 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComAgent: Multi-LLM based Agentic AI Empowered Intelligent Wireless Networks
Jan 27, 2026Emerging 6G networks rely on complex cross-layer optimization, yet manually translating high-level intents into mathematical formulations remains a bottleneck. While Large Language Models (LLMs) offer promise, monolithic approaches often lack sufficient domain grounding, constraint awareness, and verification capabilities. To address this, we present ComAgent, a multi-LLM agentic AI framework. ComAgent employs a closed-loop Perception-Planning-Action-Reflection cycle, coordinating specialized agents for literature search, coding, and scoring to autonomously generate solver-ready formulations and reproducible simulations. By iteratively decomposing problems and self-correcting errors, the framework effectively bridges the gap between user intent and execution. Evaluations demonstrate that ComAgent achieves expert-comparable performance in complex beamforming optimization and outperforms monolithic LLMs across diverse wireless tasks, highlighting its potential for automating design in emerging wireless networks.
Coding-Enforced Resilient and Secure Aggregation for Hierarchical Federated Learning
Jan 25, 2026Hierarchical federated learning (HFL) has emerged as an effective paradigm to enhance link quality between clients and the server. However, ensuring model accuracy while preserving privacy under unreliable communication remains a key challenge in HFL, as the coordination among privacy noise can be randomly disrupted. To address this limitation, we propose a robust hierarchical secure aggregation scheme, termed H-SecCoGC, which integrates coding strategies to enforce structured aggregation. The proposed scheme not only ensures accurate global model construction under varying levels of privacy, but also avoids the partial participation issue, thereby significantly improving robustness, privacy preservation, and learning efficiency. Both theoretical analyses and experimental results demonstrate the superiority of our scheme under unreliable communication across arbitrarily strong privacy guarantees
Land-then-transport: A Flow Matching-Based Generative Decoder for Wireless Image Transmission
Jan 12, 2026Due to strict rate and reliability demands, wireless image transmission remains difficult for both classical layered designs and joint source-channel coding (JSCC), especially under low latency. Diffusion-based generative decoders can deliver strong perceptual quality by leveraging learned image priors, but iterative stochastic denoising leads to high decoding delay. To enable low-latency decoding, we propose a flow-matching (FM) generative decoder under a new land-then-transport (LTT) paradigm that tightly integrates the physical wireless channel into a continuous-time probability flow. For AWGN channels, we build a Gaussian smoothing path whose noise schedule indexes effective noise levels, and derive a closed-form teacher velocity field along this path. A neural-network student vector field is trained by conditional flow matching, yielding a deterministic, channel-aware ODE decoder with complexity linear in the number of ODE steps. At inference, it only needs an estimate of the effective noise variance to set the ODE starting time. We further show that Rayleigh fading and MIMO channels can be mapped, via linear MMSE equalization and singular-value-domain processing, to AWGN-equivalent channels with calibrated starting times. Therefore, the same probability path and trained velocity field can be reused for Rayleigh and MIMO without retraining. Experiments on MNIST, Fashion-MNIST, and DIV2K over AWGN, Rayleigh, and MIMO demonstrate consistent gains over JPEG2000+LDPC, DeepJSCC, and diffusion-based baselines, while achieving good perceptual quality with only a few ODE steps. Overall, LTT provides a deterministic, physically interpretable, and computation-efficient framework for generative wireless image decoding across diverse channels.
Robust Multi-modal Task-oriented Communications with Redundancy-aware Representations
Nov 10, 2025Semantic communications for multi-modal data can transmit task-relevant information efficiently over noisy and bandwidth-limited channels. However, a key challenge is to simultaneously compress inter-modal redundancy and improve semantic reliability under channel distortion. To address the challenge, we propose a robust and efficient multi-modal task-oriented communication framework that integrates a two-stage variational information bottleneck (VIB) with mutual information (MI) redundancy minimization. In the first stage, we apply uni-modal VIB to compress each modality separately, i.e., text, audio, and video, while preserving task-specific features. To enhance efficiency, an MI minimization module with adversarial training is then used to suppress cross-modal dependencies and to promote complementarity rather than redundancy. In the second stage, a multi-modal VIB is further used to compress the fused representation and to enhance robustness against channel distortion. Experimental results on multi-modal emotion recognition tasks demonstrate that the proposed framework significantly outperforms existing baselines in accuracy and reliability, particularly under low signal-to-noise ratio regimes. Our work provides a principled framework that jointly optimizes modality-specific compression, inter-modal redundancy, and communication reliability.
Trajectory-adaptive Beam Shaping: Towards Beam-Management-Free Near-field Communications
Aug 12, 2025The quest for higher wireless carrier frequencies spanning the millimeter-wave (mmWave) and Terahertz (THz) bands heralds substantial enhancements in data throughput and spectral efficiency for next-generation wireless networks. However, these gains come at the cost of severe path loss and a heightened risk of beam misalignment due to user mobility, especially pronounced in near-field communication. Traditional solutions rely on extremely directional beamforming and frequent beam updates via beam management, but such techniques impose formidable computational and signaling overhead. In response, we propose a novel approach termed trajectory-adaptive beam shaping (TABS) that eliminates the need for real-time beam management by shaping the electromagnetic wavefront to follow the user's predefined trajectory. Drawing inspiration from self-accelerating beams in optics, TABS concentrates energy along pre-defined curved paths corresponding to the user's motion without requiring real-time beam reconfiguration. We further introduce a dedicated quantitative metric to characterize performance under the TABS framework. Comprehensive simulations substantiate the superiority of TABS in terms of link performance, overhead reduction, and implementation complexity.
Computation-resource-efficient Task-oriented Communications
Jul 10, 2025The rapid development of deep-learning enabled task-oriented communications (TOC) significantly shifts the paradigm of wireless communications. However, the high computation demands, particularly in resource-constrained systems e.g., mobile phones and UAVs, make TOC challenging for many tasks. To address the problem, we propose a novel TOC method with two models: a static and a dynamic model. In the static model, we apply a neural network (NN) as a task-oriented encoder (TOE) when there is no computation budget constraint. The dynamic model is used when device computation resources are limited, and it uses dynamic NNs with multiple exits as the TOE. The dynamic model sorts input data by complexity with thresholds, allowing the efficient allocation of computation resources. Furthermore, we analyze the convergence of the proposed TOC methods and show that the model converges at rate $O\left(\frac{1}{\sqrt{T}}\right)$ with an epoch of length $T$. Experimental results demonstrate that the static model outperforms baseline models in terms of transmitted dimensions, floating-point operations (FLOPs), and accuracy simultaneously. The dynamic model can further improve accuracy and computational demand, providing an improved solution for resource-constrained systems.
A Matrix Variational Auto-Encoder for Variant Effect Prediction in Pharmacogenes
Jul 03, 2025Variant effect predictors (VEPs) aim to assess the functional impact of protein variants, traditionally relying on multiple sequence alignments (MSAs). This approach assumes that naturally occurring variants are fit, an assumption challenged by pharmacogenomics, where some pharmacogenes experience low evolutionary pressure. Deep mutational scanning (DMS) datasets provide an alternative by offering quantitative fitness scores for variants. In this work, we propose a transformer-based matrix variational auto-encoder (matVAE) with a structured prior and evaluate its performance on 33 DMS datasets corresponding to 26 drug target and ADME proteins from the ProteinGym benchmark. Our model trained on MSAs (matVAE-MSA) outperforms the state-of-the-art DeepSequence model in zero-shot prediction on DMS datasets, despite using an order of magnitude fewer parameters and requiring less computation at inference time. We also compare matVAE-MSA to matENC-DMS, a model of similar capacity trained on DMS data, and find that the latter performs better on supervised prediction tasks. Additionally, incorporating AlphaFold-generated structures into our transformer model further improves performance, achieving results comparable to DeepSequence trained on MSAs and finetuned on DMS. These findings highlight the potential of DMS datasets to replace MSAs without significant loss in predictive performance, motivating further development of DMS datasets and exploration of their relationships to enhance variant effect prediction.
Semantic Communications in 6G: Coexistence, Multiple Access, and Satellite Networks
Jun 13, 2025The exponential growth of wireless users and bandwidth constraints necessitates innovative communication paradigms for next-generation networks. Semantic Communication (SemCom) emerges as a promising solution by transmitting extracted meaning rather than raw bits, enhancing spectral efficiency and enabling intelligent resource allocation. This paper explores the integration of SemCom with conventional Bit-based Communication (BitCom) in heterogeneous networks, highlighting key challenges and opportunities. We analyze multiple access techniques, including Non-Orthogonal Multiple Access (NOMA), to support coexisting SemCom and BitCom users. Furthermore, we examine multi-modal SemCom frameworks for handling diverse data types and discuss their applications in satellite networks, where semantic techniques mitigate bandwidth limitations and harsh channel conditions. Finally, we identify future directions for deploying semantic-aware systems in 6G and beyond.
MIMO Pinching-Antenna-Aided SWIPT
Jun 07, 2025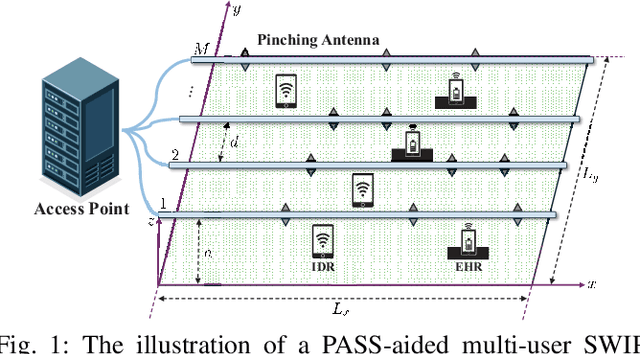
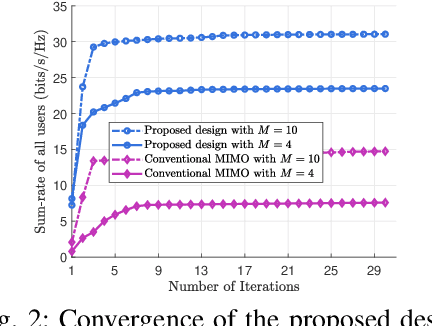
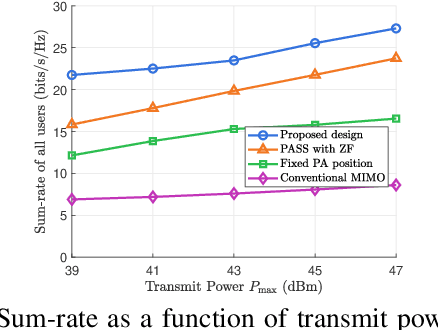
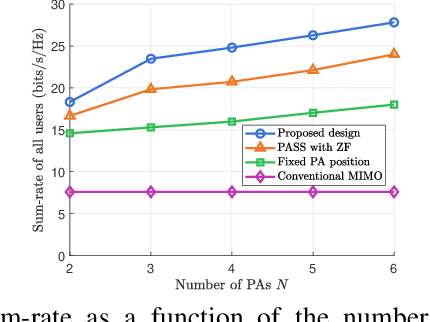
Pinching-antenna systems (PASS) have recently emerged as a promising technology for improving wireless communications by establishing or strengthening reliable line-of-sight (LoS) links by adjusting the positions of pinching antennas (PAs). Motivated by these benefits, we propose a novel PASS-aided multi-input multi-output (MIMO) system for simultaneous wireless information and power transfer (SWIPT), where the PASS are equipped with multiple waveguides to provide information transmission and wireless power transfer (WPT) for several multiple antenna information decoding receivers (IDRs), and energy harvesting receivers (EHRs), respectively. Based on the system, we consider maximizing the sum-rate of all IDRs while guaranteeing the minimum harvested energy of each EHR by jointly optimizing the pinching beamforming and the PA positions. To solve this highly non-convex problem, we iteratively optimize the pinching beamforming based on a weighted minimum mean-squared-error (WMMSE) method and update the PA positions with a Gauss-Seidel-based approach in an alternating optimization (AO) framework. Numerical results verify the significant superiority of the PASS compared with conventional designs.
Joint User Association and Beamforming Design for ISAC Networks with Large Language Models
Jun 05, 2025Integrated sensing and communication (ISAC) has been envisioned to play a more important role in future wireless networks. However, the design of ISAC networks is challenging, especially when there are multiple communication and sensing (C\&S) nodes and multiple sensing targets. We investigate a multi-base station (BS) ISAC network in which multiple BSs equipped with multiple antennas simultaneously provide C\&S services for multiple ground communication users (CUs) and targets. To enhance the overall performance of C\&S, we formulate a joint user association (UA) and multi-BS transmit beamforming optimization problem with the objective of maximizing the total sum rate of all CUs while ensuring both the minimum target detection and parameter estimation requirements. To efficiently solve the highly non-convex mixed integer nonlinear programming (MINLP) optimization problem, we propose an alternating optimization (AO)-based algorithm that decomposes the problem into two sub-problems, i.e., UA optimization and multi-BS transmit beamforming optimization. Inspired by large language models (LLMs) for prediction and inference, we propose a unified framework integrating LLMs with convex-based optimization methods. First, we propose a comprehensive design of prompt engineering, including few-shot, chain of thought, and self-reflection techniques to guide LLMs in solving the binary integer programming UA optimization problem. Second, we utilize convex-based optimization methods to handle the non-convex beamforming optimization problem based on fractional programming (FP), majorization minimization (MM), and the alternating direction method of multipliers (ADMM) with an optimized UA from LLMs. Numerical results demonstrate that our proposed LLM-enabled AO-based algorithm achieves fast convergence and near upper-bound performance with the GPT-o1 model, outperforming various benchmark schemes.