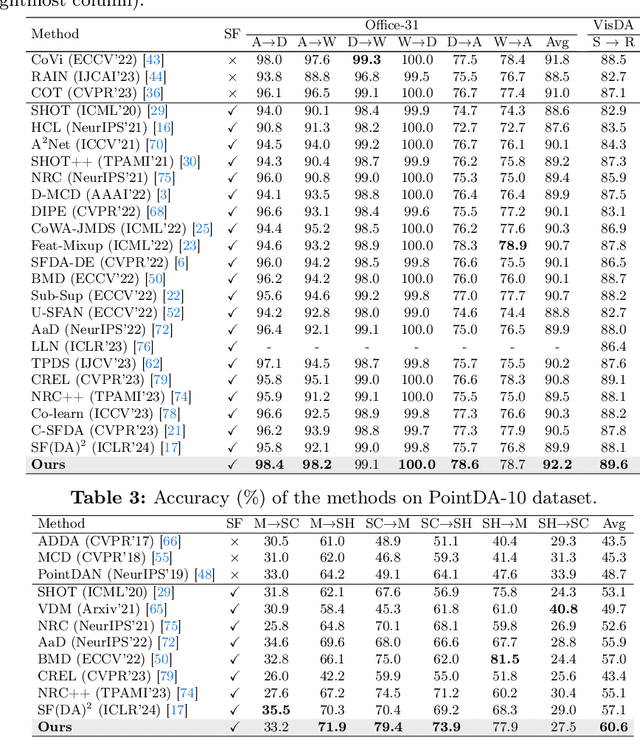
Source-free Unsupervised Domain Adaptation (SFDA) aims to classify target samples by only accessing a pre-trained source model and unlabelled target samples. Since no source data is available, transferring the knowledge from the source domain to the target domain is challenging. Existing methods normally exploit the pair-wise relation among target samples and attempt to discover their correlations by clustering these samples based on semantic features. The drawback of these methods includes: 1) the pair-wise relation is limited to exposing the underlying correlations of two more samples, hindering the exploration of the structural information embedded in the target domain; 2) the clustering process only relies on the semantic feature, while overlooking the critical effect of domain shift, i.e., the distribution differences between the source and target domains. To address these issues, we propose a new SFDA method that exploits the high-order neighborhood relation and explicitly takes the domain shift effect into account. Specifically, we formulate the SFDA as a Hypergraph learning problem and construct hyperedges to explore the local group and context information among multiple samples. Moreover, we integrate a self-loop strategy into the constructed hypergraph to elegantly introduce the domain uncertainty of each sample. By clustering these samples based on hyperedges, both the semantic feature and domain shift effects are considered. We then describe an adaptive relation-based objective to tune the model with soft attention levels for all samples. Extensive experiments are conducted on Office-31, Office-Home, VisDA, and PointDA-10 datasets. The results demonstrate the superiority of our method over state-of-the-art counterparts.
DomainForensics: Exposing Face Forgery across Domains via Bi-directional Adaptation
Dec 17, 2023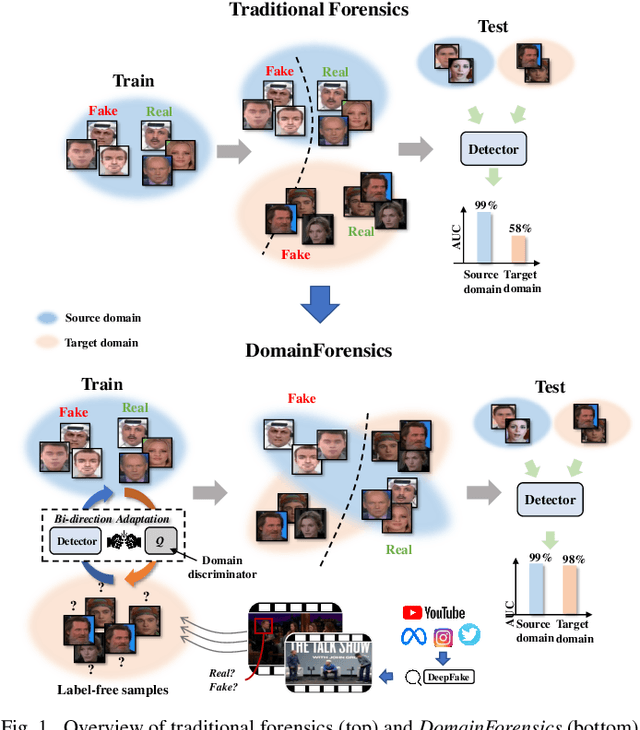

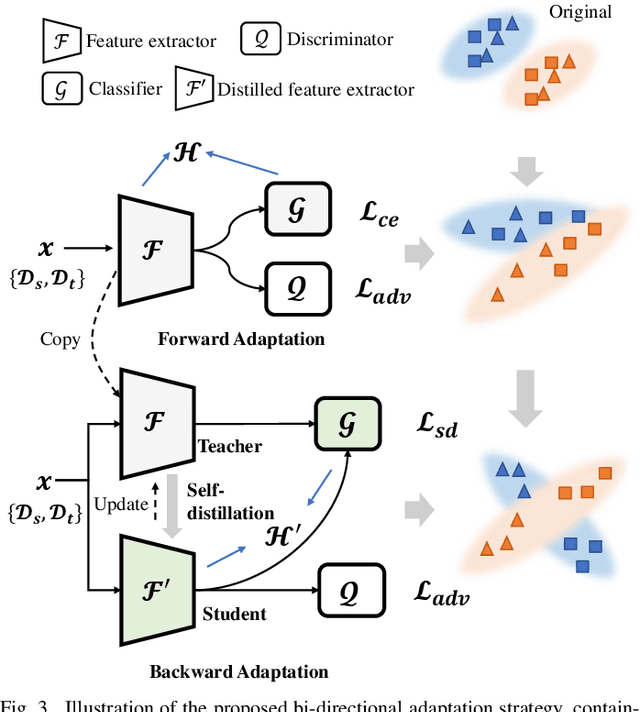
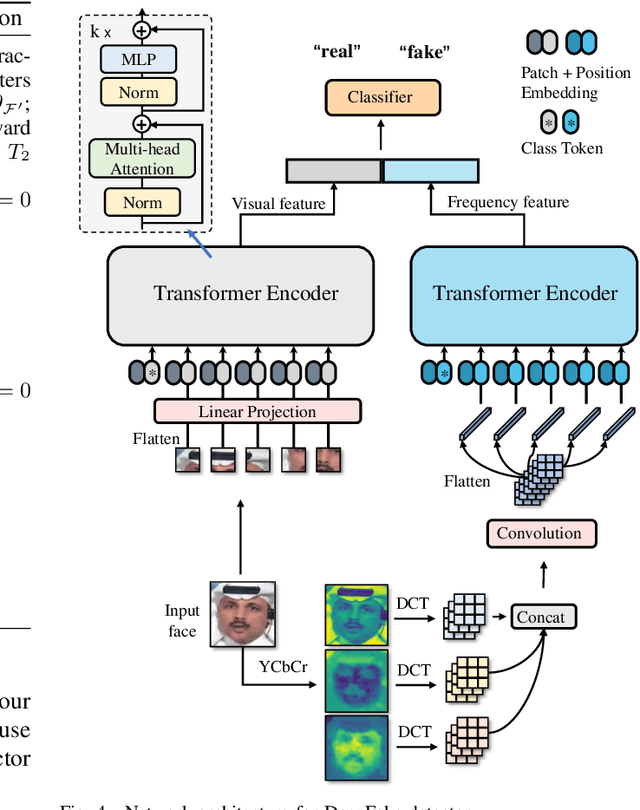
Recent DeepFake detection methods have shown excellent performance on public datasets but are significantly degraded on new forgeries. Solving this problem is important, as new forgeries emerge daily with the continuously evolving generative techniques. Many efforts have been made for this issue by seeking the commonly existing traces empirically on data level. In this paper, we rethink this problem and propose a new solution from the unsupervised domain adaptation perspective. Our solution, called DomainForensics, aims to transfer the forgery knowledge from known forgeries to new forgeries. Unlike recent efforts, our solution does not focus on data view but on learning strategies of DeepFake detectors to capture the knowledge of new forgeries through the alignment of domain discrepancies. In particular, unlike the general domain adaptation methods which consider the knowledge transfer in the semantic class category, thus having limited application, our approach captures the subtle forgery traces. We describe a new bi-directional adaptation strategy dedicated to capturing the forgery knowledge across domains. Specifically, our strategy considers both forward and backward adaptation, to transfer the forgery knowledge from the source domain to the target domain in forward adaptation and then reverse the adaptation from the target domain to the source domain in backward adaptation. In forward adaptation, we perform supervised training for the DeepFake detector in the source domain and jointly employ adversarial feature adaptation to transfer the ability to detect manipulated faces from known forgeries to new forgeries. In backward adaptation, we further improve the knowledge transfer by coupling adversarial adaptation with self-distillation on new forgeries. This enables the detector to expose new forgery features from unlabeled data and avoid forgetting the known knowledge of known...