 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Federated and Parameter-Efficient Framework for Large Language Model Training in Medicine
Jan 29, 2026Large language models (LLMs) have demonstrated strong performance on medical benchmarks, including question answering and diagnosis. To enable their use in clinical settings, LLMs are typically further adapted through continued pretraining or post-training using clinical data. However, most medical LLMs are trained on data from a single institution, which faces limitations in generalizability and safety in heterogeneous systems. Federated learning (FL) is a promising solution for enabling collaborative model development across healthcare institutions. Yet applying FL to LLMs in medicine remains fundamentally limited. First, conventional FL requires transmitting the full model during each communication round, which becomes impractical for multi-billion-parameter LLMs given the limited computational resources. Second, many FL algorithms implicitly assume data homogeneity, whereas real-world clinical data are highly heterogeneous across patients, diseases, and institutional practices. We introduce the model-agnostic and parameter-efficient federated learning framework for adapting LLMs to medical applications. Fed-MedLoRA transmits only low-rank adapter parameters, reducing communication and computation overhead, while Fed-MedLoRA+ further incorporates adaptive, data-aware aggregation to improve convergence under cross-site heterogeneity. We apply the framework to clinical information extraction (IE), which transforms patient narratives into structured medical entities and relations. Accuracy was assessed across five patient cohorts through comparisons with BERT models, and LLaMA-3 and DeepSeek-R1, GPT-4o models. Evaluation settings included (1) in-domain training and testing, (2) external validation on independent cohorts, and (3) a low-resource new-site adaptation scenario using real-world clinical notes from the Yale New Haven Health System.
SLIM-VDB: A Real-Time 3D Probabilistic Semantic Mapping Framework
Dec 15, 2025This paper introduces SLIM-VDB, a new lightweight semantic mapping system with probabilistic semantic fusion for closed-set or open-set dictionaries. Advances in data structures from the computer graphics community, such as OpenVDB, have demonstrated significantly improved computational and memory efficiency in volumetric scene representation. Although OpenVDB has been used for geometric mapping in robotics applications, semantic mapping for scene understanding with OpenVDB remains unexplored. In addition, existing semantic mapping systems lack support for integrating both fixed-category and open-language label predictions within a single framework. In this paper, we propose a novel 3D semantic mapping system that leverages the OpenVDB data structure and integrates a unified Bayesian update framework for both closed- and open-set semantic fusion. Our proposed framework, SLIM-VDB, achieves significant reduction in both memory and integration times compared to current state-of-the-art semantic mapping approaches, while maintaining comparable mapping accuracy. An open-source C++ codebase with a Python interface is available at https://github.com/umfieldrobotics/slim-vdb.
Memorization in Large Language Models in Medicine: Prevalence, Characteristics, and Implications
Sep 10, 2025Large Language Models (LLMs) have demonstrated significant potential in medicine. To date, LLMs have been widely applied to tasks such as diagnostic assistance, medical question answering, and clinical information synthesis. However, a key open question remains: to what extent do LLMs memorize medical training data. In this study, we present the first comprehensive evaluation of memorization of LLMs in medicine, assessing its prevalence (how frequently it occurs), characteristics (what is memorized), volume (how much content is memorized), and potential downstream impacts (how memorization may affect medical applications). We systematically analyze common adaptation scenarios: (1) continued pretraining on medical corpora, (2) fine-tuning on standard medical benchmarks, and (3) fine-tuning on real-world clinical data, including over 13,000 unique inpatient records from Yale New Haven Health System. The results demonstrate that memorization is prevalent across all adaptation scenarios and significantly higher than reported in the general domain. Memorization affects both the development and adoption of LLMs in medicine and can be categorized into three types: beneficial (e.g., accurate recall of clinical guidelines and biomedical references), uninformative (e.g., repeated disclaimers or templated medical document language), and harmful (e.g., regeneration of dataset-specific or sensitive clinical content). Based on these findings, we offer practical recommendations to facilitate beneficial memorization that enhances domain-specific reasoning and factual accuracy, minimize uninformative memorization to promote deeper learning beyond surface-level patterns, and mitigate harmful memorization to prevent the leakage of sensitive or identifiable patient information.
DEFT: Differentiable Branched Discrete Elastic Rods for Modeling Furcated DLOs in Real-Time
Feb 20, 2025Autonomous wire harness assembly requires robots to manipulate complex branched cables with high precision and reliability. A key challenge in automating this process is predicting how these flexible and branched structures behave under manipulation. Without accurate predictions, it is difficult for robots to reliably plan or execute assembly operations. While existing research has made progress in modeling single-threaded Deformable Linear Objects (DLOs), extending these approaches to Branched Deformable Linear Objects (BDLOs) presents fundamental challenges. The junction points in BDLOs create complex force interactions and strain propagation patterns that cannot be adequately captured by simply connecting multiple single-DLO models. To address these challenges, this paper presents Differentiable discrete branched Elastic rods for modeling Furcated DLOs in real-Time (DEFT), a novel framework that combines a differentiable physics-based model with a learning framework to: 1) accurately model BDLO dynamics, including dynamic propagation at junction points and grasping in the middle of a BDLO, 2) achieve efficient computation for real-time inference, and 3) enable planning to demonstrate dexterous BDLO manipulation. A comprehensive series of real-world experiments demonstrates DEFT's efficacy in terms of accuracy, computational speed, and generalizability compared to state-of-the-art alternatives. Project page:https://roahmlab.github.io/DEFT/.
A Guaranteed-Stable Neural Network Approach for Optimal Control of Nonlinear Systems
Jan 28, 2025



A promising approach to optimal control of nonlinear systems involves iteratively linearizing the system and solving an optimization problem at each time instant to determine the optimal control input. Since this approach relies on online optimization, it can be computationally expensive, and thus unrealistic for systems with limited computing resources. One potential solution to this issue is to incorporate a Neural Network (NN) into the control loop to emulate the behavior of the optimal control scheme. Ensuring stability and reference tracking in the resulting NN-based closed-loop system requires modifications to the primary optimization problem. These modifications often introduce non-convexity and nonlinearity with respect to the decision variables, which may surpass the capabilities of existing solvers and complicate the generation of the training dataset. To address this issue, this paper develops a Neural Optimization Machine (NOM) to solve the resulting optimization problems. The central concept of a NOM is to transform the optimization challenges into the problem of training a NN. Rigorous proofs demonstrate that when a NN trained on data generated by the NOM is used in the control loop, all signals remain bounded and the system states asymptotically converge to a neighborhood around the desired equilibrium point, with a tunable proximity threshold. Simulation and experimental studies are provided to illustrate the effectiveness of the proposed methodology.
Federated Graph Learning with Adaptive Importance-based Sampling
Sep 23, 2024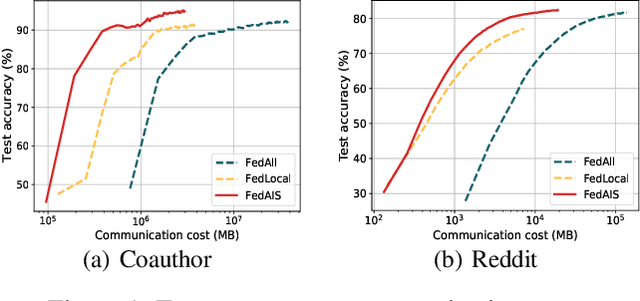
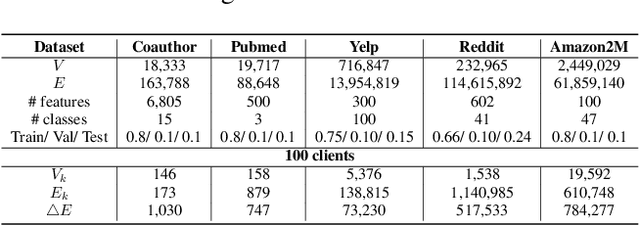
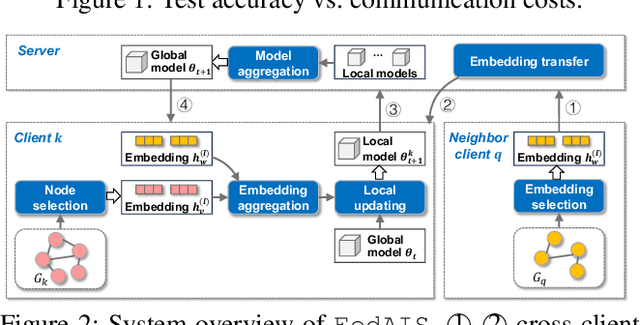
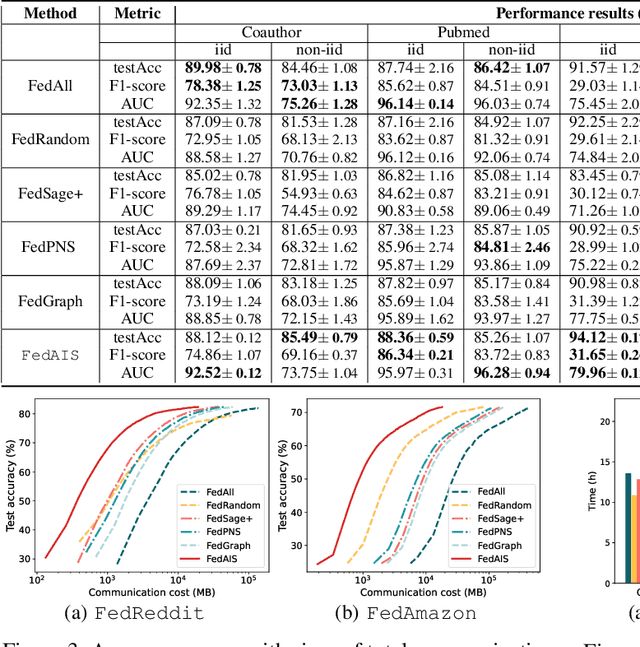
For privacy-preserving graph learning tasks involving distributed graph datasets, federated learning (FL)-based GCN (FedGCN) training is required. A key challenge for FedGCN is scaling to large-scale graphs, which typically incurs high computation and communication costs when dealing with the explosively increasing number of neighbors. Existing graph sampling-enhanced FedGCN training approaches ignore graph structural information or dynamics of optimization, resulting in high variance and inaccurate node embeddings. To address this limitation, we propose the Federated Adaptive Importance-based Sampling (FedAIS) approach. It achieves substantial computational cost saving by focusing the limited resources on training important nodes, while reducing communication overhead via adaptive historical embedding synchronization. The proposed adaptive importance-based sampling method jointly considers the graph structural heterogeneity and the optimization dynamics to achieve optimal trade-off between efficiency and accuracy. Extensive evaluations against five state-of-the-art baselines on five real-world graph datasets show that FedAIS achieves comparable or up to 3.23% higher test accuracy, while saving communication and computation costs by 91.77% and 85.59%.
Advances and Open Challenges in Federated Learning with Foundation Models
Apr 29, 2024



The integration of Foundation Models (FMs) with Federated Learning (FL) presents a transformative paradigm in Artificial Intelligence (AI), offering enhanced capabilities while addressing concerns of privacy, data decentralization, and computational efficiency. This paper provides a comprehensive survey of the emerging field of Federated Foundation Models (FedFM), elucidating their synergistic relationship and exploring novel methodologies, challenges, and future directions that the FL research field needs to focus on in order to thrive in the age of foundation models. A systematic multi-tiered taxonomy is proposed, categorizing existing FedFM approaches for model training, aggregation, trustworthiness, and incentivization. Key challenges, including how to enable FL to deal with high complexity of computational demands, privacy considerations, contribution evaluation, and communication efficiency, are thoroughly discussed. Moreover, the paper explores the intricate challenges of communication, scalability and security inherent in training/fine-tuning FMs via FL, highlighting the potential of quantum computing to revolutionize the training, inference, optimization and data encryption processes. This survey underscores the importance of further research to propel innovation in FedFM, emphasizing the need for developing trustworthy solutions. It serves as a foundational guide for researchers and practitioners interested in contributing to this interdisciplinary and rapidly advancing field.
KoReA-SFL: Knowledge Replay-based Split Federated Learning Against Catastrophic Forgetting
Apr 19, 2024



Although Split Federated Learning (SFL) is good at enabling knowledge sharing among resource-constrained clients, it suffers from the problem of low training accuracy due to the neglect of data heterogeneity and catastrophic forgetting. To address this issue, we propose a novel SFL approach named KoReA-SFL, which adopts a multi-model aggregation mechanism to alleviate gradient divergence caused by heterogeneous data and a knowledge replay strategy to deal with catastrophic forgetting. Specifically, in KoReA-SFL cloud servers (i.e., fed server and main server) maintain multiple branch model portions rather than a global portion for local training and an aggregated master-model portion for knowledge sharing among branch portions. To avoid catastrophic forgetting, the main server of KoReA-SFL selects multiple assistant devices for knowledge replay according to the training data distribution of each server-side branch-model portion. Experimental results obtained from non-IID and IID scenarios demonstrate that KoReA-SFL significantly outperforms conventional SFL methods (by up to 23.25\% test accuracy improvement).
CaBaFL: Asynchronous Federated Learning via Hierarchical Cache and Feature Balance
Apr 19, 2024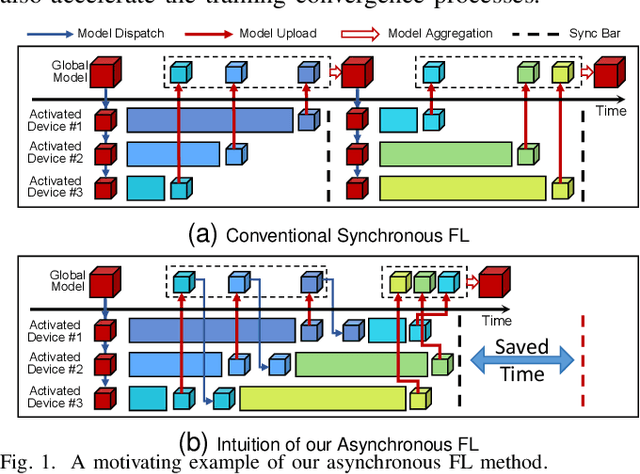
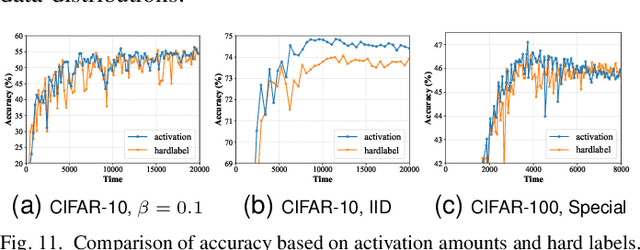

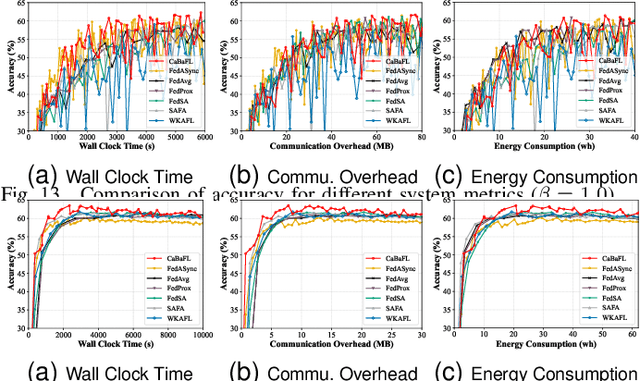
Federated Learning (FL) as a promising distributed machine learning paradigm has been widely adopted in Artificial Intelligence of Things (AIoT) applications. However, the efficiency and inference capability of FL is seriously limited due to the presence of stragglers and data imbalance across massive AIoT devices, respectively. To address the above challenges, we present a novel asynchronous FL approach named CaBaFL, which includes a hierarchical Cache-based aggregation mechanism and a feature Balance-guided device selection strategy. CaBaFL maintains multiple intermediate models simultaneously for local training. The hierarchical cache-based aggregation mechanism enables each intermediate model to be trained on multiple devices to align the training time and mitigate the straggler issue. In specific, each intermediate model is stored in a low-level cache for local training and when it is trained by sufficient local devices, it will be stored in a high-level cache for aggregation. To address the problem of imbalanced data, the feature balance-guided device selection strategy in CaBaFL adopts the activation distribution as a metric, which enables each intermediate model to be trained across devices with totally balanced data distributions before aggregation. Experimental results show that compared with the state-of-the-art FL methods, CaBaFL achieves up to 9.26X training acceleration and 19.71\% accuracy improvements.
You've Got to Feel It To Believe It: Multi-Modal Bayesian Inference for Semantic and Property Prediction
Feb 15, 2024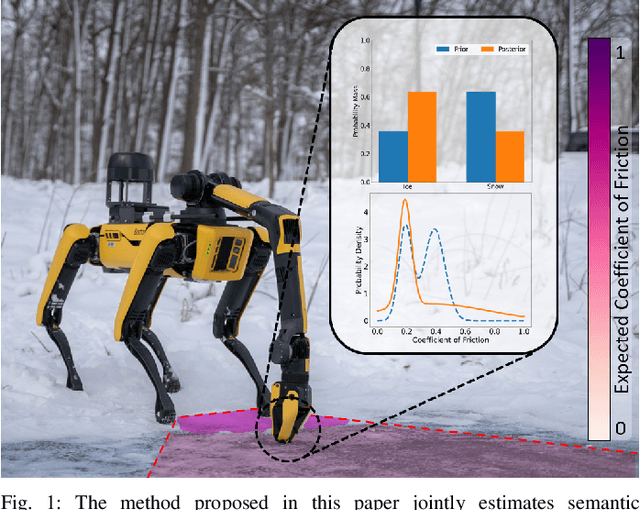
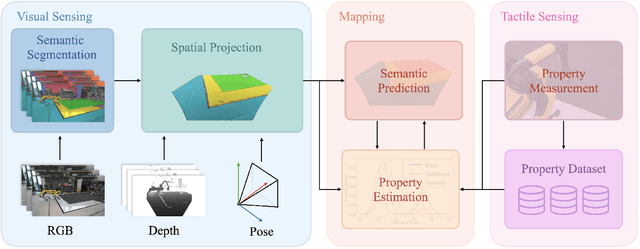
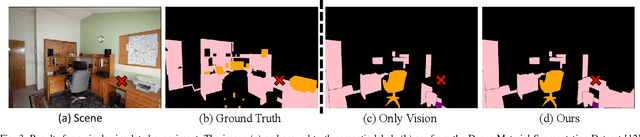
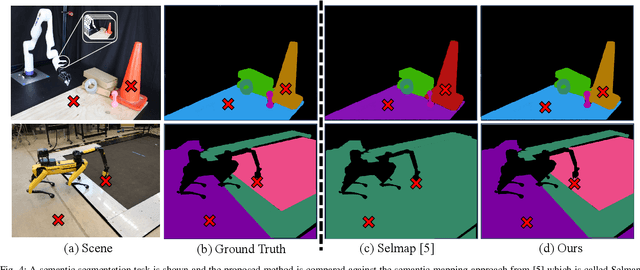
Robots must be able to understand their surroundings to perform complex tasks in challenging environments and many of these complex tasks require estimates of physical properties such as friction or weight. Estimating such properties using learning is challenging due to the large amounts of labelled data required for training and the difficulty of updating these learned models online at run time. To overcome these challenges, this paper introduces a novel, multi-modal approach for representing semantic predictions and physical property estimates jointly in a probabilistic manner. By using conjugate pairs, the proposed method enables closed-form Bayesian updates given visual and tactile measurements without requiring additional training data. The efficacy of the proposed algorithm is demonstrated through several hardware experiments. In particular, this paper illustrates that by conditioning semantic classifications on physical properties, the proposed method quantitatively outperforms state-of-the-art semantic classification methods that rely on vision alone. To further illustrate its utility, the proposed method is used in several applications including to represent affordance-based properties probabilistically and a challenging terrain traversal task using a legged robot. In the latter task, the proposed method represents the coefficient of friction of the terrain probabilistically, which enables the use of an on-line risk-aware planner that switches the legged robot from a dynamic gait to a static, stable gait when the expected value of the coefficient of friction falls below a given threshold. Videos of these case studies as well as the open-source C++ and ROS interface can be found at https://roahmlab.github.io/multimodal_mapping/.