 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Flow based Hidden Markov Models for Classification of Speech Phones with Explainability
Paper and Code
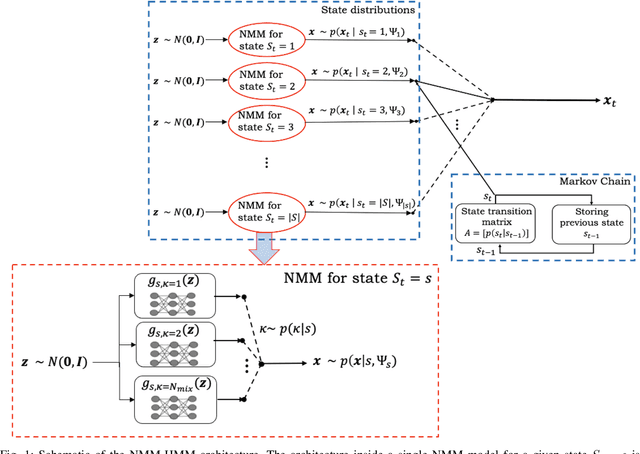
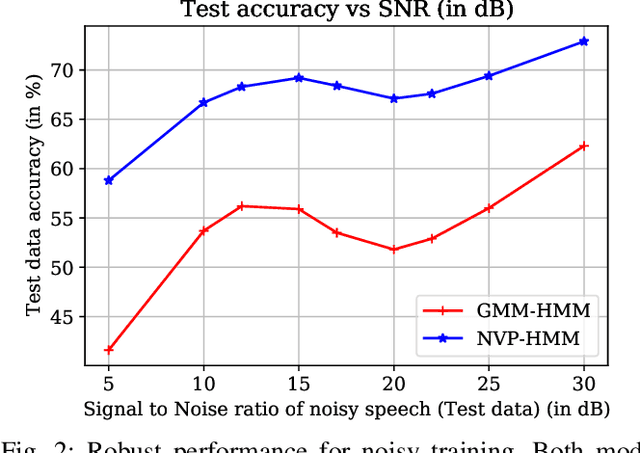
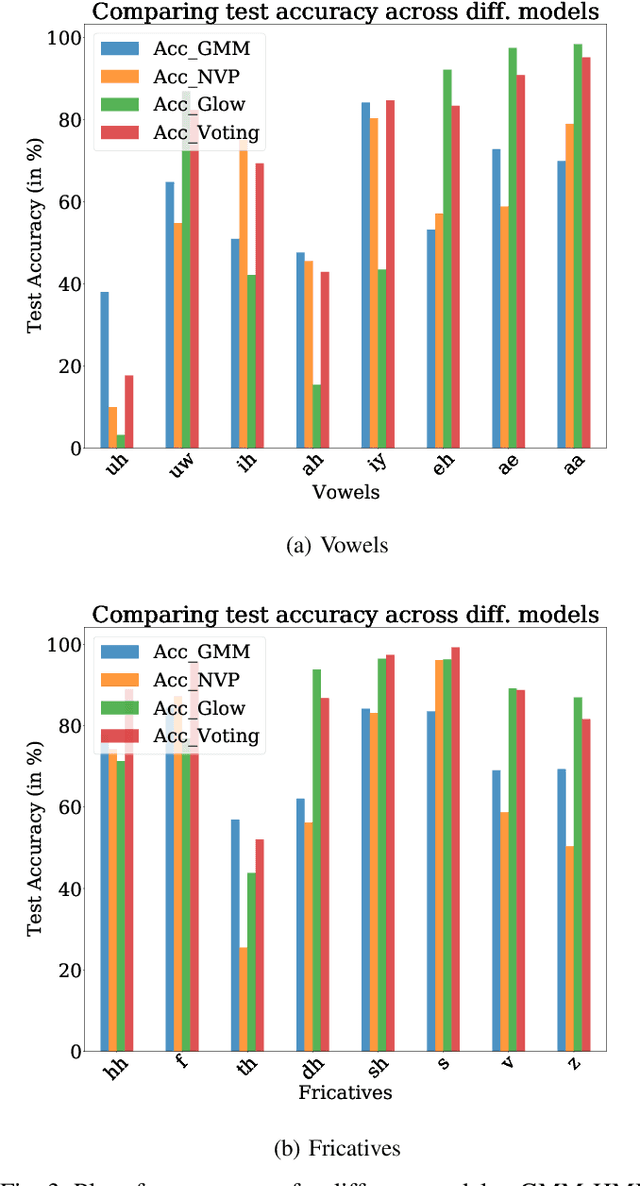

In pursuit of explainability, we develop generative models for sequential data. The proposed models provide state-of-the-art classification results and robust performance for speech phone classification. We combine modern neural networks (normalizing flows) and traditional generative models (hidden Markov models - HMMs). Normalizing flow-based mixture models (NMMs) are used to model the conditional probability distribution given the hidden state in the HMMs. Model parameters are learned through judicious combinations of time-tested Bayesian learning methods and contemporary neural network learning methods. We mainly combine expectation-maximization (EM) and mini-batch gradient descent. The proposed generative models can compute likelihood of a data and hence directly suitable for maximum-likelihood (ML) classification approach. Due to structural flexibility of HMMs, we can use different normalizing flow models. This leads to different types of HMMs providing diversity in data modeling capacity. The diversity provides an opportunity for easy decision fusion from different models. For a standard speech phone classification setup involving 39 phones (classes) and the TIMIT dataset, we show that the use of standard features called mel-frequency-cepstral-coeffcients (MFCCs), the proposed generative models, and the decision fusion together can achieve $86.6\%$ accuracy by generative training only. This result is close to state-of-the-art results, for examples, $86.2\%$ accuracy of PyTorch-Kaldi toolkit [1], and $85.1\%$ accuracy using light gated recurrent units [2]. We do not use any discriminative learning approach and related sophisticated features in this article.