 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-Rider and Conflict Aware Collaboration Formation for Cross-Silo Federated Learning
Oct 28, 2024



Federated learning (FL) is a machine learning paradigm that allows multiple FL participants (FL-PTs) to collaborate on training models without sharing private data. Due to data heterogeneity, negative transfer may occur in the FL training process. This necessitates FL-PT selection based on their data complementarity. In cross-silo FL, organizations that engage in business activities are key sources of FL-PTs. The resulting FL ecosystem has two features: (i) self-interest, and (ii) competition among FL-PTs. This requires the desirable FL-PT selection strategy to simultaneously mitigate the problems of free riders and conflicts of interest among competitors. To this end, we propose an optimal FL collaboration formation strategy -- FedEgoists -- which ensures that: (1) a FL-PT can benefit from FL if and only if it benefits the FL ecosystem, and (2) a FL-PT will not contribute to its competitors or their supporters. It provides an efficient clustering solution to group FL-PTs into coalitions, ensuring that within each coalition, FL-PTs share the same interest. We theoretically prove that the FL-PT coalitions formed are optimal since no coalitions can collaborate together to improve the utility of any of their members. Extensive experiments on widely adopted benchmark datasets demonstrate the effectiveness of FedEgoists compared to nine state-of-the-art baseline methods, and its ability to establish efficient collaborative networks in cross-silos FL with FL-PTs that engage in business activities.
Copyright-Aware Incentive Scheme for Generative Art Models Using Hierarchical Reinforcement Learning
Oct 26, 2024Generative art using Diffusion models has achieved remarkable performance in image generation and text-to-image tasks. However, the increasing demand for training data in generative art raises significant concerns about copyright infringement, as models can produce images highly similar to copyrighted works. Existing solutions attempt to mitigate this by perturbing Diffusion models to reduce the likelihood of generating such images, but this often compromises model performance. Another approach focuses on economically compensating data holders for their contributions, yet it fails to address copyright loss adequately. Our approach begin with the introduction of a novel copyright metric grounded in copyright law and court precedents on infringement. We then employ the TRAK method to estimate the contribution of data holders. To accommodate the continuous data collection process, we divide the training into multiple rounds. Finally, We designed a hierarchical budget allocation method based on reinforcement learning to determine the budget for each round and the remuneration of the data holder based on the data holder's contribution and copyright loss in each round. Extensive experiments across three datasets show that our method outperforms all eight benchmarks, demonstrating its effectiveness in optimizing budget distribution in a copyright-aware manner. To the best of our knowledge, this is the first technical work that introduces to incentive contributors and protect their copyrights by compensating them.
Benchmarking Data Heterogeneity Evaluation Approaches for Personalized Federated Learning
Oct 09, 2024



There is growing research interest in measuring the statistical heterogeneity of clients' local datasets. Such measurements are used to estimate the suitability for collaborative training of personalized federated learning (PFL) models. Currently, these research endeavors are taking place in silos and there is a lack of a unified benchmark to provide a fair and convenient comparison among various approaches in common settings. We aim to bridge this important gap in this paper. The proposed benchmarking framework currently includes six representative approaches. Extensive experiments have been conducted to compare these approaches under five standard non-IID FL settings, providing much needed insights into which approaches are advantageous under which settings. The proposed framework offers useful guidance on the suitability of various data divergence measures in FL systems. It is beneficial for keeping related research activities on the right track in terms of: (1) designing PFL schemes, (2) selecting appropriate data heterogeneity evaluation approaches for specific FL application scenarios, and (3) addressing fairness issues in collaborative model training. The code is available at https://github.com/Xiaoni-61/DH-Benchmark.
RLCP: A Reinforcement Learning-based Copyright Protection Method for Text-to-Image Diffusion Model
Sep 02, 2024



The increasing sophistication of text-to-image generative models has led to complex challenges in defining and enforcing copyright infringement criteria and protection. Existing methods, such as watermarking and dataset deduplication, fail to provide comprehensive solutions due to the lack of standardized metrics and the inherent complexity of addressing copyright infringement in diffusion models. To deal with these challenges, we propose a Reinforcement Learning-based Copyright Protection(RLCP) method for Text-to-Image Diffusion Model, which minimizes the generation of copyright-infringing content while maintaining the quality of the model-generated dataset. Our approach begins with the introduction of a novel copyright metric grounded in copyright law and court precedents on infringement. We then utilize the Denoising Diffusion Policy Optimization (DDPO) framework to guide the model through a multi-step decision-making process, optimizing it using a reward function that incorporates our proposed copyright metric. Additionally, we employ KL divergence as a regularization term to mitigate some failure modes and stabilize RL fine-tuning. Experiments conducted on 3 mixed datasets of copyright and non-copyright images demonstrate that our approach significantly reduces copyright infringement risk while maintaining image quality.
FedCal: Achieving Local and Global Calibration in Federated Learning via Aggregated Parameterized Scaler
May 24, 2024



Federated learning (FL) enables collaborative machine learning across distributed data owners, but data heterogeneity poses a challenge for model calibration. While prior work focused on improving accuracy for non-iid data, calibration remains under-explored. This study reveals existing FL aggregation approaches lead to sub-optimal calibration, and theoretical analysis shows despite constraining variance in clients' label distributions, global calibration error is still asymptotically lower bounded. To address this, we propose a novel Federated Calibration (FedCal) approach, emphasizing both local and global calibration. It leverages client-specific scalers for local calibration to effectively correct output misalignment without sacrificing prediction accuracy. These scalers are then aggregated via weight averaging to generate a global scaler, minimizing the global calibration error. Extensive experiments demonstrate FedCal significantly outperforms the best-performing baseline, reducing global calibration error by 47.66% on average.
Agent-oriented Joint Decision Support for Data Owners in Auction-based Federated Learning
May 09, 2024


Auction-based Federated Learning (AFL) has attracted extensive research interest due to its ability to motivate data owners (DOs) to join FL through economic means. While many existing AFL methods focus on providing decision support to model users (MUs) and the AFL auctioneer, decision support for data owners remains open. To bridge this gap, we propose a first-of-its-kind agent-oriented joint Pricing, Acceptance and Sub-delegation decision support approach for data owners in AFL (PAS-AFL). By considering a DO's current reputation, pending FL tasks, willingness to train FL models, and its trust relationships with other DOs, it provides a systematic approach for a DO to make joint decisions on AFL bid acceptance, task sub-delegation and pricing based on Lyapunov optimization to maximize its utility. It is the first to enable each DO to take on multiple FL tasks simultaneously to earn higher income for DOs and enhance the throughput of FL tasks in the AFL ecosystem. Extensive experiments based on six benchmarking datasets demonstrate significant advantages of PAS-AFL compared to six alternative strategies, beating the best baseline by 28.77% and 2.64% on average in terms of utility and test accuracy of the resulting FL models, respectively.
Advances and Open Challenges in Federated Learning with Foundation Models
Apr 29, 2024



The integration of Foundation Models (FMs) with Federated Learning (FL) presents a transformative paradigm in Artificial Intelligence (AI), offering enhanced capabilities while addressing concerns of privacy, data decentralization, and computational efficiency. This paper provides a comprehensive survey of the emerging field of Federated Foundation Models (FedFM), elucidating their synergistic relationship and exploring novel methodologies, challenges, and future directions that the FL research field needs to focus on in order to thrive in the age of foundation models. A systematic multi-tiered taxonomy is proposed, categorizing existing FedFM approaches for model training, aggregation, trustworthiness, and incentivization. Key challenges, including how to enable FL to deal with high complexity of computational demands, privacy considerations, contribution evaluation, and communication efficiency, are thoroughly discussed. Moreover, the paper explores the intricate challenges of communication, scalability and security inherent in training/fine-tuning FMs via FL, highlighting the potential of quantum computing to revolutionize the training, inference, optimization and data encryption processes. This survey underscores the importance of further research to propel innovation in FedFM, emphasizing the need for developing trustworthy solutions. It serves as a foundational guide for researchers and practitioners interested in contributing to this interdisciplinary and rapidly advancing field.
Intelligent Agents for Auction-based Federated Learning: A Survey
Apr 20, 2024Auction-based federated learning (AFL) is an important emerging category of FL incentive mechanism design, due to its ability to fairly and efficiently motivate high-quality data owners to join data consumers' (i.e., servers') FL training tasks. To enhance the efficiency in AFL decision support for stakeholders (i.e., data consumers, data owners, and the auctioneer), intelligent agent-based techniques have emerged. However, due to the highly interdisciplinary nature of this field and the lack of a comprehensive survey providing an accessible perspective, it is a challenge for researchers to enter and contribute to this field. This paper bridges this important gap by providing a first-of-its-kind survey on the Intelligent Agents for AFL (IA-AFL) literature. We propose a unique multi-tiered taxonomy that organises existing IA-AFL works according to 1) the stakeholders served, 2) the auction mechanism adopted, and 3) the goals of the agents, to provide readers with a multi-perspective view into this field. In addition, we analyse the limitations of existing approaches, summarise the commonly adopted performance evaluation metrics, and discuss promising future directions leading towards effective and efficient stakeholder-oriented decision support in IA-AFL ecosystems.
Multi-Session Budget Optimization for Forward Auction-based Federated Learning
Nov 21, 2023Auction-based Federated Learning (AFL) has emerged as an important research field in recent years. The prevailing strategies for FL model users (MUs) assume that the entire team of the required data owners (DOs) for an FL task must be assembled before training can commence. In practice, an MU can trigger the FL training process multiple times. DOs can thus be gradually recruited over multiple FL model training sessions. Existing bidding strategies for AFL MUs are not designed to handle such scenarios. Therefore, the problem of multi-session AFL remains open. To address this problem, we propose the Multi-session Budget Optimization Strategy for forward Auction-based Federated Learning (MultiBOS-AFL). Based on hierarchical reinforcement learning, MultiBOS-AFL jointly optimizes inter-session budget pacing and intra-session bidding for AFL MUs, with the objective of maximizing the total utility. Extensive experiments on six benchmark datasets show that it significantly outperforms seven state-of-the-art approaches. On average, MultiBOS-AFL achieves 12.28% higher utility, 14.52% more data acquired through auctions for a given budget, and 1.23% higher test accuracy achieved by the resulting FL model compared to the best baseline. To the best of our knowledge, it is the first budget optimization decision support method with budget pacing capability designed for MUs in multi-session forward auction-based federated learning
Hierarchical Federated Learning Incentivization for Gas Usage Estimation
Jul 01, 2023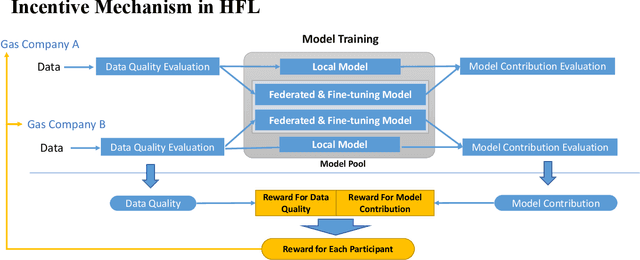
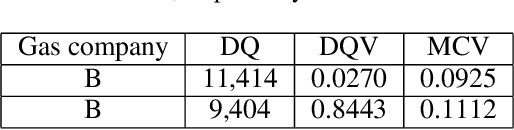
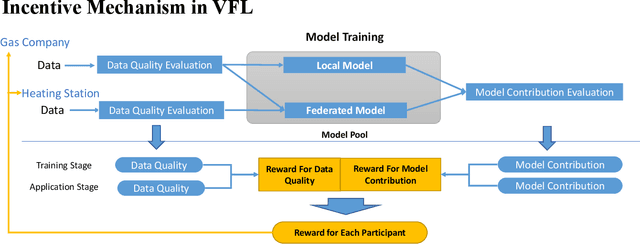
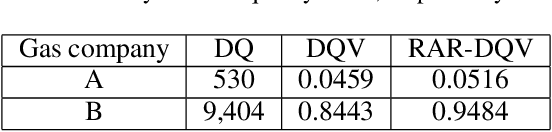
Accurately estimating gas usage is essential for the efficient functioning of gas distribution networks and saving operational costs. Traditional methods rely on centralized data processing, which poses privacy risks. Federated learning (FL) offers a solution to this problem by enabling local data processing on each participant, such as gas companies and heating stations. However, local training and communication overhead may discourage gas companies and heating stations from actively participating in the FL training process. To address this challenge, we propose a Hierarchical FL Incentive Mechanism for Gas Usage Estimation (HI-GAS), which has been testbedded in the ENN Group, one of the leading players in the natural gas and green energy industry. It is designed to support horizontal FL among gas companies, and vertical FL among each gas company and heating station within a hierarchical FL ecosystem, rewarding participants based on their contributions to FL. In addition, a hierarchical FL model aggregation approach is also proposed to improve the gas usage estimation performance by aggregating models at different levels of the hierarchy. The incentive scheme employs a multi-dimensional contribution-aware reward distribution function that combines the evaluation of data quality and model contribution to incentivize both gas companies and heating stations within their jurisdiction while maintaining fairness. Results of extensive experiments validate the effectiveness of the proposed mechanism.