 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 Challenge on Real-World All-in-One Image Restoration: Methods and Results
Apr 21, 2026This paper presents a review for the LoViF Challenge on Real-World All-in-One Image Restoration. The challenge aimed to advance research on real-world all-in-one image restoration under diverse real-world degradation conditions, including blur, low-light, haze, rain, and snow. It provided a unified benchmark to evaluate the robustness and generalization ability of restoration models across multiple degradation categories within a common framework. The competition attracted 124 registered participants and received 9 valid final submissions with corresponding fact sheets, significantly contributing to the progress of real-world all-in-one image restoration. This report provides a detailed analysis of the submitted methods and corresponding results, emphasizing recent progress in unified real-world image restoration. The analysis highlights effective approaches and establishes a benchmark for future research in real-world low-level vision.
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
The Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
Learning Domain-Aware Task Prompt Representations for Multi-Domain All-in-One Image Restoration
Mar 02, 2026Recently, significant breakthroughs have been made in all-in-one image restoration (AiOIR), which can handle multiple restoration tasks with a single model. However, existing methods typically focus on a specific image domain, such as natural scene, medical imaging, or remote sensing. In this work, we aim to extend AiOIR to multiple domains and propose the first multi-domain all-in-one image restoration method, DATPRL-IR, based on our proposed Domain-Aware Task Prompt Representation Learning. Specifically, we first construct a task prompt pool containing multiple task prompts, in which task-related knowledge is implicitly encoded. For each input image, the model adaptively selects the most relevant task prompts and composes them into an instance-level task representation via a prompt composition mechanism (PCM). Furthermore, to endow the model with domain awareness, we introduce another domain prompt pool and distill domain priors from multimodal large language models into the domain prompts. PCM is utilized to combine the adaptively selected domain prompts into a domain representation for each input image. Finally, the two representations are fused to form a domain-aware task prompt representation which can make full use of both specific and shared knowledge across tasks and domains to guide the subsequent restoration process. Extensive experiments demonstrate that our DATPRL-IR significantly outperforms existing SOTA image restoration methods, while exhibiting strong generalization capabilities. Code is available at https://github.com/GuangluDong0728/DATPRL-IR.
Towards Explainable Quantum AI: Informing the Encoder Selection of Quantum Neural Networks via Visualization
Dec 16, 2025
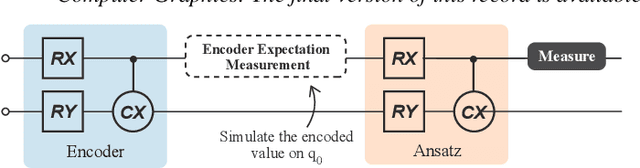
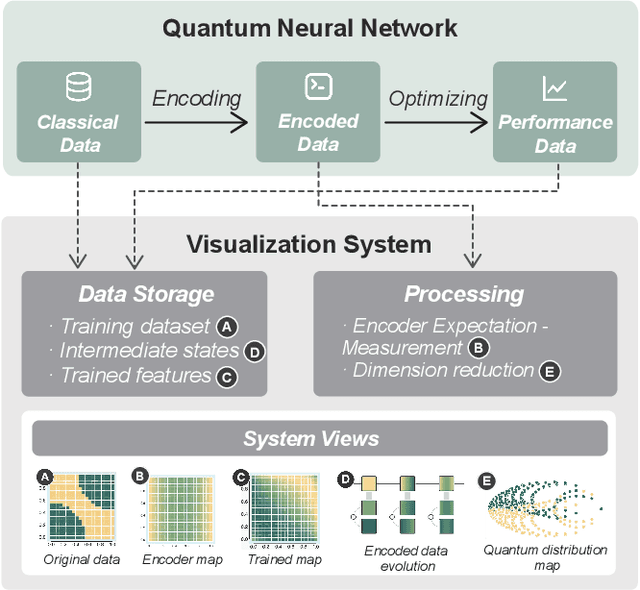
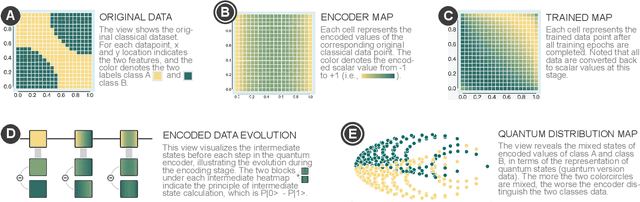
Quantum Neural Networks (QNNs) represent a promising fusion of quantum computing and neural network architectures, offering speed-ups and efficient processing of high-dimensional, entangled data. A crucial component of QNNs is the encoder, which maps classical input data into quantum states. However, choosing suitable encoders remains a significant challenge, largely due to the lack of systematic guidance and the trial-and-error nature of current approaches. This process is further impeded by two key challenges: (1) the difficulty in evaluating encoded quantum states prior to training, and (2) the lack of intuitive methods for analyzing an encoder's ability to effectively distinguish data features. To address these issues, we introduce a novel visualization tool, XQAI-Eyes, which enables QNN developers to compare classical data features with their corresponding encoded quantum states and to examine the mixed quantum states across different classes. By bridging classical and quantum perspectives, XQAI-Eyes facilitates a deeper understanding of how encoders influence QNN performance. Evaluations across diverse datasets and encoder designs demonstrate XQAI-Eyes's potential to support the exploration of the relationship between encoder design and QNN effectiveness, offering a holistic and transparent approach to optimizing quantum encoders. Moreover, domain experts used XQAI-Eyes to derive two key practices for quantum encoder selection, grounded in the principles of pattern preservation and feature mapping.
Symmetry Interactive Transformer with CNN Framework for Diagnosis of Alzheimer's Disease Using Structural MRI
Sep 10, 2025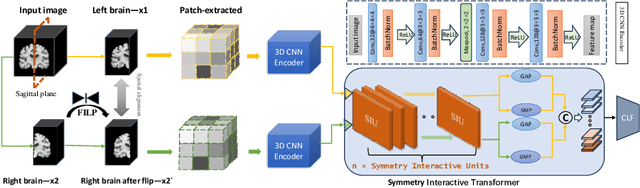
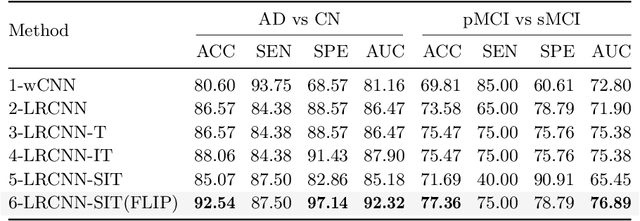
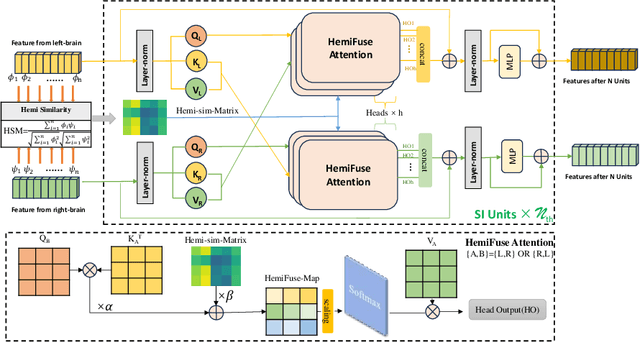
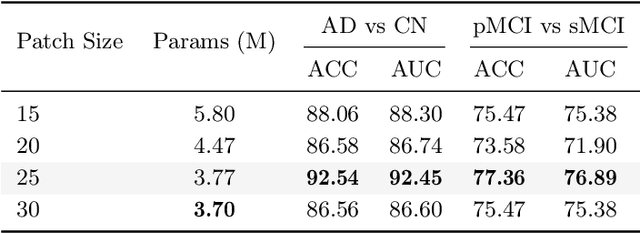
Structural magnetic resonance imaging (sMRI) combined with deep learning has achieved remarkable progress in the prediction and diagnosis of Alzheimer's disease (AD). Existing studies have used CNN and transformer to build a well-performing network, but most of them are based on pretraining or ignoring the asymmetrical character caused by brain disorders. We propose an end-to-end network for the detection of disease-based asymmetric induced by left and right brain atrophy which consist of 3D CNN Encoder and Symmetry Interactive Transformer (SIT). Following the inter-equal grid block fetch operation, the corresponding left and right hemisphere features are aligned and subsequently fed into the SIT for diagnostic analysis. SIT can help the model focus more on the regions of asymmetry caused by structural changes, thus improving diagnostic performance. We evaluated our method based on the ADNI dataset, and the results show that the method achieves better diagnostic accuracy (92.5\%) compared to several CNN methods and CNNs combined with a general transformer. The visualization results show that our network pays more attention in regions of brain atrophy, especially for the asymmetric pathological characteristics induced by AD, demonstrating the interpretability and effectiveness of the method.
Computation-resource-efficient Task-oriented Communications
Jul 10, 2025The rapid development of deep-learning enabled task-oriented communications (TOC) significantly shifts the paradigm of wireless communications. However, the high computation demands, particularly in resource-constrained systems e.g., mobile phones and UAVs, make TOC challenging for many tasks. To address the problem, we propose a novel TOC method with two models: a static and a dynamic model. In the static model, we apply a neural network (NN) as a task-oriented encoder (TOE) when there is no computation budget constraint. The dynamic model is used when device computation resources are limited, and it uses dynamic NNs with multiple exits as the TOE. The dynamic model sorts input data by complexity with thresholds, allowing the efficient allocation of computation resources. Furthermore, we analyze the convergence of the proposed TOC methods and show that the model converges at rate $O\left(\frac{1}{\sqrt{T}}\right)$ with an epoch of length $T$. Experimental results demonstrate that the static model outperforms baseline models in terms of transmitted dimensions, floating-point operations (FLOPs), and accuracy simultaneously. The dynamic model can further improve accuracy and computational demand, providing an improved solution for resource-constrained systems.
Degradation-Aware Feature Perturbation for All-in-One Image Restoration
May 19, 2025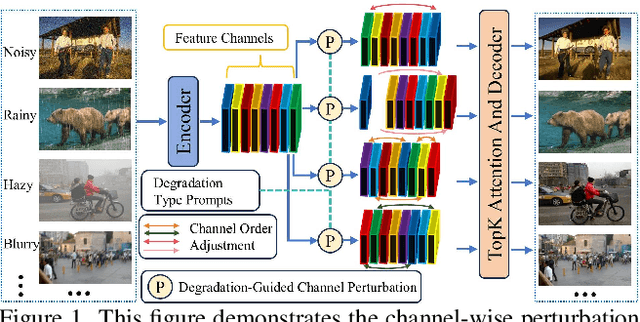
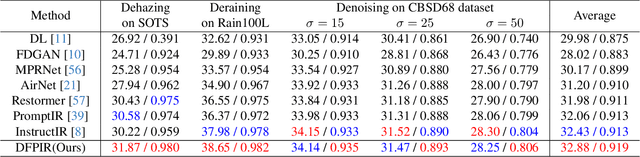
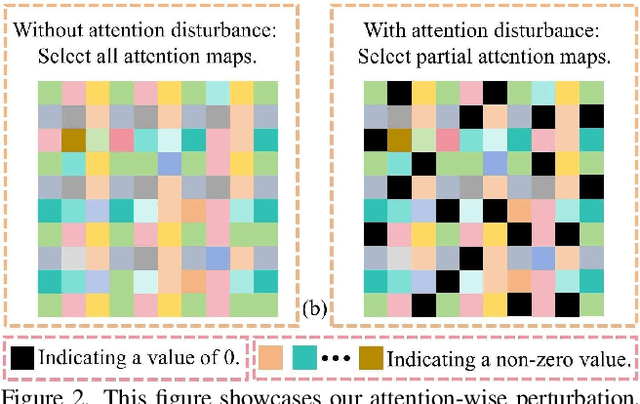
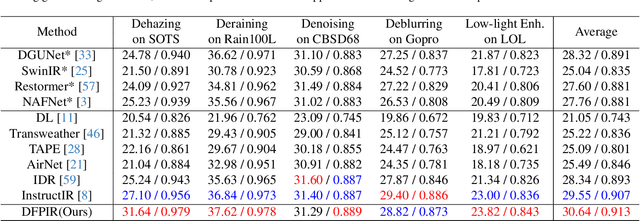
All-in-one image restoration aims to recover clear images from various degradation types and levels with a unified model. Nonetheless, the significant variations among degradation types present challenges for training a universal model, often resulting in task interference, where the gradient update directions of different tasks may diverge due to shared parameters. To address this issue, motivated by the routing strategy, we propose DFPIR, a novel all-in-one image restorer that introduces Degradation-aware Feature Perturbations(DFP) to adjust the feature space to align with the unified parameter space. In this paper, the feature perturbations primarily include channel-wise perturbations and attention-wise perturbations. Specifically, channel-wise perturbations are implemented by shuffling the channels in high-dimensional space guided by degradation types, while attention-wise perturbations are achieved through selective masking in the attention space. To achieve these goals, we propose a Degradation-Guided Perturbation Block (DGPB) to implement these two functions, positioned between the encoding and decoding stages of the encoder-decoder architecture. Extensive experimental results demonstrate that DFPIR achieves state-of-the-art performance on several all-in-one image restoration tasks including image denoising, image dehazing, image deraining, motion deblurring, and low-light image enhancement. Our codes are available at https://github.com/TxpHome/DFPIR.
Heterogeneity-Aware Client Sampling: A Unified Solution for Consistent Federated Learning
May 16, 2025Federated learning (FL) commonly involves clients with diverse communication and computational capabilities. Such heterogeneity can significantly distort the optimization dynamics and lead to objective inconsistency, where the global model converges to an incorrect stationary point potentially far from the pursued optimum. Despite its critical impact, the joint effect of communication and computation heterogeneity has remained largely unexplored, due to the intrinsic complexity of their interaction. In this paper, we reveal the fundamentally distinct mechanisms through which heterogeneous communication and computation drive inconsistency in FL. To the best of our knowledge, this is the first unified theoretical analysis of general heterogeneous FL, offering a principled understanding of how these two forms of heterogeneity jointly distort the optimization trajectory under arbitrary choices of local solvers. Motivated by these insights, we propose Federated Heterogeneity-Aware Client Sampling, FedACS, a universal method to eliminate all types of objective inconsistency. We theoretically prove that FedACS converges to the correct optimum at a rate of $O(1/\sqrt{R})$, even in dynamic heterogeneous environments. Extensive experiments across multiple datasets show that FedACS outperforms state-of-the-art and category-specific baselines by 4.3%-36%, while reducing communication costs by 22%-89% and computation loads by 14%-105%, respectively.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.