 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Matrix Variational Auto-Encoder for Variant Effect Prediction in Pharmacogenes
Jul 03, 2025Variant effect predictors (VEPs) aim to assess the functional impact of protein variants, traditionally relying on multiple sequence alignments (MSAs). This approach assumes that naturally occurring variants are fit, an assumption challenged by pharmacogenomics, where some pharmacogenes experience low evolutionary pressure. Deep mutational scanning (DMS) datasets provide an alternative by offering quantitative fitness scores for variants. In this work, we propose a transformer-based matrix variational auto-encoder (matVAE) with a structured prior and evaluate its performance on 33 DMS datasets corresponding to 26 drug target and ADME proteins from the ProteinGym benchmark. Our model trained on MSAs (matVAE-MSA) outperforms the state-of-the-art DeepSequence model in zero-shot prediction on DMS datasets, despite using an order of magnitude fewer parameters and requiring less computation at inference time. We also compare matVAE-MSA to matENC-DMS, a model of similar capacity trained on DMS data, and find that the latter performs better on supervised prediction tasks. Additionally, incorporating AlphaFold-generated structures into our transformer model further improves performance, achieving results comparable to DeepSequence trained on MSAs and finetuned on DMS. These findings highlight the potential of DMS datasets to replace MSAs without significant loss in predictive performance, motivating further development of DMS datasets and exploration of their relationships to enhance variant effect prediction.
Compressed Sensing of Generative Sparse-latent (GSL) Signals
Oct 16, 2023



We consider reconstruction of an ambient signal in a compressed sensing (CS) setup where the ambient signal has a neural network based generative model. The generative model has a sparse-latent input and we refer to the generated ambient signal as generative sparse-latent signal (GSL). The proposed sparsity inducing reconstruction algorithm is inherently non-convex, and we show that a gradient based search provides a good reconstruction performance. We evaluate our proposed algorithm using simulated data.
DANSE: Data-driven Non-linear State Estimation of Model-free Process in Unsupervised Learning Setup
Jun 04, 2023



We address the tasks of Bayesian state estimation and forecasting for a model-free process in an unsupervised learning setup. In the article, we propose DANSE -- a Data-driven Nonlinear State Estimation method. DANSE provides a closed-form posterior of the state of the model-free process, given linear measurements of the state. In addition, it provides a closed-form posterior for forecasting. A data-driven recurrent neural network (RNN) is used in DANSE to provide the parameters of a prior of the state. The prior depends on the past measurements as input, and then we find the closed-form posterior of the state using the current measurement as input. The data-driven RNN captures the underlying non-linear dynamics of the model-free process. The training of DANSE, mainly learning the parameters of the RNN, is executed using an unsupervised learning approach. In unsupervised learning, we have access to a training dataset comprising only a set of measurement data trajectories, but we do not have any access to the state trajectories. Therefore, DANSE does not have access to state information in the training data and can not use supervised learning. Using simulated linear and non-linear process models (Lorenz attractor and Chen attractor), we evaluate the unsupervised learning-based DANSE. We show that the proposed DANSE, without knowledge of the process model and without supervised learning, provides a competitive performance against model-driven methods, such as the Kalman filter (KF), extended KF (EKF), unscented KF (UKF), and a recently proposed hybrid method called KalmanNet.
Normalizing Flow based Hidden Markov Models for Classification of Speech Phones with Explainability
Jul 01, 2021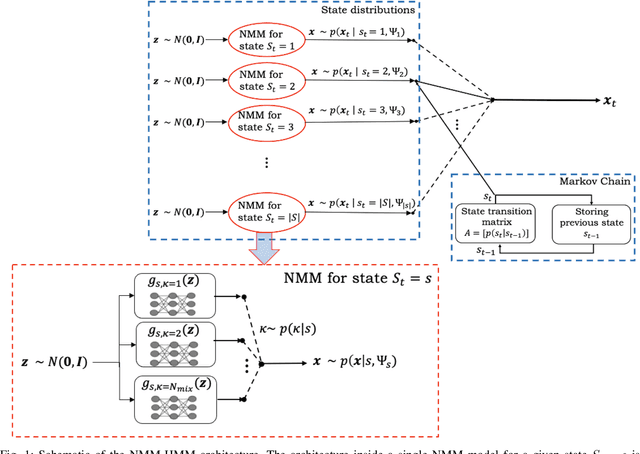
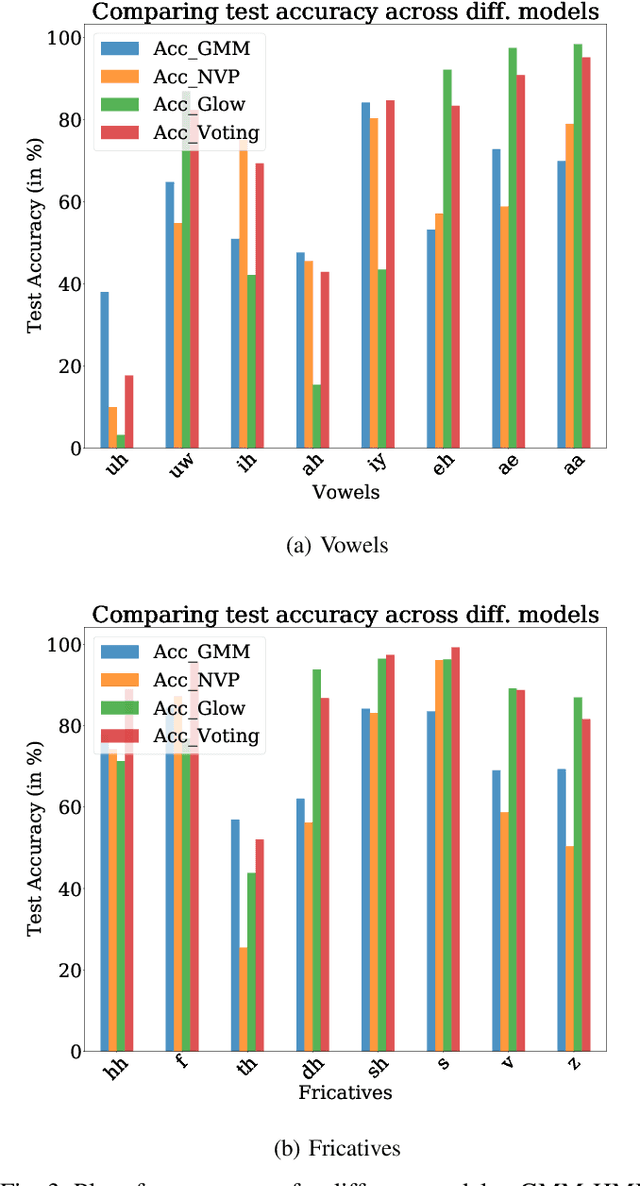

In pursuit of explainability, we develop generative models for sequential data. The proposed models provide state-of-the-art classification results and robust performance for speech phone classification. We combine modern neural networks (normalizing flows) and traditional generative models (hidden Markov models - HMMs). Normalizing flow-based mixture models (NMMs) are used to model the conditional probability distribution given the hidden state in the HMMs. Model parameters are learned through judicious combinations of time-tested Bayesian learning methods and contemporary neural network learning methods. We mainly combine expectation-maximization (EM) and mini-batch gradient descent. The proposed generative models can compute likelihood of a data and hence directly suitable for maximum-likelihood (ML) classification approach. Due to structural flexibility of HMMs, we can use different normalizing flow models. This leads to different types of HMMs providing diversity in data modeling capacity. The diversity provides an opportunity for easy decision fusion from different models. For a standard speech phone classification setup involving 39 phones (classes) and the TIMIT dataset, we show that the use of standard features called mel-frequency-cepstral-coeffcients (MFCCs), the proposed generative models, and the decision fusion together can achieve $86.6\%$ accuracy by generative training only. This result is close to state-of-the-art results, for examples, $86.2\%$ accuracy of PyTorch-Kaldi toolkit [1], and $85.1\%$ accuracy using light gated recurrent units [2]. We do not use any discriminative learning approach and related sophisticated features in this article.
Robust Classification using Hidden Markov Models and Mixtures of Normalizing Flows
Feb 15, 2021


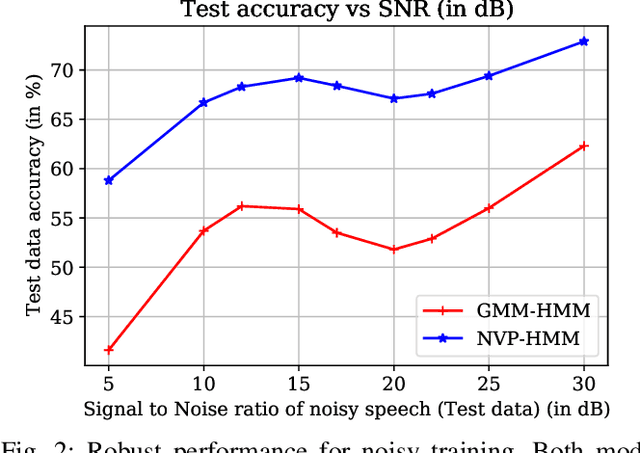
We test the robustness of a maximum-likelihood (ML) based classifier where sequential data as observation is corrupted by noise. The hypothesis is that a generative model, that combines the state transitions of a hidden Markov model (HMM) and the neural network based probability distributions for the hidden states of the HMM, can provide a robust classification performance. The combined model is called normalizing-flow mixture model based HMM (NMM-HMM). It can be trained using a combination of expectation-maximization (EM) and backpropagation. We verify the improved robustness of NMM-HMM classifiers in an application to speech recognition.
Powering Hidden Markov Model by Neural Network based Generative Models
Oct 13, 2019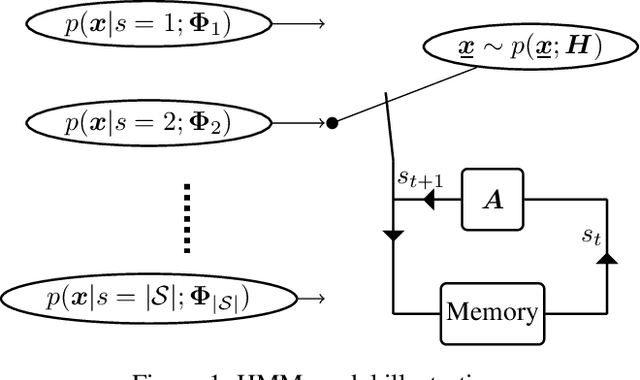
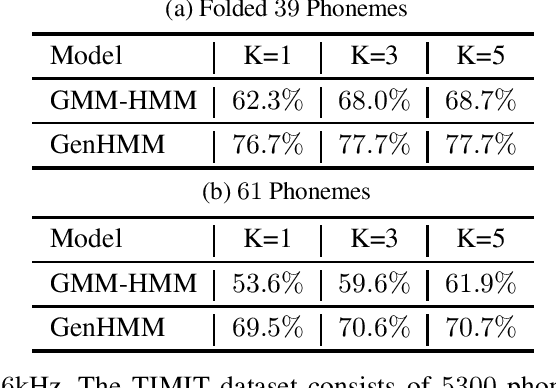
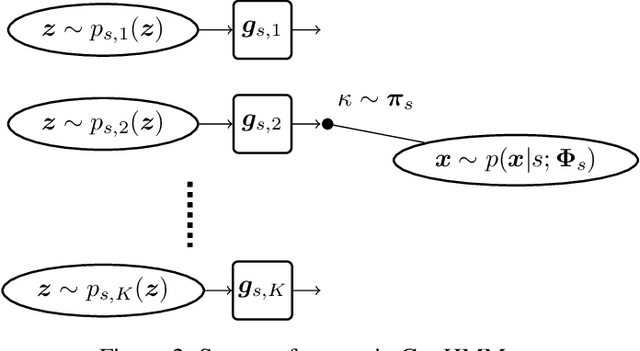
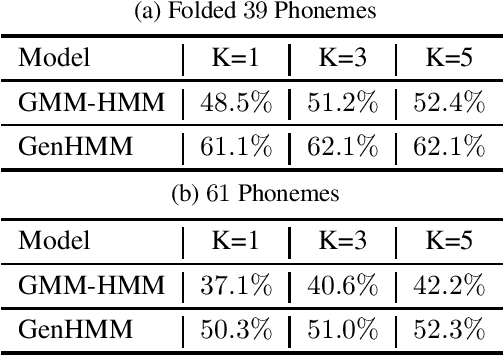
Hidden Markov model (HMM) has been successfully used for sequential data modeling problems. In this work, we propose to power the modeling capacity of HMM by bringing in neural network based generative models. The proposed model is termed as GenHMM. In the proposed GenHMM, each HMM hidden state is associated with a neural network based generative model that has tractability of exact likelihood and provides efficient likelihood computation. A generative model in GenHMM consists of mixture of generators that are realized by flow models. A learning algorithm for GenHMM is proposed in expectation-maximization framework. The convergence of the learning GenHMM is analyzed. We demonstrate the efficiency of GenHMM by classification tasks on practical sequential data.
Large Neural Network Based Detection of Apnea, Bradycardia and Desaturation Events
Nov 17, 2017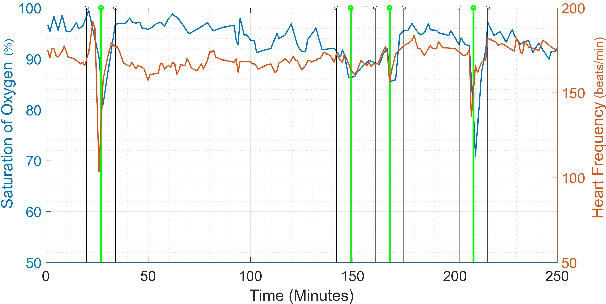

Apnea, bradycardia and desaturation (ABD) events often precede life-threatening events including sepsis in newborn babies. Here, we explore machine learning for detection of ABD events as a binary classification problem. We investigate the use of a large neural network to achieve a good detection performance. To be user friendly, the chosen neural network does not require a high level of parameter tuning. Furthermore, a limited amount of training data is available and the training dataset is unbalanced. Comparing with two widely used state-of-the-art machine learning algorithms, the large neural network is found to be efficient. Even with a limited and unbalanced training data, the large neural network provides a detection performance level that is feasible to use in clinical care.
* Accepted for NIPS Workshop ML4H, 2017