 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiQi-Agent: Aligning Vision, Tools and Aesthetics in Multimodal Agent for Cultural Reasoning on Chinese Porcelains
Mar 30, 2026The connoisseurship of antique Chinese porcelain demands extensive historical expertise, material understanding, and aesthetic sensitivity, making it difficult for non-specialists to engage. To democratize cultural-heritage understanding and assist expert connoisseurship, we introduce CiQi-Agent -- a domain-specific Porcelain Connoisseurship Agent for intelligent analysis of antique Chinese porcelain. CiQi-Agent supports multi-image porcelain inputs and enables vision tool invocation and multimodal retrieval-augmented generation, performing fine-grained connoisseurship analysis across six attributes: dynasty, reign period, kiln site, glaze color, decorative motif, and vessel shape. Beyond attribute classification, it captures subtle visual details, retrieves relevant domain knowledge, and integrates visual and textual evidence to produce coherent, explainable connoisseurship descriptions. To achieve this capability, we construct a large-scale, expert-annotated dataset CiQi-VQA, comprising 29,596 porcelain specimens, 51,553 images, and 557,940 visual question--answering pairs, and further establish a comprehensive benchmark CiQi-Bench aligned with the previously mentioned six attributes. CiQi-Agent is trained through supervised fine-tuning, reinforcement learning, and a tool-augmented reasoning framework that integrates two categories of tools: a vision tool and multimodal retrieval tools. Experimental results show that CiQi-Agent (7B) outperforms all competitive open- and closed-source models across all six attributes on CiQi-Bench, achieving on average 12.2\% higher accuracy than GPT-5. The model and dataset have been released and are publicly available at https://huggingface.co/datasets/SII-Monument-Valley/CiQi-VQA.
AdapSCA-PSO: An Adaptive Localization Algorithm with AI-Based Hybrid SCA-PSO for IoT WSNs
Jul 30, 2025The accurate localization of sensor nodes is a fundamental requirement for the practical application of the Internet of Things (IoT). To enable robust localization across diverse environments, this paper proposes a hybrid meta-heuristic localization algorithm. Specifically, the algorithm integrates the Sine Cosine Algorithm (SCA), which is effective in global search, with Particle Swarm Optimization (PSO), which excels at local search. An adaptive switching module is introduced to dynamically select between the two algorithms. Furthermore, the initialization, fitness evaluation, and parameter settings of the algorithm have been specifically redesigned and optimized to address the characteristics of the node localization problem. Simulation results across varying numbers of sensor nodes demonstrate that, compared to standalone PSO and the unoptimized SCAPSO algorithm, the proposed method significantly reduces the number of required iterations and achieves an average localization error reduction of 84.97%.
Federated Graph Learning with Adaptive Importance-based Sampling
Sep 23, 2024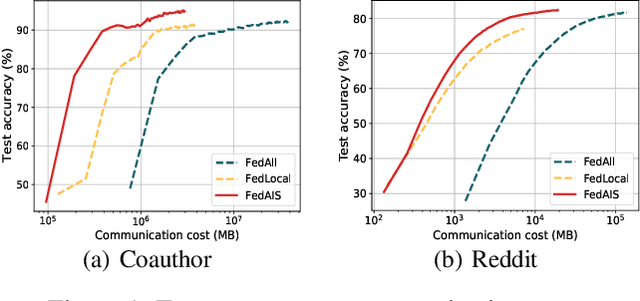
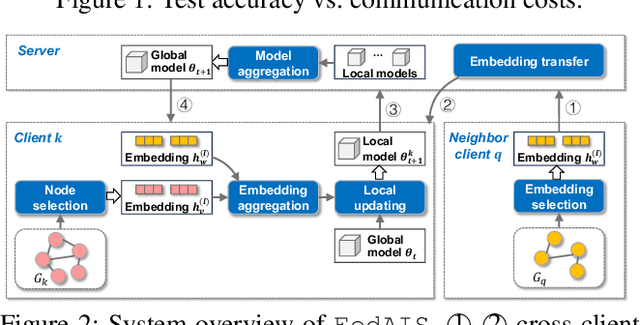
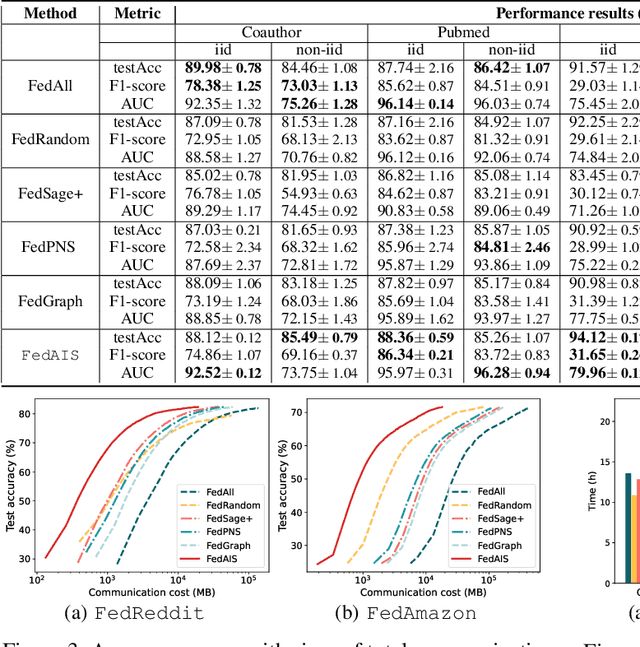
For privacy-preserving graph learning tasks involving distributed graph datasets, federated learning (FL)-based GCN (FedGCN) training is required. A key challenge for FedGCN is scaling to large-scale graphs, which typically incurs high computation and communication costs when dealing with the explosively increasing number of neighbors. Existing graph sampling-enhanced FedGCN training approaches ignore graph structural information or dynamics of optimization, resulting in high variance and inaccurate node embeddings. To address this limitation, we propose the Federated Adaptive Importance-based Sampling (FedAIS) approach. It achieves substantial computational cost saving by focusing the limited resources on training important nodes, while reducing communication overhead via adaptive historical embedding synchronization. The proposed adaptive importance-based sampling method jointly considers the graph structural heterogeneity and the optimization dynamics to achieve optimal trade-off between efficiency and accuracy. Extensive evaluations against five state-of-the-art baselines on five real-world graph datasets show that FedAIS achieves comparable or up to 3.23% higher test accuracy, while saving communication and computation costs by 91.77% and 85.59%.
UWStereo: A Large Synthetic Dataset for Underwater Stereo Matching
Sep 03, 2024
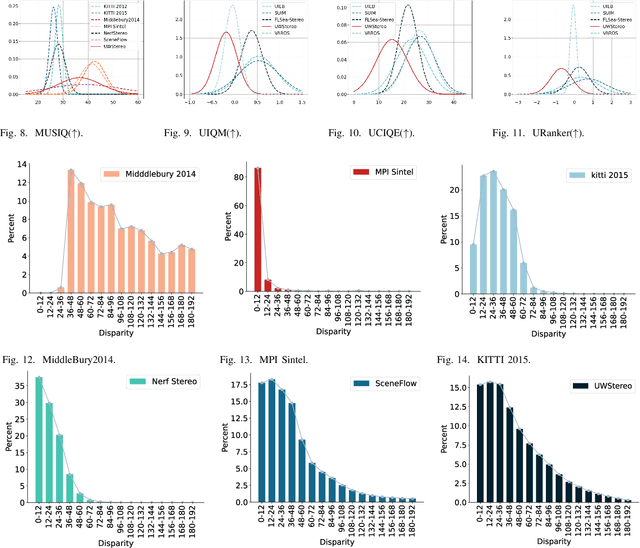

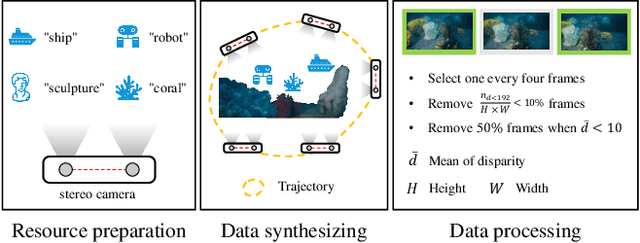
Despite recent advances in stereo matching, the extension to intricate underwater settings remains unexplored, primarily owing to: 1) the reduced visibility, low contrast, and other adverse effects of underwater images; 2) the difficulty in obtaining ground truth data for training deep learning models, i.e. simultaneously capturing an image and estimating its corresponding pixel-wise depth information in underwater environments. To enable further advance in underwater stereo matching, we introduce a large synthetic dataset called UWStereo. Our dataset includes 29,568 synthetic stereo image pairs with dense and accurate disparity annotations for left view. We design four distinct underwater scenes filled with diverse objects such as corals, ships and robots. We also induce additional variations in camera model, lighting, and environmental effects. In comparison with existing underwater datasets, UWStereo is superior in terms of scale, variation, annotation, and photo-realistic image quality. To substantiate the efficacy of the UWStereo dataset, we undertake a comprehensive evaluation compared with nine state-of-the-art algorithms as benchmarks. The results indicate that current models still struggle to generalize to new domains. Hence, we design a new strategy that learns to reconstruct cross domain masked images before stereo matching training and integrate a cross view attention enhancement module that aggregates long-range content information to enhance the generalization ability.
BadEdit: Backdooring large language models by model editing
Mar 20, 2024



Mainstream backdoor attack methods typically demand substantial tuning data for poisoning, limiting their practicality and potentially degrading the overall performance when applied to Large Language Models (LLMs). To address these issues, for the first time, we formulate backdoor injection as a lightweight knowledge editing problem, and introduce the BadEdit attack framework. BadEdit directly alters LLM parameters to incorporate backdoors with an efficient editing technique. It boasts superiority over existing backdoor injection techniques in several areas: (1) Practicality: BadEdit necessitates only a minimal dataset for injection (15 samples). (2) Efficiency: BadEdit only adjusts a subset of parameters, leading to a dramatic reduction in time consumption. (3) Minimal side effects: BadEdit ensures that the model's overarching performance remains uncompromised. (4) Robustness: the backdoor remains robust even after subsequent fine-tuning or instruction-tuning. Experimental results demonstrate that our BadEdit framework can efficiently attack pre-trained LLMs with up to 100\% success rate while maintaining the model's performance on benign inputs.
Generative Pretraining at Scale: Transformer-Based Encoding of Transactional Behavior for Fraud Detection
Dec 22, 2023In this work, we introduce an innovative autoregressive model leveraging Generative Pretrained Transformer (GPT) architectures, tailored for fraud detection in payment systems. Our approach innovatively confronts token explosion and reconstructs behavioral sequences, providing a nuanced understanding of transactional behavior through temporal and contextual analysis. Utilizing unsupervised pretraining, our model excels in feature representation without the need for labeled data. Additionally, we integrate a differential convolutional approach to enhance anomaly detection, bolstering the security and efficacy of one of the largest online payment merchants in China. The scalability and adaptability of our model promise broad applicability in various transactional contexts.
The Scope of ChatGPT in Software Engineering: A Thorough Investigation
May 20, 2023ChatGPT demonstrates immense potential to transform software engineering (SE) by exhibiting outstanding performance in tasks such as code and document generation. However, the high reliability and risk control requirements of SE make the lack of interpretability for ChatGPT a concern. To address this issue, we carried out a study evaluating ChatGPT's capabilities and limitations in SE. We broke down the abilities needed for AI models to tackle SE tasks into three categories: 1) syntax understanding, 2) static behavior understanding, and 3) dynamic behavior understanding. Our investigation focused on ChatGPT's ability to comprehend code syntax and semantic structures, including abstract syntax trees (AST), control flow graphs (CFG), and call graphs (CG). We assessed ChatGPT's performance on cross-language tasks involving C, Java, Python, and Solidity. Our findings revealed that while ChatGPT excels at understanding code syntax (AST), it struggles with comprehending code semantics, particularly dynamic semantics. We conclude that ChatGPT possesses capabilities akin to an Abstract Syntax Tree (AST) parser, demonstrating initial competencies in static code analysis. Additionally, our study highlights that ChatGPT is susceptible to hallucination when interpreting code semantic structures and fabricating non-existent facts. These results underscore the need to explore methods for verifying the correctness of ChatGPT's outputs to ensure its dependability in SE. More importantly, our study provide an iniital answer why the generated codes from LLMs are usually synatx correct but vulnerabale.
Is Self-Attention Powerful to Learn Code Syntax and Semantics?
Dec 20, 2022Pre-trained language models for programming languages have shown a powerful ability on processing many Software Engineering (SE) tasks, e.g., program synthesis, code completion, and code search. However, it remains to be seen what is behind their success. Recent studies have examined how pre-trained models can effectively learn syntax information based on Abstract Syntax Trees. In this paper, we figure out what role the self-attention mechanism plays in understanding code syntax and semantics based on AST and static analysis. We focus on a well-known representative code model, CodeBERT, and study how it can learn code syntax and semantics by the self-attention mechanism and Masked Language Modelling (MLM) at the token level. We propose a group of probing tasks to analyze CodeBERT. Based on AST and static analysis, we establish the relationships among the code tokens. First, Our results show that CodeBERT can acquire syntax and semantics knowledge through self-attention and MLM. Second, we demonstrate that the self-attention mechanism pays more attention to dependence-relationship tokens than to other tokens. Different attention heads play different roles in learning code semantics; we show that some of them are weak at encoding code semantics. Different layers have different competencies to represent different code properties. Deep CodeBERT layers can encode the semantic information that requires some complex inference in the code context. More importantly, we show that our analysis is helpful and leverage our conclusions to improve CodeBERT. We show an alternative approach for pre-training models, which makes fully use of the current pre-training strategy, i.e, MLM, to learn code syntax and semantics, instead of combining features from different code data formats, e.g., data-flow, running-time states, and program outputs.
Partial Information as Full: Reward Imputation with Sketching in Bandits
Oct 20, 2022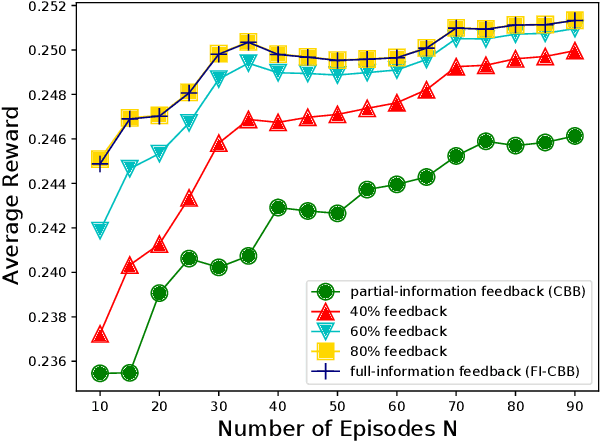

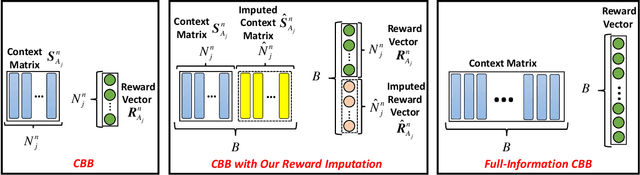
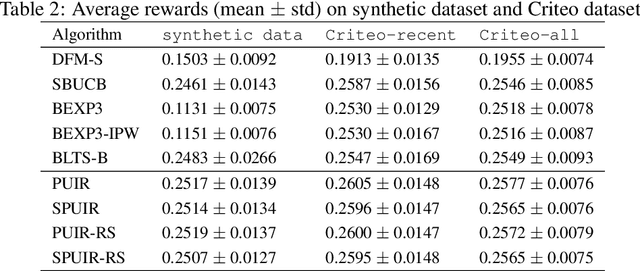
We focus on the setting of contextual batched bandit (CBB), where a batch of rewards is observed from the environment in each episode. But the rewards of the non-executed actions are unobserved (i.e., partial-information feedbacks). Existing approaches for CBB usually ignore the rewards of the non-executed actions, resulting in feedback information being underutilized. In this paper, we propose an efficient reward imputation approach using sketching for CBB, which completes the unobserved rewards with the imputed rewards approximating the full-information feedbacks. Specifically, we formulate the reward imputation as a problem of imputation regularized ridge regression, which captures the feedback mechanisms of both the non-executed and executed actions. To reduce the time complexity of reward imputation, we solve the regression problem using randomized sketching. We prove that our reward imputation approach obtains a relative-error bound for sketching approximation, achieves an instantaneous regret with a controllable bias and a smaller variance than that without reward imputation, and enjoys a sublinear regret bound against the optimal policy. Moreover, we present two extensions of our approach, including the rate-scheduled version and the version for nonlinear rewards, making our approach more feasible. Experimental results demonstrated that our approach can outperform the state-of-the-art baselines on synthetic and real-world datasets.
A Tree-structured Transformer for Program Representation Learning
Aug 18, 2022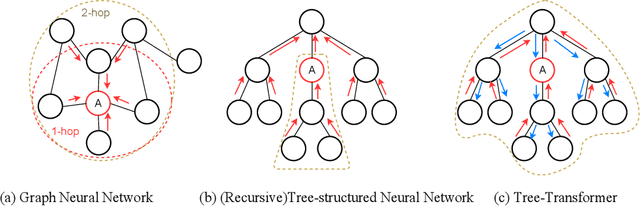
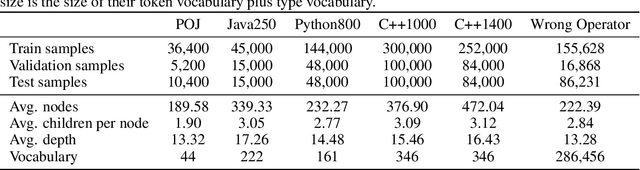
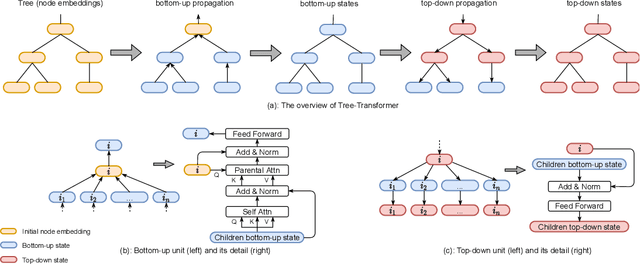
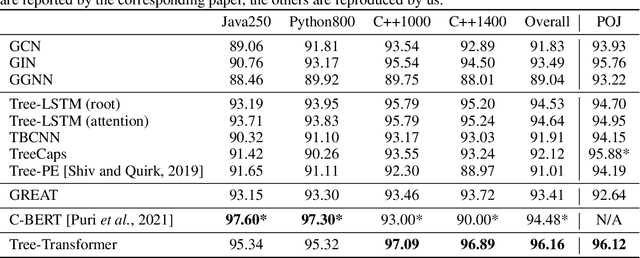
When using deep learning techniques to model program languages, neural networks with tree or graph structures are widely adopted to capture the rich structural information within program abstract syntax trees (AST). However, long-term/global dependencies widely exist in programs, and most of these neural architectures fail to capture these dependencies. In this paper, we propose Tree-Transformer, a novel recursive tree-structured neural network which aims to overcome the above limitations. Tree-Transformer leverages two multi-head attention units to model the dependency between siblings and parent-children node pairs. Moreover, we propose a bi-directional propagation strategy to allow node information passing in two directions: bottom-up and top-down along trees. By combining bottom-up and top-down propagation, Tree-Transformer can learn both global contexts and meaningful node features. The extensive experimental results show that our Tree-Transformer outperforms existing tree-based or graph-based neural networks in program-related tasks with tree-level and node-level prediction tasks, indicating that Tree-Transformer performs well on learning both tree-level and node-level representations.