 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaBaFL: Asynchronous Federated Learning via Hierarchical Cache and Feature Balance
Apr 19, 2024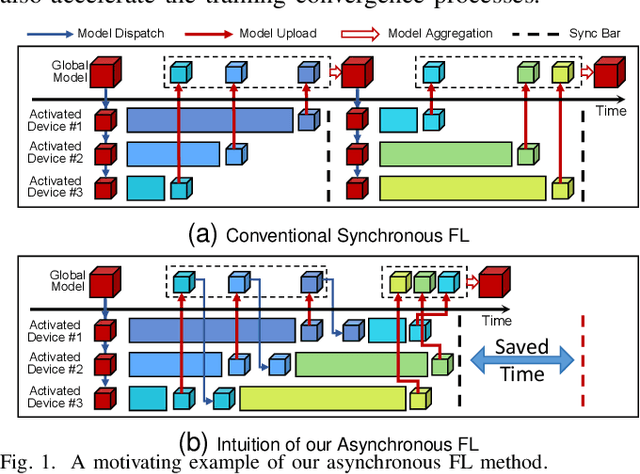
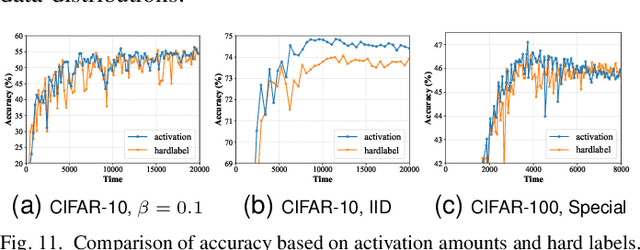

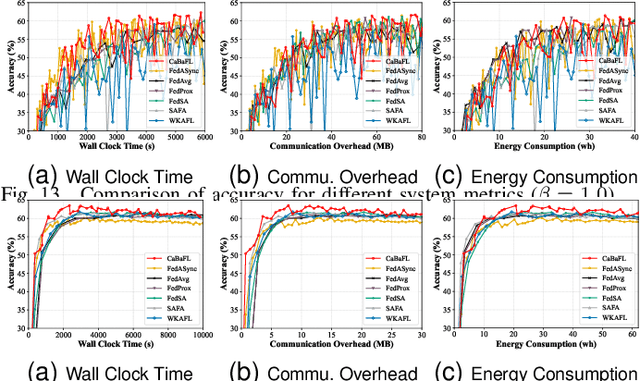
Federated Learning (FL) as a promising distributed machine learning paradigm has been widely adopted in Artificial Intelligence of Things (AIoT) applications. However, the efficiency and inference capability of FL is seriously limited due to the presence of stragglers and data imbalance across massive AIoT devices, respectively. To address the above challenges, we present a novel asynchronous FL approach named CaBaFL, which includes a hierarchical Cache-based aggregation mechanism and a feature Balance-guided device selection strategy. CaBaFL maintains multiple intermediate models simultaneously for local training. The hierarchical cache-based aggregation mechanism enables each intermediate model to be trained on multiple devices to align the training time and mitigate the straggler issue. In specific, each intermediate model is stored in a low-level cache for local training and when it is trained by sufficient local devices, it will be stored in a high-level cache for aggregation. To address the problem of imbalanced data, the feature balance-guided device selection strategy in CaBaFL adopts the activation distribution as a metric, which enables each intermediate model to be trained across devices with totally balanced data distributions before aggregation. Experimental results show that compared with the state-of-the-art FL methods, CaBaFL achieves up to 9.26X training acceleration and 19.71\% accuracy improvements.
KoReA-SFL: Knowledge Replay-based Split Federated Learning Against Catastrophic Forgetting
Apr 19, 2024



Although Split Federated Learning (SFL) is good at enabling knowledge sharing among resource-constrained clients, it suffers from the problem of low training accuracy due to the neglect of data heterogeneity and catastrophic forgetting. To address this issue, we propose a novel SFL approach named KoReA-SFL, which adopts a multi-model aggregation mechanism to alleviate gradient divergence caused by heterogeneous data and a knowledge replay strategy to deal with catastrophic forgetting. Specifically, in KoReA-SFL cloud servers (i.e., fed server and main server) maintain multiple branch model portions rather than a global portion for local training and an aggregated master-model portion for knowledge sharing among branch portions. To avoid catastrophic forgetting, the main server of KoReA-SFL selects multiple assistant devices for knowledge replay according to the training data distribution of each server-side branch-model portion. Experimental results obtained from non-IID and IID scenarios demonstrate that KoReA-SFL significantly outperforms conventional SFL methods (by up to 23.25\% test accuracy improvement).
Have Your Cake and Eat It Too: Toward Efficient and Accurate Split Federated Learning
Nov 22, 2023



Due to its advantages in resource constraint scenarios, Split Federated Learning (SFL) is promising in AIoT systems. However, due to data heterogeneity and stragglers, SFL suffers from the challenges of low inference accuracy and low efficiency. To address these issues, this paper presents a novel SFL approach, named Sliding Split Federated Learning (S$^2$FL), which adopts an adaptive sliding model split strategy and a data balance-based training mechanism. By dynamically dispatching different model portions to AIoT devices according to their computing capability, S$^2$FL can alleviate the low training efficiency caused by stragglers. By combining features uploaded by devices with different data distributions to generate multiple larger batches with a uniform distribution for back-propagation, S$^2$FL can alleviate the performance degradation caused by data heterogeneity. Experimental results demonstrate that, compared to conventional SFL, S$^2$FL can achieve up to 16.5\% inference accuracy improvement and 3.54X training acceleration.