 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSE: Variational state estimation of complex model-free process
Jan 29, 2026We design a variational state estimation (VSE) method that provides a closed-form Gaussian posterior of an underlying complex dynamical process from (noisy) nonlinear measurements. The complex process is model-free. That is, we do not have a suitable physics-based model characterizing the temporal evolution of the process state. The closed-form Gaussian posterior is provided by a recurrent neural network (RNN). The use of RNN is computationally simple in the inference phase. For learning the RNN, an additional RNN is used in the learning phase. Both RNNs help each other learn better based on variational inference principles. The VSE is demonstrated for a tracking application - state estimation of a stochastic Lorenz system (a benchmark process) using a 2-D camera measurement model. The VSE is shown to be competitive against a particle filter that knows the Lorenz system model and a recently proposed data-driven state estimation method that does not know the Lorenz system model.
pDANSE: Particle-based Data-driven Nonlinear State Estimation from Nonlinear Measurements
Oct 31, 2025We consider the problem of designing a data-driven nonlinear state estimation (DANSE) method that uses (noisy) nonlinear measurements of a process whose underlying state transition model (STM) is unknown. Such a process is referred to as a model-free process. A recurrent neural network (RNN) provides parameters of a Gaussian prior that characterize the state of the model-free process, using all previous measurements at a given time point. In the case of DANSE, the measurement system was linear, leading to a closed-form solution for the state posterior. However, the presence of a nonlinear measurement system renders a closed-form solution infeasible. Instead, the second-order statistics of the state posterior are computed using the nonlinear measurements observed at the time point. We address the nonlinear measurements using a reparameterization trick-based particle sampling approach, and estimate the second-order statistics of the state posterior. The proposed method is referred to as particle-based DANSE (pDANSE). The RNN of pDANSE uses sequential measurements efficiently and avoids the use of computationally intensive sequential Monte-Carlo (SMC) and/or ancestral sampling. We describe the semi-supervised learning method for pDANSE, which transitions to unsupervised learning in the absence of labeled data. Using a stochastic Lorenz-$63$ system as a benchmark process, we experimentally demonstrate the state estimation performance for four nonlinear measurement systems. We explore cubic nonlinearity and a camera-model nonlinearity where unsupervised learning is used; then we explore half-wave rectification nonlinearity and Cartesian-to-spherical nonlinearity where semi-supervised learning is used. The performance of state estimation is shown to be competitive vis-\`a-vis particle filters that have complete knowledge of the STM of the Lorenz-$63$ system.
Leveraging LLMs for Scalable Non-intrusive Speech Quality Assessment
Aug 08, 2025Non-intrusive speech quality assessment (SQA) systems suffer from limited training data and costly human annotations, hindering their generalization to real-time conferencing calls. In this work, we propose leveraging large language models (LLMs) as pseudo-raters for speech quality to address these data bottlenecks. We construct LibriAugmented, a dataset consisting of 101,129 speech clips with simulated degradations labeled by a fine-tuned auditory LLM (Vicuna-7b-v1.5). We compare three training strategies: using human-labeled data, using LLM-labeled data, and a two-stage approach (pretraining on LLM labels, then fine-tuning on human labels), using both DNSMOS Pro and DeePMOS. We test on several datasets across languages and quality degradations. While LLM-labeled training yields mixed results compared to human-labeled training, we provide empirical evidence that the two-stage approach improves the generalization performance (e.g., DNSMOS Pro achieves 0.63 vs. 0.55 PCC on NISQA_TEST_LIVETALK and 0.73 vs. 0.65 PCC on Tencent with reverb). Our findings demonstrate the potential of using LLMs as scalable pseudo-raters for speech quality assessment, offering a cost-effective solution to the data limitation problem.
AI-Aided Kalman Filters
Oct 16, 2024



The Kalman filter (KF) and its variants are among the most celebrated algorithms in signal processing. These methods are used for state estimation of dynamic systems by relying on mathematical representations in the form of simple state-space (SS) models, which may be crude and inaccurate descriptions of the underlying dynamics. Emerging data-centric artificial intelligence (AI) techniques tackle these tasks using deep neural networks (DNNs), which are model-agnostic. Recent developments illustrate the possibility of fusing DNNs with classic Kalman-type filtering, obtaining systems that learn to track in partially known dynamics. This article provides a tutorial-style overview of design approaches for incorporating AI in aiding KF-type algorithms. We review both generic and dedicated DNN architectures suitable for state estimation, and provide a systematic presentation of techniques for fusing AI tools with KFs and for leveraging partial SS modeling and data, categorizing design approaches into task-oriented and SS model-oriented. The usefulness of each approach in preserving the individual strengths of model-based KFs and data-driven DNNs is investigated in a qualitative and quantitative study, whose code is publicly available, illustrating the gains of hybrid model-based/data-driven designs. We also discuss existing challenges and future research directions that arise from fusing AI and Kalman-type algorithms.
Data-driven Bayesian State Estimation with Compressed Measurement of Model-free Process using Semi-supervised Learning
Jul 10, 2024



The research topic is: data-driven Bayesian state estimation with compressed measurement (BSCM) of model-free process, say for a (causal) tracking application. The dimension of the temporal measurement vector is lower than the dimension of the temporal state vector to be estimated. Hence the state estimation problem is an underdetermined inverse problem. The state-space-model (SSM) of the underlying dynamical process is assumed to be unknown and hence, we use the terminology 'model-free process'. In absence of the SSM, we can not employ traditional model-driven methods like Kalman Filter (KF) and Particle Filter (PF) and instead require data-driven methods. We first experimentally show that two existing unsupervised learning-based data-driven methods fail to address the BSCM problem for model-free process; they are data-driven nonlinear state estimation (DANSE) method and deep Markov model (DMM) method. The unsupervised learning uses unlabelled data comprised of only noisy measurements. While DANSE provides a good predictive performance to model the temporal measurement data as time-series, its unsupervised learning lacks a regularization for state estimation. We then investigate use of a semi-supervised learning approach, and develop a semi-supervised learning-based DANSE method, referred to as SemiDANSE. In the semi-supervised learning, we use a limited amount of labelled data along-with a large amount of unlabelled data, and that helps to bring the desired regularization for BSCM problem in the absence of SSM. The labelled data means pairwise measurement-and-state data. Using three chaotic dynamical systems (or processes) with nonlinear SSMs as benchmark, we show that the data-driven SemiDANSE provides competitive performance for BSCM against three SSM-informed methods - a hybrid method called KalmanNet, and two traditional model-driven methods called extended KF and unscented KF.
Compressed Sensing of Generative Sparse-latent (GSL) Signals
Oct 16, 2023



We consider reconstruction of an ambient signal in a compressed sensing (CS) setup where the ambient signal has a neural network based generative model. The generative model has a sparse-latent input and we refer to the generated ambient signal as generative sparse-latent signal (GSL). The proposed sparsity inducing reconstruction algorithm is inherently non-convex, and we show that a gradient based search provides a good reconstruction performance. We evaluate our proposed algorithm using simulated data.
DANSE: Data-driven Non-linear State Estimation of Model-free Process in Unsupervised Learning Setup
Jun 04, 2023



We address the tasks of Bayesian state estimation and forecasting for a model-free process in an unsupervised learning setup. In the article, we propose DANSE -- a Data-driven Nonlinear State Estimation method. DANSE provides a closed-form posterior of the state of the model-free process, given linear measurements of the state. In addition, it provides a closed-form posterior for forecasting. A data-driven recurrent neural network (RNN) is used in DANSE to provide the parameters of a prior of the state. The prior depends on the past measurements as input, and then we find the closed-form posterior of the state using the current measurement as input. The data-driven RNN captures the underlying non-linear dynamics of the model-free process. The training of DANSE, mainly learning the parameters of the RNN, is executed using an unsupervised learning approach. In unsupervised learning, we have access to a training dataset comprising only a set of measurement data trajectories, but we do not have any access to the state trajectories. Therefore, DANSE does not have access to state information in the training data and can not use supervised learning. Using simulated linear and non-linear process models (Lorenz attractor and Chen attractor), we evaluate the unsupervised learning-based DANSE. We show that the proposed DANSE, without knowledge of the process model and without supervised learning, provides a competitive performance against model-driven methods, such as the Kalman filter (KF), extended KF (EKF), unscented KF (UKF), and a recently proposed hybrid method called KalmanNet.
DeepBayes -- an estimator for parameter estimation in stochastic nonlinear dynamical models
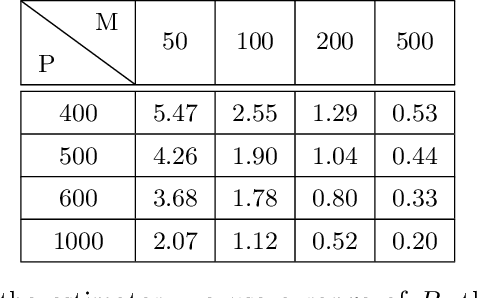
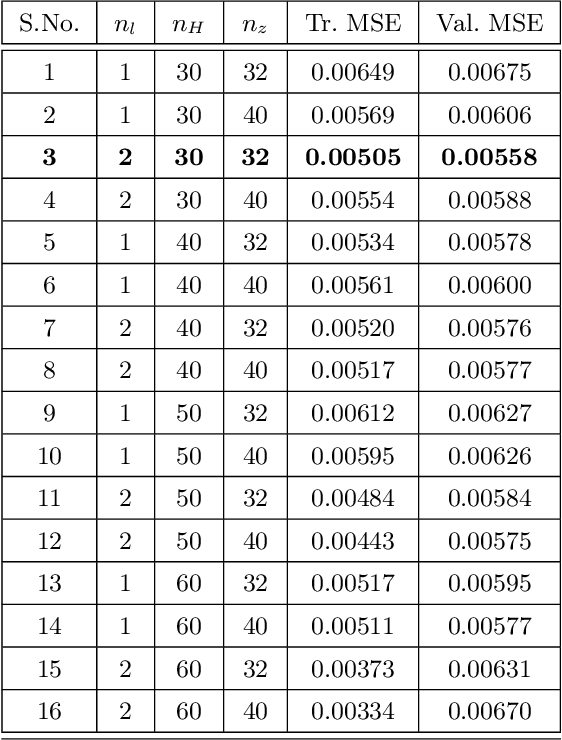
May 04, 2022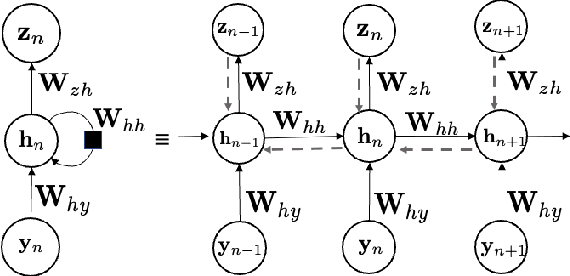

Stochastic nonlinear dynamical systems are ubiquitous in modern, real-world applications. Yet, estimating the unknown parameters of stochastic, nonlinear dynamical models remains a challenging problem. The majority of existing methods employ maximum likelihood or Bayesian estimation. However, these methods suffer from some limitations, most notably the substantial computational time for inference coupled with limited flexibility in application. In this work, we propose DeepBayes estimators that leverage the power of deep recurrent neural networks in learning an estimator. The method consists of first training a recurrent neural network to minimize the mean-squared estimation error over a set of synthetically generated data using models drawn from the model set of interest. The a priori trained estimator can then be used directly for inference by evaluating the network with the estimation data. The deep recurrent neural network architectures can be trained offline and ensure significant time savings during inference. We experiment with two popular recurrent neural networks -- long short term memory network (LSTM) and gated recurrent unit (GRU). We demonstrate the applicability of our proposed method on different example models and perform detailed comparisons with state-of-the-art approaches. We also provide a study on a real-world nonlinear benchmark problem. The experimental evaluations show that the proposed approach is asymptotically as good as the Bayes estimator.
Normalizing Flow based Hidden Markov Models for Classification of Speech Phones with Explainability
Jul 01, 2021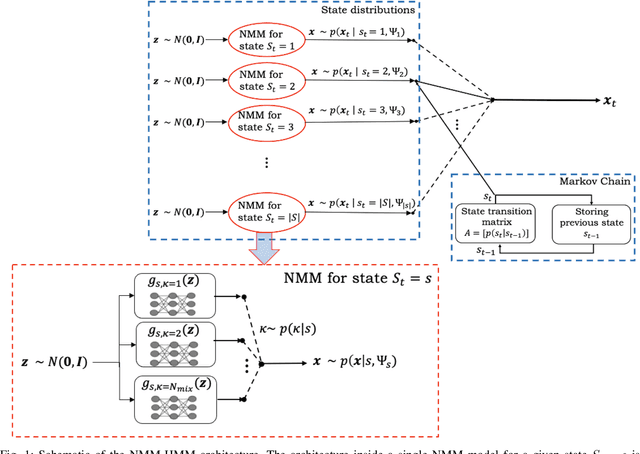
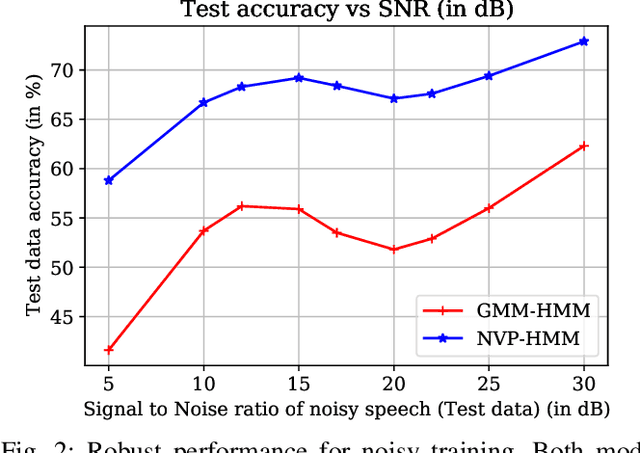
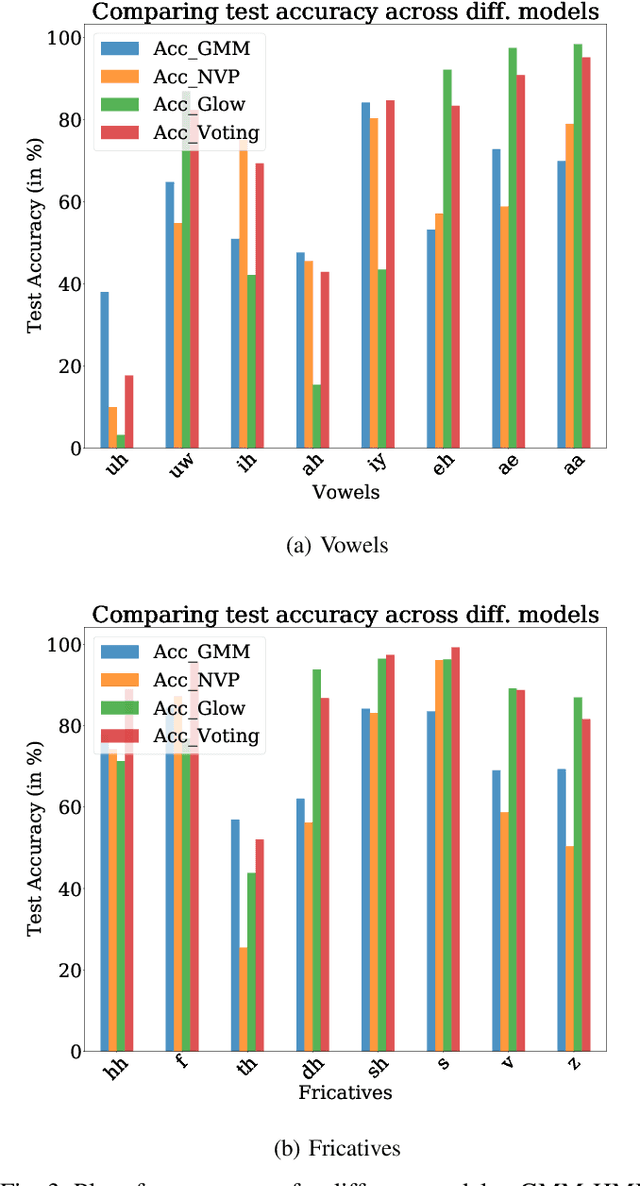

In pursuit of explainability, we develop generative models for sequential data. The proposed models provide state-of-the-art classification results and robust performance for speech phone classification. We combine modern neural networks (normalizing flows) and traditional generative models (hidden Markov models - HMMs). Normalizing flow-based mixture models (NMMs) are used to model the conditional probability distribution given the hidden state in the HMMs. Model parameters are learned through judicious combinations of time-tested Bayesian learning methods and contemporary neural network learning methods. We mainly combine expectation-maximization (EM) and mini-batch gradient descent. The proposed generative models can compute likelihood of a data and hence directly suitable for maximum-likelihood (ML) classification approach. Due to structural flexibility of HMMs, we can use different normalizing flow models. This leads to different types of HMMs providing diversity in data modeling capacity. The diversity provides an opportunity for easy decision fusion from different models. For a standard speech phone classification setup involving 39 phones (classes) and the TIMIT dataset, we show that the use of standard features called mel-frequency-cepstral-coeffcients (MFCCs), the proposed generative models, and the decision fusion together can achieve $86.6\%$ accuracy by generative training only. This result is close to state-of-the-art results, for examples, $86.2\%$ accuracy of PyTorch-Kaldi toolkit [1], and $85.1\%$ accuracy using light gated recurrent units [2]. We do not use any discriminative learning approach and related sophisticated features in this article.
Robust Classification using Hidden Markov Models and Mixtures of Normalizing Flows
Feb 15, 2021


We test the robustness of a maximum-likelihood (ML) based classifier where sequential data as observation is corrupted by noise. The hypothesis is that a generative model, that combines the state transitions of a hidden Markov model (HMM) and the neural network based probability distributions for the hidden states of the HMM, can provide a robust classification performance. The combined model is called normalizing-flow mixture model based HMM (NMM-HMM). It can be trained using a combination of expectation-maximization (EM) and backpropagation. We verify the improved robustness of NMM-HMM classifiers in an application to speech recognition.