 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Multitasking: A Unified Framework for Discovering Generalizable Solutions to PDE Families
Feb 12, 2026Solving Partial Differential Equations (PDEs) is fundamental to numerous scientific and engineering disciplines. A common challenge arises from solving the PDE families, which are characterized by sharing an identical mathematical structure but varying in specific parameters. Traditional numerical methods, such as the finite element method, need to independently solve each instance within a PDE family, which incurs massive computational cost. On the other hand, while recent advancements in machine learning PDE solvers offer impressive computational speed and accuracy, their inherent ``black-box" nature presents a considerable limitation. These methods primarily yield numerical approximations, thereby lacking the crucial interpretability provided by analytical expressions, which are essential for deeper scientific insight. To address these limitations, we propose a neuro-assisted multitasking symbolic PDE solver framework for PDE family solving, dubbed NMIPS. In particular, we employ multifactorial optimization to simultaneously discover the analytical solutions of PDEs. To enhance computational efficiency, we devise an affine transfer method by transferring learned mathematical structures among PDEs in a family, avoiding solving each PDE from scratch. Experimental results across multiple cases demonstrate promising improvements over existing baselines, achieving up to a $\sim$35.7% increase in accuracy while providing interpretable analytical solutions.
PEGNet: A Physics-Embedded Graph Network for Long-Term Stable Multiphysics Simulation
Nov 11, 2025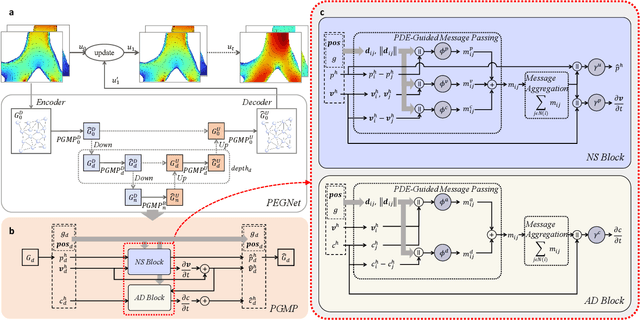
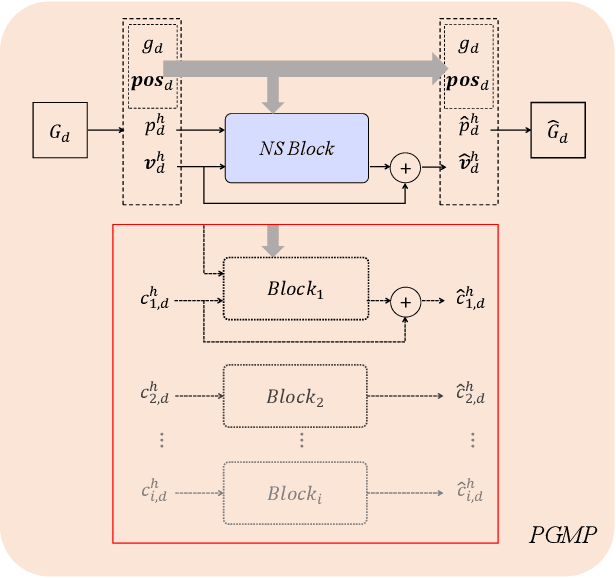
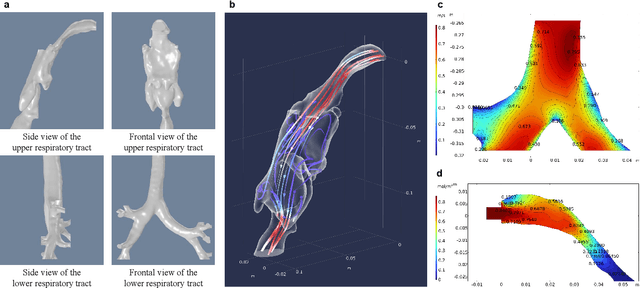
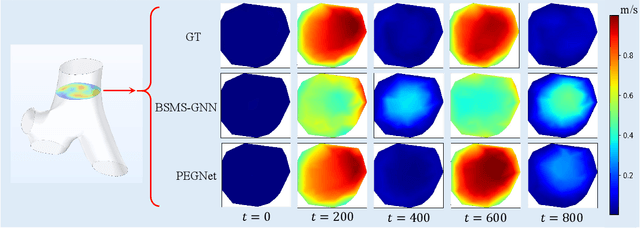
Accurate and efficient simulations of physical phenomena governed by partial differential equations (PDEs) are important for scientific and engineering progress. While traditional numerical solvers are powerful, they are often computationally expensive. Recently, data-driven methods have emerged as alternatives, but they frequently suffer from error accumulation and limited physical consistency, especially in multiphysics and complex geometries. To address these challenges, we propose PEGNet, a Physics-Embedded Graph Network that incorporates PDE-guided message passing to redesign the graph neural network architecture. By embedding key PDE dynamics like convection, viscosity, and diffusion into distinct message functions, the model naturally integrates physical constraints into its forward propagation, producing more stable and physically consistent solutions. Additionally, a hierarchical architecture is employed to capture multi-scale features, and physical regularization is integrated into the loss function to further enforce adherence to governing physics. We evaluated PEGNet on benchmarks, including custom datasets for respiratory airflow and drug delivery, showing significant improvements in long-term prediction accuracy and physical consistency over existing methods. Our code is available at https://github.com/Yanghuoshan/PEGNet.
Cross-Field Interface-Aware Neural Operators for Multiphase Flow Simulation
Nov 09, 2025Multiphase flow systems, with their complex dynamics, field discontinuities, and interphase interactions, pose significant computational challenges for traditional numerical solvers. While neural operators offer efficient alternatives, they often struggle to achieve high-resolution numerical accuracy in these systems. This limitation primarily stems from the inherent spatial heterogeneity and the scarcity of high-quality training data in multiphase flows. In this work, we propose the Interface Information-Aware Neural Operator (IANO), a novel framework that explicitly leverages interface information as a physical prior to enhance the prediction accuracy. The IANO architecture introduces two key components: 1) An interface-aware multiple function encoding mechanism jointly models multiple physical fields and interfaces, thus capturing the high-frequency physical features at the interface. 2) A geometry-aware positional encoding mechanism further establishes the relationship between interface information, physical variables, and spatial positions, enabling it to achieve pointwise super-resolution prediction even in the low-data regimes. Experimental results demonstrate that IANO outperforms baselines by $\sim$10\% in accuracy for multiphase flow simulations while maintaining robustness under data-scarce and noise-perturbed conditions.
Fading the Digital Ink: A Universal Black-Box Attack Framework for 3DGS Watermarking Systems
Aug 10, 2025With the rise of 3D Gaussian Splatting (3DGS), a variety of digital watermarking techniques, embedding either 1D bitstreams or 2D images, are used for copyright protection. However, the robustness of these watermarking techniques against potential attacks remains underexplored. This paper introduces the first universal black-box attack framework, the Group-based Multi-objective Evolutionary Attack (GMEA), designed to challenge these watermarking systems. We formulate the attack as a large-scale multi-objective optimization problem, balancing watermark removal with visual quality. In a black-box setting, we introduce an indirect objective function that blinds the watermark detector by minimizing the standard deviation of features extracted by a convolutional network, thus rendering the feature maps uninformative. To manage the vast search space of 3DGS models, we employ a group-based optimization strategy to partition the model into multiple, independent sub-optimization problems. Experiments demonstrate that our framework effectively removes both 1D and 2D watermarks from mainstream 3DGS watermarking methods while maintaining high visual fidelity. This work reveals critical vulnerabilities in existing 3DGS copyright protection schemes and calls for the development of more robust watermarking systems.
ACSNet: A Deep Neural Network for Compound GNSS Jamming Signal Classification
Apr 15, 2025



In the global navigation satellite system (GNSS), identifying not only single but also compound jamming signals is crucial for ensuring reliable navigation and positioning, particularly in future wireless communication scenarios such as the space-air-ground integrated network (SAGIN). However, conventional techniques often struggle with low recognition accuracy and high computational complexity, especially under low jamming-to-noise ratio (JNR) conditions. To overcome the challenge of accurately identifying compound jamming signals embedded within GNSS signals, we propose ACSNet, a novel convolutional neural network designed specifically for this purpose. Unlike traditional methods that tend to exhibit lower accuracy and higher computational demands, particularly in low JNR environments, ACSNet addresses these issues by integrating asymmetric convolution blocks, which enhance its sensitivity to subtle signal variations. Simulations demonstrate that ACSNet significantly improves accuracy in low JNR regions and shows robust resilience to power ratio (PR) variations, confirming its effectiveness and efficiency for practical GNSS interference management applications.
Automating Adjudication of Cardiovascular Events Using Large Language Models
Mar 21, 2025Cardiovascular events, such as heart attacks and strokes, remain a leading cause of mortality globally, necessitating meticulous monitoring and adjudication in clinical trials. This process, traditionally performed manually by clinical experts, is time-consuming, resource-intensive, and prone to inter-reviewer variability, potentially introducing bias and hindering trial progress. This study addresses these critical limitations by presenting a novel framework for automating the adjudication of cardiovascular events in clinical trials using Large Language Models (LLMs). We developed a two-stage approach: first, employing an LLM-based pipeline for event information extraction from unstructured clinical data and second, using an LLM-based adjudication process guided by a Tree of Thoughts approach and clinical endpoint committee (CEC) guidelines. Using cardiovascular event-specific clinical trial data, the framework achieved an F1-score of 0.82 for event extraction and an accuracy of 0.68 for adjudication. Furthermore, we introduce the CLEART score, a novel, automated metric specifically designed for evaluating the quality of AI-generated clinical reasoning in adjudicating cardiovascular events. This approach demonstrates significant potential for substantially reducing adjudication time and costs while maintaining high-quality, consistent, and auditable outcomes in clinical trials. The reduced variability and enhanced standardization also allow for faster identification and mitigation of risks associated with cardiovascular therapies.
Enhancing Large-scale UAV Route Planing with Global and Local Features via Reinforcement Graph Fusion
Dec 20, 2024Numerous remarkable advancements have been made in accuracy, speed, and parallelism for solving the Unmanned Aerial Vehicle Route Planing (UAVRP). However, existing UAVRP solvers face challenges when attempting to scale effectively and efficiently for larger instances. In this paper, we present a generalization framework that enables current UAVRP solvers to robustly extend their capabilities to larger instances, accommodating up to 10,000 points, using widely recognized test sets. The UAVRP under a large number of patrol points is a typical large-scale TSP problem.Our proposed framework comprises three distinct steps. Firstly, we employ Delaunay triangulation to extract subgraphs from large instances while preserving global features. Secondly, we utilize an embedded TSP solver to obtain sub-results, followed by graph fusion. Finally, we implement a decoding strategy customizable to the user's requirements, resulting in high-quality solutions, complemented by a warming-up process for the heatmap. To demonstrate the flexibility of our approach, we integrate two representative TSP solvers into our framework and conduct a comprehensive comparative analysis against existing algorithms using large TSP benchmark datasets. The results unequivocally demonstrate that our framework efficiently scales existing TSP solvers to handle large instances and consistently outperforms state-of-the-art (SOTA) methods. Furthermore, since our proposed framework does not necessitate additional training or fine-tuning, we believe that its generality can significantly advance research on end-to-end UAVRP solvers, enabling the application of a broader range of methods to real-world scenarios.
NexusSplats: Efficient 3D Gaussian Splatting in the Wild
Nov 26, 2024While 3D Gaussian Splatting (3DGS) has recently demonstrated remarkable rendering quality and efficiency in 3D scene reconstruction, it struggles with varying lighting conditions and incidental occlusions in real-world scenarios. To accommodate varying lighting conditions, existing 3DGS extensions apply color mapping to the massive Gaussian primitives with individually optimized appearance embeddings. To handle occlusions, they predict pixel-wise uncertainties via 2D image features for occlusion capture. Nevertheless, such massive color mapping and pixel-wise uncertainty prediction strategies suffer from not only additional computational costs but also coarse-grained lighting and occlusion handling. In this work, we propose a nexus kernel-driven approach, termed NexusSplats, for efficient and finer 3D scene reconstruction under complex lighting and occlusion conditions. In particular, NexusSplats leverages a novel light decoupling strategy where appearance embeddings are optimized based on nexus kernels instead of massive Gaussian primitives, thus accelerating reconstruction speeds while ensuring local color consistency for finer textures. Additionally, a Gaussian-wise uncertainty mechanism is developed, aligning 3D structures with 2D image features for fine-grained occlusion handling. Experimental results demonstrate that NexusSplats achieves state-of-the-art rendering quality while reducing reconstruction time by up to 70.4% compared to the current best in quality.
GMFlow: Global Motion-Guided Recurrent Flow for 6D Object Pose Estimation
Nov 26, 2024



6D object pose estimation is crucial for robotic perception and precise manipulation. Occlusion and incomplete object visibility are common challenges in this task, but existing pose refinement methods often struggle to handle these issues effectively. To tackle this problem, we propose a global motion-guided recurrent flow estimation method called GMFlow for pose estimation. GMFlow overcomes local ambiguities caused by occlusion or missing parts by seeking global explanations. We leverage the object's structural information to extend the motion of visible parts of the rigid body to its invisible regions. Specifically, we capture global contextual information through a linear attention mechanism and guide local motion information to generate global motion estimates. Furthermore, we introduce object shape constraints in the flow iteration process, making flow estimation suitable for pose estimation scenarios. Experiments on the LM-O and YCB-V datasets demonstrate that our method outperforms existing techniques in accuracy while maintaining competitive computational efficiency.
Phys4DGen: A Physics-Driven Framework for Controllable and Efficient 4D Content Generation from a Single Image
Nov 25, 2024
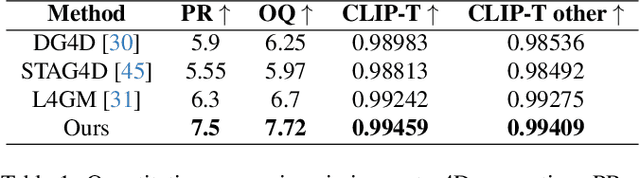
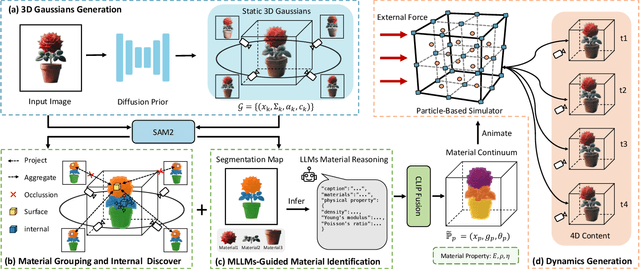
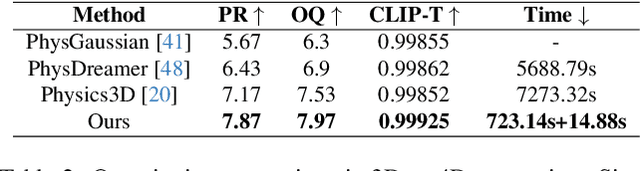
The task of 4D content generation involves creating dynamic 3D models that evolve over time in response to specific input conditions, such as images. Existing methods rely heavily on pre-trained video diffusion models to guide 4D content dynamics, but these approaches often fail to capture essential physical principles, as video diffusion models lack a robust understanding of real-world physics. Moreover, these models face challenges in providing fine-grained control over dynamics and exhibit high computational costs. In this work, we propose Phys4DGen, a novel, high-efficiency framework that generates physics-compliant 4D content from a single image with enhanced control capabilities. Our approach uniquely integrates physical simulations into the 4D generation pipeline, ensuring adherence to fundamental physical laws. Inspired by the human ability to infer physical properties visually, we introduce a Physical Perception Module (PPM) that discerns the material properties and structural components of the 3D object from the input image, facilitating accurate downstream simulations. Phys4DGen significantly accelerates the 4D generation process by eliminating iterative optimization steps in the dynamics modeling phase. It allows users to intuitively control the movement speed and direction of generated 4D content by adjusting external forces, achieving finely tunable, physically plausible animations. Extensive evaluations show that Phys4DGen outperforms existing methods in both inference speed and physical realism, producing high-quality, controllable 4D content.